obfuscated gradients
v1.0.0
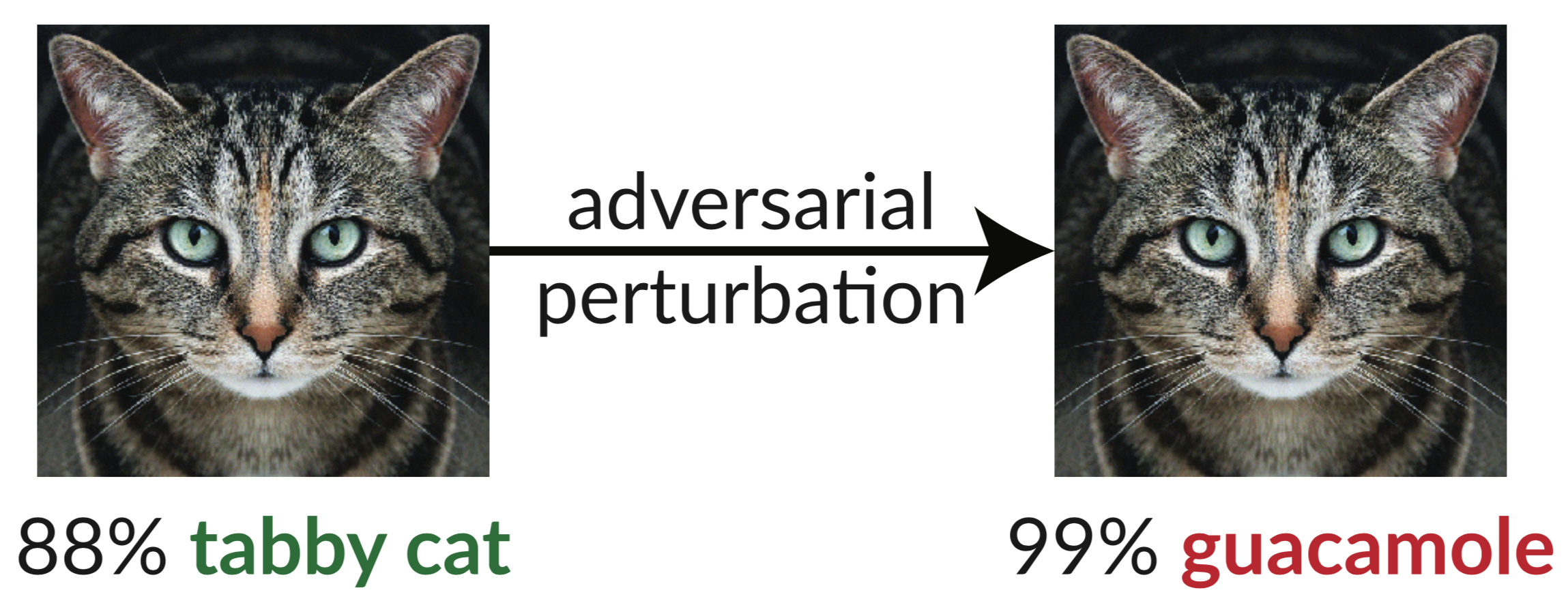
上面是一个对抗性示例:猫的轻微扰动图像欺骗了 InceptionV3 分类器,将其分类为“鳄梨酱”。使用梯度下降很容易合成这种“愚弄图像”(Szegedy et al. 2013)。
在我们最近的论文中,我们评估了 ICLR 2018 接受的 9 篇论文的稳健性,作为针对对抗性示例的未经认证的白盒安全防御。我们发现九种防御措施中的七种在稳健性方面的提高有限,并且可以通过我们开发的改进的攻击技术来破解。
下面是我们论文中的表 1,其中我们展示了每个已接受的防御对于我们可以构建的对抗性示例的稳健性:
| 防御 | 数据集 | 距离 | 准确性 |
|---|---|---|---|
| 巴克曼等人。 (2018) | 西法尔 | 0.031(线性) | 0%* |
| 马等人。 (2018) | 西法尔 | 0.031(线性) | 5% |
| 郭等人。 (2018) | 图像网 | 0.05(l2) | 0%* |
| 迪伦等人。 (2018) | 西法尔 | 0.031(线性) | 0% |
| 谢等人。 (2018) | 图像网 | 0.031(线性) | 0%* |
| 宋等人。 (2018) | 西法尔 | 0.031(线性) | 9%* |
| 萨曼古埃等人。 (2018) | MNIST | 0.005(l2) | 55%** |
| 马德里等人。 (2018) | 西法尔 | 0.031(线性) | 47% |
| 娜等人。 (2018) | 西法尔 | 0.015(线性) | 15% |
(用 * 表示的防御也建议结合对抗性训练;我们在这里单独报告防御。完整数字请参阅我们的论文第 5 节。用 ** 表示的防御背后的基本原理的准确度为 0%;在实践中,防御缺陷导致理论上的失败的最佳攻击,请参阅第 5.4.2 节了解详细信息。)
我们观察到的唯一能够显着提高所提出的威胁模型中对抗性示例鲁棒性的防御措施是“迈向抵抗对抗性攻击的深度学习模型”(Madry 等人,2018 年),并且我们无法在不走出威胁模型的情况下击败这种防御措施。即便如此,该技术仍被证明难以扩展到 ImageNet 规模(Kurakin 等人,2016 年)。其余论文(除了 Na 等人的论文,其鲁棒性有限)无意或有意地依赖于我们所说的混淆梯度。标准攻击应用梯度下降来最大化给定图像上的网络损失,从而在神经网络上生成对抗性示例。这种优化方法需要有用的梯度信号才能成功。当防御混淆梯度时,它会破坏该梯度信号并导致基于优化的方法失败。
我们确定了防御措施导致梯度混淆的三种方式,并构造了攻击来绕过每种情况。我们的攻击通常适用于任何有意或无意地包括不可微分操作或以其他方式阻止梯度信号流过网络的防御。我们希望未来的工作能够使用我们的方法来进行更彻底的安全评估。
抽象的:
我们认为混淆梯度(一种梯度掩蔽)是一种在防御对抗性示例时导致错误的安全感的现象。虽然导致混淆梯度的防御措施似乎能够击败基于迭代优化的攻击,但我们发现依赖于这种效果的防御措施是可以被规避的。我们描述了表现出这种效果的防御的特征行为,并且对于我们发现的三种类型的混淆梯度中的每一种,我们开发了攻击技术来克服它。在 ICLR 2018 上检查未经认证的白盒安全防御的案例研究中,我们发现混淆梯度很常见,9 种防御中有 7 种依赖于混淆梯度。我们的新攻击成功地完全规避了每篇论文考虑的原始威胁模型中的 6 个攻击,以及部分攻击。
有关详细信息,请阅读我们的论文。
该存储库包含我们论文中描述的一般攻击技术的实例,突破了 ICLR 2018 的 7 项防御措施。有些防御措施没有发布源代码(在我们做这项工作时),所以我们不得不重新实现它们。
@inproceedings{obfuscated-gradients,作者 = {Anish Athalye 和 Nicholas Carlini 和 David Wagner},标题 = {混淆梯度给出错误的安全感:规避对抗性示例的防御},书名 = {第 35 届国际机器会议论文集学习,{ICML} 2018},年 = {2018},月 =七月,网址= {https://arxiv.org/abs/1802.00420},
} 

