reflexion
1.0.0
此存储库包含用于reflexion的代码、演示和日志文件:Noah Shinn、Federico Cassano、Edward Berman、Ashwin Gopinath、Karthik Narasimhan、Shunyu Yao 的语言代理与言语强化学习。
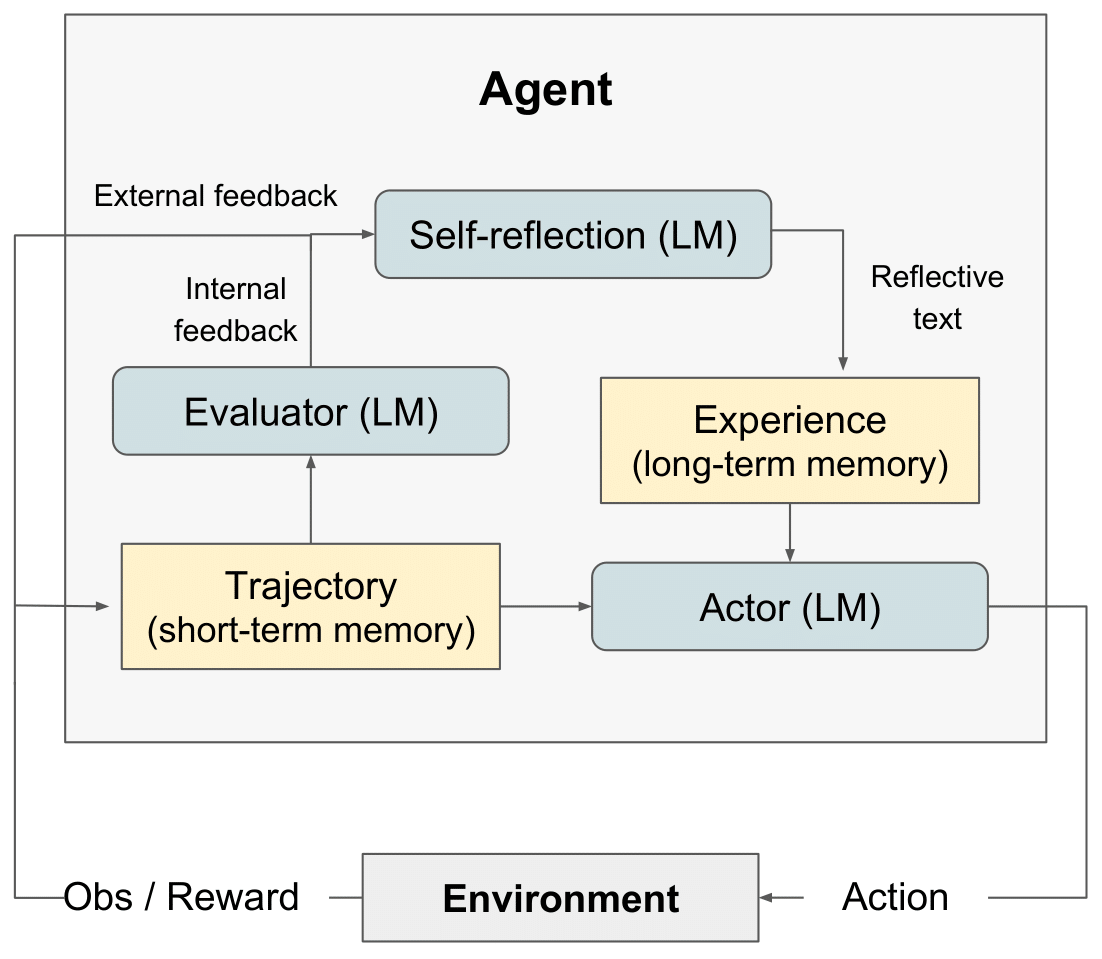 反射 RL 图" style="max-width: 100%;">
反射 RL 图" style="max-width: 100%;">
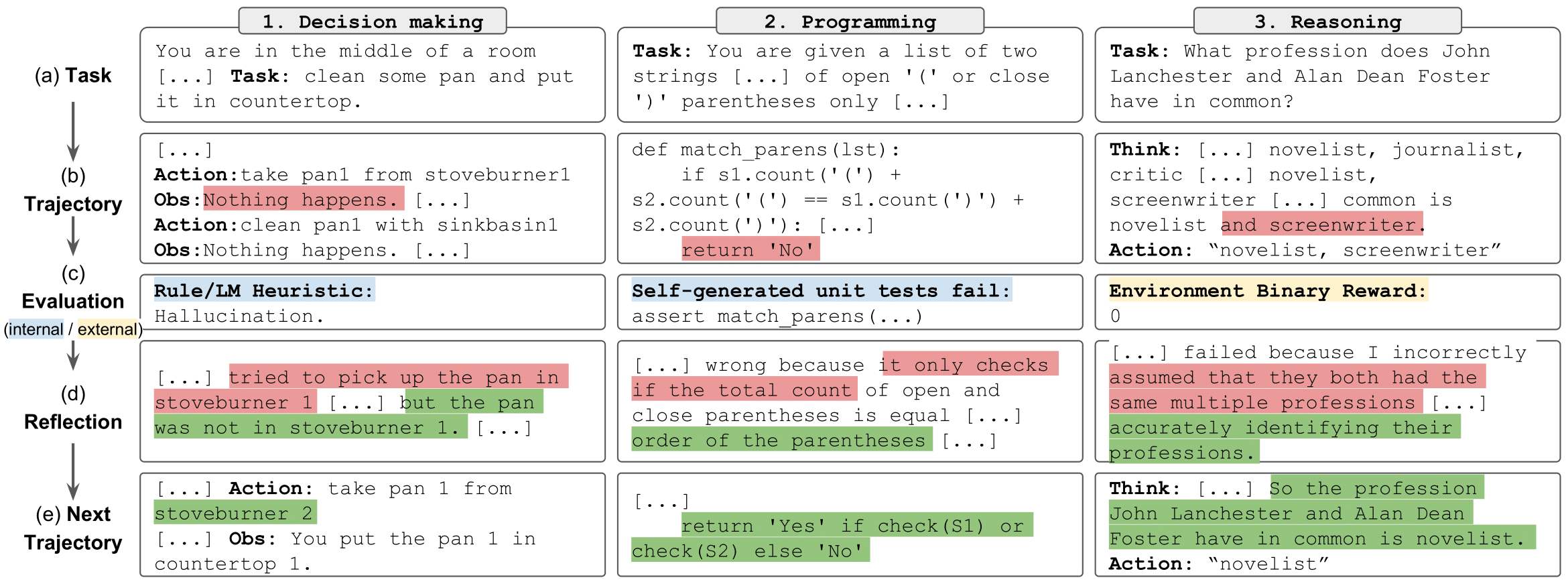 反射任务" style="max-width: 100%;">
反射任务" style="max-width: 100%;">
我们在这里发布了LeetcodeHardGym
我们提供了一组笔记本,可以轻松运行、探索推理实验结果并与之交互。每个实验都包含来自 HotPotQA 干扰数据集的 100 个问题的随机样本。示例中的每个问题均由具有特定类型和reflexion策略的代理尝试。
开始使用:
git clone https://github.com/noahshinn/reflexion && cd ./hotpotqa_runspip install -r requirements.txtOPENAI_API_KEY环境变量设置为您的 OpenAI API 密钥: export OPENAI_API_KEY= < your key > 代理类型由您选择运行的笔记本决定。可用的代理类型包括:
ReAct - 反应代理
CoT_context - CoT 代理给出有关问题的支持上下文
CoT_no_context - CoT 代理没有给出有关问题的支持上下文
每种代理类型的笔记本位于./hotpot_runs/notebooks目录中。
每个笔记本都允许您指定代理要使用的reflexion策略。可用的reflexion策略在Enum中定义,包括:
reflexion Strategy.NONE - 代理不会获得有关其上次尝试的任何信息。
reflexion Strategy.LAST_ATTEMPT - 代理从其对问题的最后一次尝试中获得推理轨迹作为上下文。
reflexion Strategy. reflexion - 代理对最后一次尝试进行自我反思作为上下文。
reflexion Strategy.LAST_ATTEMPT_AND_ reflexion - 代理会获得其推理轨迹和最后一次尝试的自我反思作为上下文。
克隆此存储库并移动到 AlfWorld 目录
git clone https://github.com/noahshinn/reflexion && cd ./alfworld_runs在./run_ reflexion .sh中指定运行参数。 num_trials :迭代学习步骤数num_envs :每次试验的任务环境对数run_name :本次运行的名称use_memory :使用持久内存来存储自我反思(关闭以运行基线运行) is_resume :使用日志记录目录来恢复先前的运行resume_dir :从中恢复先前运行的日志记录目录start_trial_num :如果恢复运行,则要启动的试验编号
运行试验
./run_ reflexion .sh日志将发送到./root/<run_name> 。
由于这些实验的性质,个人开发者重新运行结果可能不可行,因为 GPT-4 的访问权限有限且 API 费用很高。论文中的所有运行和其他结果都记录在./alfworld_runs/root中用于决策, ./hotpotqa_runs/root中用于推理,以及./programming_runs/root中用于编程
在这里查看原始代码的代码
在这里阅读博客文章
在这里查看一个有趣的类型预测实现:OpenTau
如有任何问题,请联系 [email protected]
@misc { shinn2023 reflexion ,
title = { reflexion : Language Agents with Verbal Reinforcement Learning } ,
author = { Noah Shinn and Federico Cassano and Edward Berman and Ashwin Gopinath and Karthik Narasimhan and Shunyu Yao } ,
year = { 2023 } ,
eprint = { 2303.11366 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.AI }
}

