machine learning experiments
1.0.0
??乌克兰正在遭到俄罗斯军队的攻击。平民正在被杀害。住宅区遭到轰炸。
- 通过以下方式帮助乌克兰:
- 谢尔希·普里图拉慈善基金会
- 活着回来慈善基金会
- 乌克兰国家银行
- 更多信息请访问 war.ukraine.ua 和乌克兰外交部
这是交互式机器学习实验的集合。每个实验都包含 ?️ Jupyter/Colab笔记本(查看模型是如何训练的)和 ?演示页面(在浏览器中查看正在运行的模型)。
您可能还对自制 GPT • JS 感兴趣
️ 该存储库包含机器学习实验,而不是生产就绪、可重用、优化和微调的代码和模型。这更像是一个沙箱或一个用于学习和尝试不同机器学习方法、算法和数据集的游乐场。模型可能表现不佳,并且存在过度拟合/欠拟合的情况。
这些实验中的大多数模型都是使用 Keras 支持的 TensorFlow 2 进行训练的。
监督学习是指当您有输入变量X和输出变量Y时,您使用算法来学习从输入到输出的映射函数: Y = f(X) 。目标是很好地近似映射函数,以便当您有新的输入数据X时,您可以预测该数据的输出变量Y之所以称为监督学习,是因为算法从训练数据集中学习的过程可以被视为监督学习过程的老师。
多层感知器 (MLP) 是一类前馈人工神经网络 (ANN)。多层感知器有时被称为“普通”神经网络(由多层感知器组成),特别是当它们具有单个隐藏层时。它可以区分不可线性分离的数据。
| 实验 | 模型演示和培训 | 标签 | 数据集 | |
|---|---|---|---|---|
 | 手写数字识别 (MLP) | MLP | MNIST | |
 | 手写草图识别 (MLP) | MLP | 快速绘图 |
卷积神经网络(CNN 或 ConvNet)是一类深度神经网络,最常用于分析视觉图像(照片、视频)。它们用于检测和分类照片和视频上的对象、风格迁移、人脸识别、姿势估计等。
| 实验 | 模型演示和培训 | 标签 | 数据集 | |
|---|---|---|---|---|
 | 手写数字识别 (CNN) | CNN | MNIST | |
 | 手写草图识别 (CNN) | CNN | 快速绘图 | |
 | 剪刀石头布 (CNN) | CNN | RPS | |
 | 剪刀石头布(MobilenetV2) | MobileNetV2 , Transfer learning , CNN | 图像网络 | |
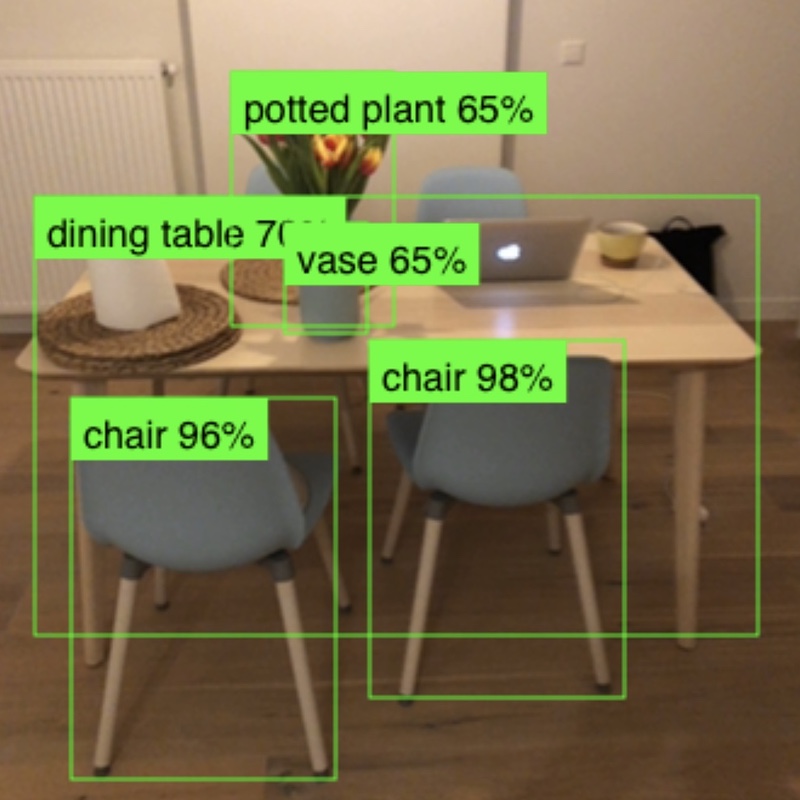 | 物体检测 (MobileNetV2) | MobileNetV2 、 SSDLite 、 CNN | 可可 | |
 | 图像分类(MobileNetV2) | MobileNetV2 CNN | 图像网 |
循环神经网络 (RNN) 是一类深度神经网络,最常应用于基于序列的数据,如语音、语音、文本或音乐。它们用于机器翻译、语音识别、语音合成等。
| 实验 | 模型演示和培训 | 标签 | 数据集 | |
|---|---|---|---|---|
 | 数字求和 (RNN) | LSTM , Sequence-to-sequence | 自动生成 | |
 | 莎士比亚文本生成 (RNN) | LSTM , Character-based RNN | 莎士比亚 | |
 | 维基百科文本生成(RNN) | LSTM , Character-based RNN | 维基百科 | |
 | 配方生成(RNN) | LSTM , Character-based RNN | 食谱盒 |
无监督学习是指只有输入数据X而没有相应的输出变量。无监督学习的目标是对数据的底层结构或分布进行建模,以便更多地了解数据。这些被称为无监督学习,因为与上面的监督学习不同,没有正确答案,也没有老师。算法自行发现并呈现数据中有趣的结构。
生成对抗网络(GAN)是一类机器学习框架,其中两个神经网络在游戏中相互竞争。两个模型通过对抗过程同时训练。例如,生成器(“艺术家”)学习创建看起来真实的图像,而鉴别器(“艺术评论家”)学习区分真实图像和赝品。
| 实验 | 模型演示和培训 | 标签 | 数据集 | |
|---|---|---|---|---|
 | 衣服一代(DCGAN) | DCGAN | 时尚 MNIST |
# Create "experiments" environment (from the project root folder).
python3 -m venv .virtualenvs/experiments
# Activate environment.
source .virtualenvs/experiments/bin/activate
# or if you use Fish...
source .virtualenvs/experiments/bin/activate.fish要退出环境,请运行deactivate 。
# Upgrade pip and setuptools to the latest versions.
pip install --upgrade pip setuptools
# Install packages
pip install -r requirements.txt要安装新软件包,请运行pip install package-name 。要将新包添加到需求中,请运行pip freeze > requirements.txt 。
为了使用 Jupyter Notebook 并查看模型是如何训练的,您需要启动 Jupyter Notebook 服务器。
# Launch Jupyter server.
jupyter notebook Jupyter 将在本地提供http://localhost:8888/ 。带有实验的笔记本可以在experiments文件夹中找到。
演示应用程序是通过 create-react-app 在 React 上制作的。
# Switch to demos folder from project root.
cd demos
# Install all dependencies.
yarn install
# Start demo server on http.
yarn start
# Or start demo server on https (for camera access in browser to work on localhost).
yarn start-https演示将在本地提供http://localhost:3000/或https://localhost:3000/ 。
converter环境用于将实验期间训练的模型从.h5 Keras 格式转换为 Javascript 可理解的格式(带有.json和.bin文件的tfjs_layers_model或tfjs_graph_model格式),以便在演示应用程序中进一步与 TensorFlow.js 一起使用。
# Create "converter" environment (from the project root folder).
python3 -m venv .virtualenvs/converter
# Activate "converter" environment.
source .virtualenvs/converter/bin/activate
# or if you use Fish...
source .virtualenvs/converter/bin/activate.fish
# Install converter requirements.
pip install -r requirements.converter.txt keras模型到tfjs_layers_model / tfjs_graph_model格式的转换是由 tfjs-converter 完成的:
例如:
tensorflowjs_converter --input_format keras
./experiments/digits_recognition_mlp/digits_recognition_mlp.h5
./demos/public/models/digits_recognition_mlp
️ 将模型转换为 JS 可理解的格式并直接将其加载到浏览器可能不是一个好的做法,因为在这种情况下,用户可能需要将数十或数百兆字节的数据加载到浏览器,这效率不高。通常,模型是从后端(即 TensorFlow Extended)提供服务的,用户不会将其全部加载到浏览器,而是会执行轻量级 HTTP 请求来进行预测。但由于演示应用程序只是一个实验,而不是一个可用于生产的应用程序,并且为了简单起见(以避免后端启动和运行),我们将模型转换为 JS 可理解的格式,并将它们直接加载到浏览器。
推荐版本:
> 3.7.3 。>= 12.4.0 。>= 1.13.0 。如果您使用的是 Python 版本3.7.3则在尝试import tensorflow时可能会遇到RuntimeError: dictionary changed size during iteration错误(请参阅问题)。


