LaTeX OCR
1.0.0
该项目的目标是创建一个基于学习的系统,该系统获取数学公式的图像并返回相应的 LaTeX 代码。
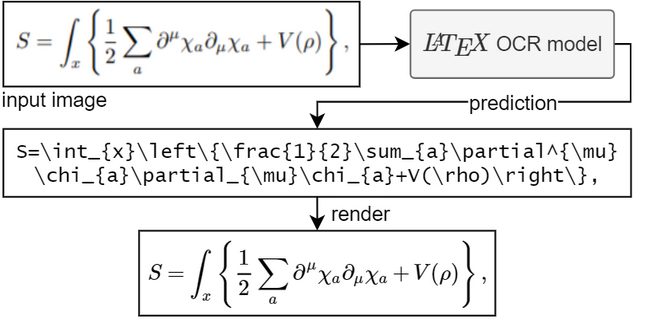
要运行模型,您需要 Python 3.7+
如果您没有安装 PyTorch。请按照此处的说明进行操作。
安装pix2tex软件包:
pip install "pix2tex[gui]"
模型检查点将自动下载。
有三种方法可以从图像中获得预测。
您可以通过调用pix2tex使用命令行工具。在这里您可以解析磁盘中已有的图像和剪贴板中的图像。
感谢@katie-lim,您可以使用漂亮的用户界面作为获得模型预测的快速方法。只需使用latexocr调用 GUI 即可。从这里您可以截取屏幕截图,并使用 MathJax 呈现预测的乳胶代码并将其复制到剪贴板。
在 Linux 下,如果事先安装了gnome-screenshot则可以使用带有gnome-screenshot (支持多显示器)的 GUI。对于 Wayland,当grim和slurp都可用时将使用它们。请注意, gnome-screenshot与基于 wlroots 的 Wayland 合成器不兼容。由于gnome-screenshot在可用时将是首选,因此在这种情况下您可能必须将环境变量SCREENSHOT_TOOL设置为grim (其他可用值是gnome-screenshot和pil )。
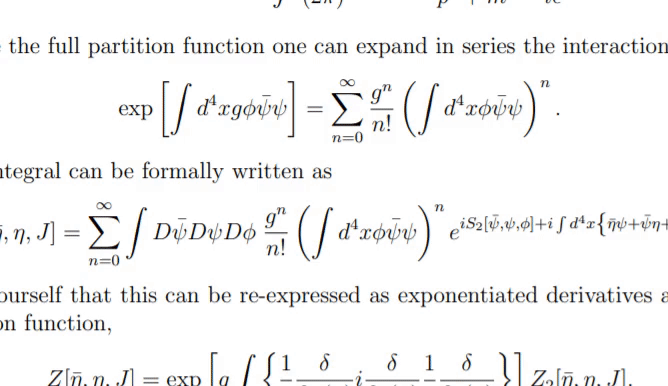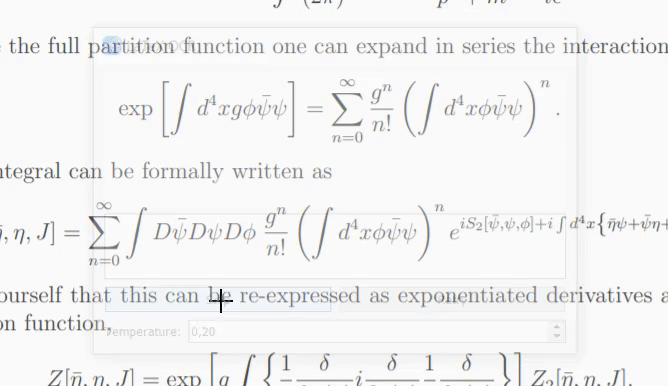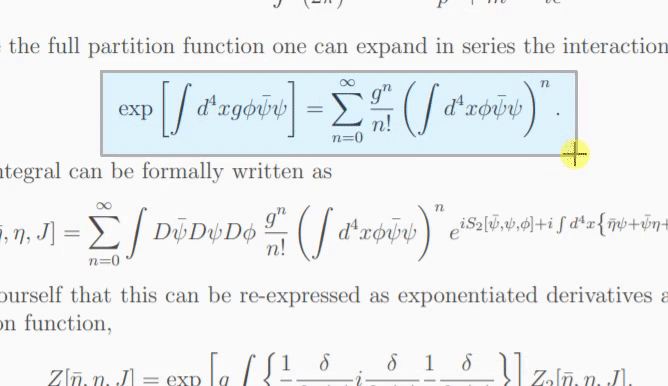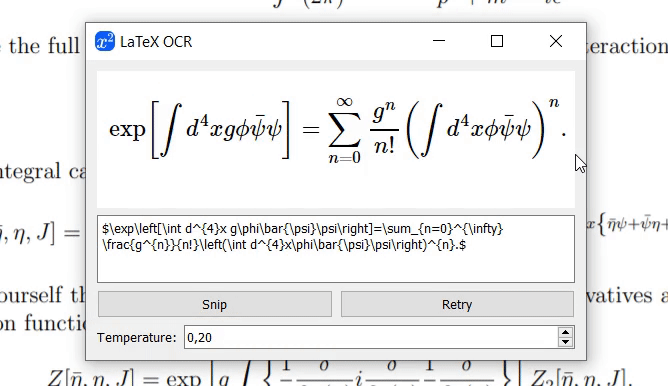
如果模型不确定图像中的内容,则每次单击“重试”时,它可能会输出不同的预测。使用temperature参数,您可以控制这种行为(低温会产生相同的结果)。
您可以使用 API。这有额外的依赖性。通过pip install -U "pix2tex[api]"安装并运行
python -m pix2tex.api.run
启动连接到端口 8502 处的 API 的 Streamlit 演示。还有一个可用于该 API 的 docker 映像:https://hub.docker.com/r/lukasblecher/pix2tex
docker pull lukasblecher/pix2tex:api docker run --rm -p 8502:8502 lukasblecher/pix2tex:api
还要运行streamlit演示运行
docker run --rm -it -p 8501:8501 --entrypoint python lukasblecher/pix2tex:api pix2tex/api/run.py
并导航到 http://localhost:8501/
从 Python 内部使用
from PIL import Imagefrom pix2tex.cli import LatexOCRimg = Image.open('path/to/image.png')model = LatexOCR()print(model(img))该模型最适用于分辨率较小的图像。这就是为什么我添加了一个预处理步骤,其中另一个神经网络预测输入图像的最佳分辨率。该模型将自动调整自定义图像的大小,以最接近训练数据,从而提高在野外发现的图像的性能。但它仍然不完美,可能无法以最佳方式处理大图像,因此在拍照之前不要将其完全放大。
务必仔细检查结果。如果答案错误,您可以尝试使用其他分辨率重新进行预测。
想要使用该包吗?
我现在正在尝试编写文档。
访问此处:https://pix2tex.readthedocs.io/
安装几个依赖项pip install "pix2tex[train]" 。
首先,我们需要将图像与其真实标签结合起来。我编写了一个数据集类(需要进一步改进),它使用渲染图像的 LaTeX 代码保存图像的相对路径。要生成数据集 pickle 文件,请运行
python -m pix2tex.dataset.dataset --equations path_to_textfile --images path_to_images --out dataset.pkl
要使用您自己的标记生成器,请通过--tokenizer传递它(见下文)。
您也可以在 Google Drive 上找到我生成的训练数据(formulae.zip - 图像、math.txt - 标签)。对验证和测试数据重复该步骤。全部使用相同的标签文本文件。
将配置文件中的data (和valdata )条目编辑到新生成的.pkl文件中。如果需要,可以更改其他超参数。请参阅pix2tex/model/settings/config.yaml获取模板。
现在进行实际训练
python -m pix2tex.train --config path_to_config_file
如果您想使用自己的数据,您可能有兴趣创建自己的分词器
python -m pix2tex.dataset.dataset --equations path_to_textfile --vocab-size 8000 --out tokenizer.json
不要忘记更新配置文件中标记生成器的路径并将num_tokens设置为您的词汇量大小。
该模型由具有 ResNet 主干的 ViT [1] 编码器和 Transformer [2] 解码器组成。
| BLEU 分数 | 标准化编辑距离 | 令牌准确度 |
|---|---|---|
| 0.88 | 0.10 | 0.60 |
我们需要配对数据供网络学习。幸运的是,互联网上有很多 LaTeX 代码,例如 wikipedia、arXiv。我们还使用 im2latex-100k [3] 数据集中的公式。所有这些都可以在这里找到
为了以多种不同的字体呈现数学,我们使用 XeLaTeX,生成 PDF 并最终将其转换为 PNG。对于最后一步,我们需要使用一些第三方工具:
XeLaTeX
ImageMagick 与 Ghostscript。 (用于将 pdf 转换为 png)
Node.js 运行 KaTeX(用于标准化 Latex 代码)
Python 3.7+ 和依赖项(在setup.py中指定)
拉丁现代数学、GFSNeohellenicMath.otf、Asana 数学、XITS 数学、Cambria 数学
添加更多评估指标
创建一个图形用户界面
添加波束搜索
支持手写公式(有点完成,请参阅训练 colab 笔记本)
缩小模型尺寸(蒸馏)
找到最佳超参数
调整模型结构
修复数据抓取并抓取更多数据
追踪模型 (#2)
欢迎任何形式的贡献。
代码取自 lucidrains、rwightman、im2markup、arxiv_leaks、pkra:Mathjax、harupy:截图工具并进行修改
[1] 一张图片胜过 16x16 个单词
[2] 注意力就是你所需要的
[3] 具有粗到细注意力的图像到标记生成


