Megatron LM
NVIDIA Megatron Core 0.9.0
该存储库包含两个基本组件: Megatron-LM和Megatron-Core 。 Megatron-LM 是一个以研究为导向的框架,利用 Megatron-Core 进行大型语言模型 (LLM) 训练。另一方面,Megatron-Core 是一个 GPU 优化训练技术库,附带正式产品支持,包括版本化 API 和定期版本。您可以将 Megatron-Core 与 Megatron-LM 或 Nvidia NeMo Framework 一起使用,以实现端到端和云原生解决方案。或者,您可以将 Megatron-Core 的构建模块集成到您首选的培训框架中。
Megatron(1、2 和 3)于 2019 年首次推出,引发了人工智能社区的创新浪潮,使研究人员和开发人员能够利用该库的基础来进一步推动法学硕士的进步。如今,许多最流行的 LLM 开发框架都是受到开源 Megatron-LM 库的启发并直接利用其构建的,从而引发了一波基础模型和人工智能初创公司的浪潮。一些基于 Megatron-LM 构建的最流行的 LLM 框架包括 Colossal-AI、HuggingFace Accelerate 和 NVIDIA NeMo Framework。直接使用威震天的项目列表可以在这里找到。
Megatron-Core 是一个基于 PyTorch 的开源库,包含 GPU 优化技术和尖端的系统级优化。它将它们抽象为可组合和模块化的 API,使开发人员和模型研究人员能够充分灵活地在 NVIDIA 加速计算基础设施上大规模训练自定义 Transformer。该库与所有 NVIDIA Tensor Core GPU 兼容,包括对 NVIDIA Hopper 架构的 FP8 加速支持。
Megatron-Core 提供核心构建模块,例如注意力机制、变压器块和层、归一化层和嵌入技术。激活重新计算、分布式检查点等附加功能也原生内置于该库中。构建块和功能均经过 GPU 优化,并且可以使用高级并行化策略进行构建,以在 NVIDIA 加速计算基础设施上实现最佳训练速度和稳定性。 Megatron-Core 库的另一个关键组件包括高级模型并行技术(张量、序列、管道、上下文和 MoE 专家并行)。
Megatron-Core 可与企业级 AI 平台 NVIDIA NeMo 配合使用。或者,您可以在此处使用本机 PyTorch 训练循环探索 Megatron-Core。请访问 Megatron-Core 文档以了解更多信息。
我们的代码库能够有效地训练具有模型和数据并行性的大型语言模型(即具有数千亿个参数的模型)。为了演示我们的软件如何通过多个 GPU 和模型大小进行扩展,我们考虑了从 20 亿个参数到 4620 亿个参数的 GPT 模型。所有模型都使用 131,072 的词汇量和 4096 的序列长度。我们改变隐藏大小、注意力头数量和层数以达到特定的模型大小。随着模型大小的增加,我们也会适度增加批量大小。我们的实验使用多达 6144 个 H100 GPU。我们执行数据并行( --overlap-grad-reduce --overlap-param-gather )、张量并行( --tp-comm-overlap )和管道并行通信(默认启用)的细粒度重叠计算以提高可扩展性。报告的吞吐量是针对端到端训练进行测量的,包括所有操作,包括数据加载、优化器步骤、通信甚至日志记录。请注意,我们没有训练这些模型来收敛。
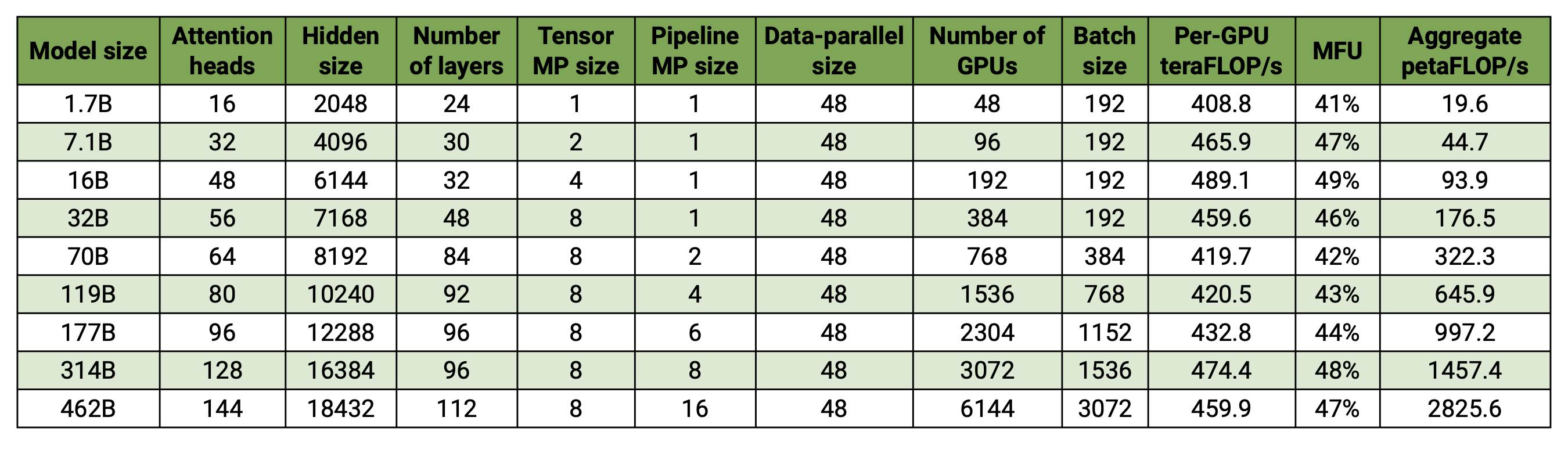
我们的弱缩放结果显示超线性缩放(MFU 从最小模型的 41% 增加到最大模型的 47-48%);这是因为更大的 GEMM 具有更高的算术强度,因此执行效率更高。
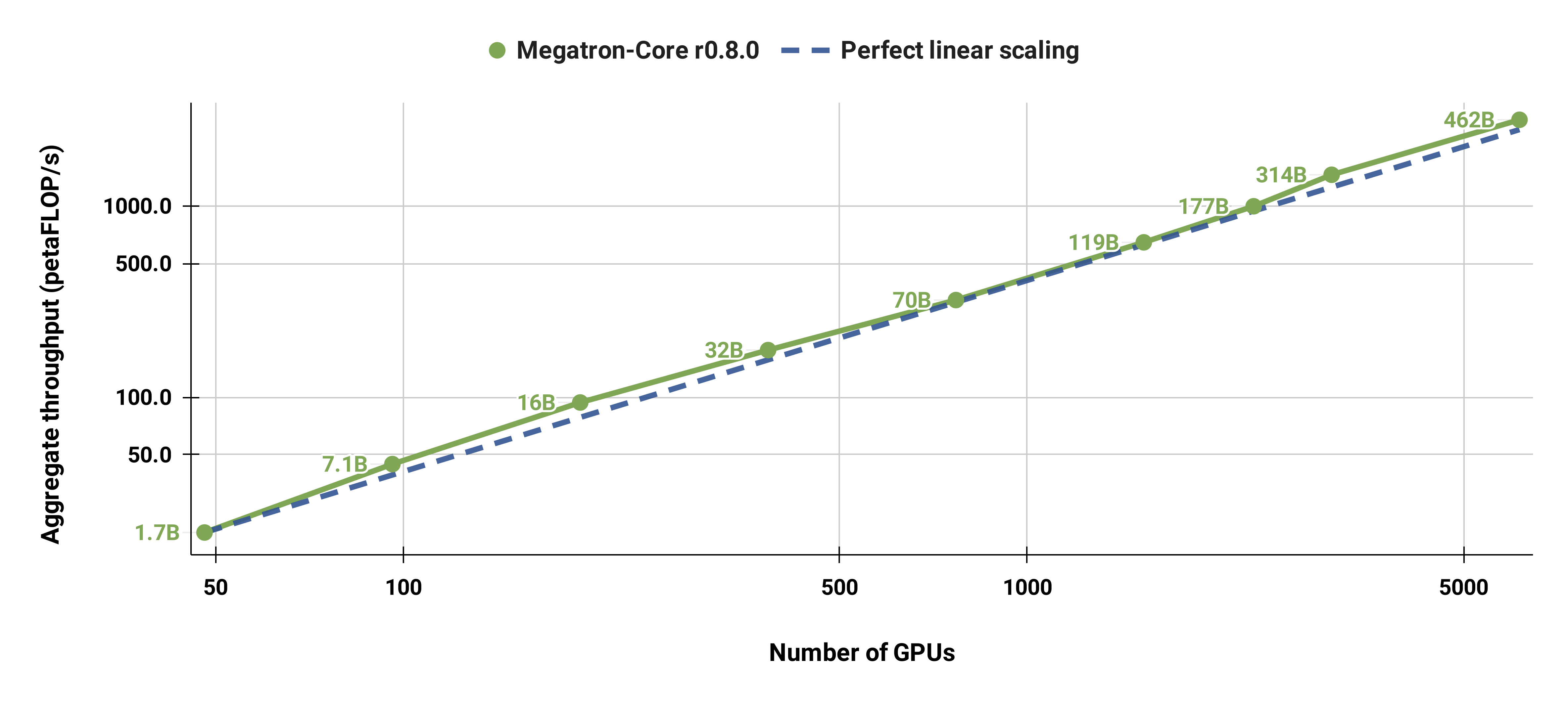
我们还将标准 GPT-3 模型(由于词汇量较大,我们的版本具有略多于 1750 亿个参数)从 96 个 H100 GPU 扩展到 4608 个 GPU,并始终使用 1152 个序列的相同批量大小。通信在更大范围内变得更加暴露,导致 MFU 从 47% 减少到 42%。
我们强烈建议将最新版本的 NGC 的 PyTorch 容器与 DGX 节点结合使用。如果您由于某种原因无法使用此功能,请使用最新的 pytorch、cuda、nccl 和 NVIDIA APEX 版本。数据预处理需要 NLTK,但这对于训练、评估或下游任务来说不是必需的。
您可以使用以下 Docker 命令启动 PyTorch 容器的实例并挂载 Megatron、您的数据集和检查点:
docker pull nvcr.io/nvidia/pytorch:xx.xx-py3
docker run --gpus all -it --rm -v /path/to/megatron:/workspace/megatron -v /path/to/dataset:/workspace/dataset -v /path/to/checkpoints:/workspace/checkpoints nvcr.io/nvidia/pytorch:xx.xx-py3
我们提供了预训练的 BERT-345M 和 GPT-345M 检查点来评估或微调下游任务。要访问这些检查点,请首先注册并设置 NVIDIA GPU Cloud (NGC) 注册表 CLI。有关下载模型的更多文档可以在 NGC 文档中找到。
或者,您可以使用以下方式直接下载检查点:
BERT-345M-uncased:wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_bert_345m/versions/v0.1_uncased/zip -O megatron_bert_345m_v0.1_uncased.zip BERT-345M-cased:wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_bert_345m/versions/v0.1_cased/zip -O megatron_bert_345m_v0.1_cased.zip GPT-345M:wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_lm_345m/versions/v0.0/zip -O megatron_lm_345m_v0.0.zip
这些模型需要词汇文件才能运行。 BERT WordPiece 词汇文件可以从 Google 预训练的 BERT 模型中提取:uncased、cased。 GPT词汇文件和合并表可以直接下载。
安装后,有几种可能的工作流程。最全面的是:
但是,可以使用上述预训练模型之一来替换步骤 1 和 2。
我们在examples目录中提供了几个用于预训练 BERT 和 GPT 的脚本,以及用于零样本和微调下游任务的脚本,包括 MNLI、RACE、WikiText103 和 LAMBADA 评估。还有一个用于 GPT 交互式文本生成的脚本。
训练数据需要预处理。首先,将训练数据采用松散的 json 格式,其中一个 json 每行包含一个文本样本。例如:
{“src”:“www.nvidia.com”,“text”:“敏捷的棕色狐狸”,“type”:“Eng”,“id”:“0”,“title”:“第一部分”}
{"src": "互联网", "text": "跳过懒狗", "type": "Eng", "id": "42", "title": "第二部分"}
json 的text字段的名称可以通过使用preprocess_data.py中的--json-key标志来更改。其他元数据是可选的,在训练中不使用。
然后将松散的 json 处理为二进制格式以进行训练。要将 json 转换为 mmap 格式,请使用preprocess_data.py 。为 BERT 训练准备数据的示例脚本是:
python 工具/preprocess_data.py
--输入 my-corpus.json
--输出前缀 my-bert
--vocab-文件 bert-vocab.txt
--tokenizer-type BertWordPieceLowerCase
--分割句子
输出将是两个文件,在本例中名为my-bert_text_sentence.bin和my-bert_text_sentence.idx 。后面的 BERT 训练中指定的--data-path是完整路径和新文件名,但不带文件扩展名。
对于 T5,使用与 BERT 相同的预处理,也许将其重命名为:
--输出前缀 my-t5
GPT 数据预处理需要进行一些小的修改,即添加合并表、文档结束标记、删除句子拆分以及更改标记器类型:
python 工具/preprocess_data.py
--输入 my-corpus.json
--输出前缀 my-gpt2
--vocab-文件 gpt2-vocab.json
--tokenizer-type GPT2BPETokenizer
--合并文件 gpt2-merges.txt
--追加eod
这里的输出文件被命名为my-gpt2_text_document.bin和my-gpt2_text_document.idx 。和以前一样,在 GPT 训练中,使用较长的名称(不带扩展名)作为--data-path 。
源文件preprocess_data.py中描述了更多命令行参数。
examples/bert/train_bert_340m_distributed.sh脚本运行单 GPU 345M 参数 BERT 预训练。调试是单 GPU 训练的主要用途,因为代码库和命令行参数针对高度分布式训练进行了优化。大多数论点都是不言自明的。默认情况下,学习率在从--lr开始的训练迭代中线性衰减到--lr-decay-iters迭代中由--min-lr设置的最小值。用于预热的训练迭代分数由--lr-warmup-fraction设置。虽然这是单 GPU 训练, --micro-batch-size指定的批量大小是单个前向-后向路径批量大小,并且代码将执行梯度累积步骤,直到达到批量global-batch-size大小每次迭代。数据按 949:50:1 的比例划分为训练/验证/测试集(默认为 969:30:1)。这种分区是动态发生的,但在使用相同随机种子的运行中是一致的(默认为 1234,或使用--seed手动指定)。我们使用train-iters作为训练迭代的要求。或者,可以提供--train-samples这是要训练的样本总数。如果存在此选项,则不需要提供--lr-decay-iters ,而是需要提供--lr-decay-samples 。
指定了日志记录、检查点保存和评估间隔选项。请注意, --data-path现在包含在预处理中添加的附加_text_sentence后缀,但不包含文件扩展名。
源文件arguments.py中描述了更多命令行参数。
要运行train_bert_340m_distributed.sh ,请进行任何所需的修改,包括设置CHECKPOINT_PATH 、 VOCAB_FILE和DATA_PATH的环境变量。确保将这些变量设置为其在容器中的路径。然后启动安装了威震天和必要路径的容器(如设置中所述)并运行示例脚本。
examples/gpt3/train_gpt3_175b_distributed.sh脚本运行单 GPU 345M 参数 GPT 预训练。如上所述,单 GPU 训练主要用于调试目的,因为代码针对分布式训练进行了优化。
它遵循与之前的 BERT 脚本基本相同的格式,但有一些显着的差异:使用的标记化方案是 BPE(需要合并表和json词汇文件)而不是 WordPiece,模型架构允许更长的序列(请注意,最大位置嵌入必须大于或等于最大序列长度),并且--lr-decay-style已设置为余弦衰减。请注意, --data-path现在包含在预处理中添加的附加_text_document后缀,但不包含文件扩展名。
源文件arguments.py中描述了更多命令行参数。
train_gpt3_175b_distributed.sh可以按照与 BERT 描述相同的方式启动。设置环境变量并进行任何其他修改,使用适当的安装启动容器,然后运行脚本。更多详细信息,请参阅examples/gpt3/README.md
与 BERT 和 GPT 非常相似, examples/t5/train_t5_220m_distributed.sh脚本运行单 GPU“基础”(~220M 参数)T5 预训练。与 BERT 和 GPT 的主要区别是添加了以下参数以适应 T5 架构:
--kv-channels设置模型中所有注意力机制的“键”和“值”矩阵的内部维度。对于 BERT 和 GPT,默认为隐藏大小除以注意力头的数量,但可以为 T5 配置。
--ffn-hidden-size设置变压器层内前馈网络中的隐藏大小。对于 BERT 和 GPT,默认为转换器隐藏大小的 4 倍,但可以为 T5 配置。
--encoder-seq-length和--decoder-seq-length分别设置编码器和解码器的序列长度。
所有其他论点仍然与 BERT 和 GPT 预训练相同。使用上述其他脚本的相同步骤运行此示例。
更多详细信息,请参阅examples/t5/README.md
pretrain_{bert,gpt,t5}_distributed.sh脚本使用 PyTorch 分布式启动器进行分布式训练。这样,通过适当设置环境变量就可以实现多节点训练。有关这些环境变量的进一步描述,请参阅 PyTorch 官方文档。默认情况下,多节点训练使用 nccl 分布式后端。一组简单的附加参数以及使用 PyTorch 分布式模块和torchrun弹性启动器(相当于python -m torch.distributed.run )是采用分布式训练的唯一附加要求。有关更多详细信息,请参阅pretrain_{bert,gpt,t5}_distributed.sh中的任何一个。
我们使用两种类型的并行性:数据并行性和模型并行性。我们的数据并行实现位于megatron/core/distributed中,并且在使用--overlap-grad-reduce命令行选项时支持梯度缩减与后向传递的重叠。
其次,我们开发了一种简单高效的二维模型并行方法。要使用第一个维度,即张量模型并行性(将单个转换器模块的执行拆分到多个 GPU 上,请参阅我们论文的第 3 节),请添加--tensor-model-parallel-size标志来指定要执行的 GPU 数量分割模型,以及如上所述传递给分布式启动器的参数。要使用第二个维度,即序列并行性,请指定--sequence-parallel ,这还需要启用张量模型并行性,因为它会跨相同的 GPU 进行拆分(更多详细信息请参阅我们论文的第 4.2.2 节)。
要使用管道模型并行性(将变压器模块分片为阶段,每个阶段上具有相同数量的变压器模块,然后通过将批处理分解为更小的微批次来流水线执行,请参阅我们论文的第 2.2 节),请使用--pipeline-model-parallel-size标志指定将模型拆分为的阶段数(例如,将具有 24 个变压器层的模型拆分为 4 个阶段将意味着每个阶段各有 6 个变压器层)。
我们提供了如何使用这两种不同形式的模型并行性的示例(以distributed_with_mp.sh结尾的示例脚本)。
除了这些细微的变化之外,分布式训练与单个 GPU 上的训练相同。
可以使用--num-layers-per-virtual-pipeline-stage参数启用交错流水线调度(更多详细信息请参见本文的第 2.2.2 节),该参数控制虚拟阶段中变压器层的数量(默认情况下)使用非交错调度,每个 GPU 将执行具有NUM_LAYERS / PIPELINE_MP_SIZE转换器层的单个虚拟阶段。变压器模型中的总层数应能被该参数值整除。此外,使用此计划时,管道中的微批次数量(计算为GLOBAL_BATCH_SIZE / (DATA_PARALLEL_SIZE * MICRO_BATCH_SIZE) )应能被PIPELINE_MP_SIZE整除(此条件在代码中的断言中检查)。具有 2 个阶段的管道 ( PIPELINE_MP_SIZE=2 ) 不支持交错调度。
为了减少训练大型模型时 GPU 内存的使用,我们支持各种形式的激活检查点和重新计算。与深度学习模型中的传统情况不同,所有激活都存储在内存中以便在反向传播期间使用,只有模型中某些“检查点”的激活才会保留(或存储)在内存中,而其他激活则重新计算-the-fly 当需要反向传播时。请注意,这种检查点(激活检查点)与其他地方提到的模型参数和优化器状态的检查点有很大不同。
我们支持两种级别的重新计算粒度: selective和full 。选择性重新计算是默认设置,并且在几乎所有情况下都建议使用。此模式将占用较少内存存储空间且重新计算成本较高的激活保留在内存中,并重新计算占用较多内存存储空间但重新计算相对便宜的激活。有关详细信息,请参阅我们的论文。您应该发现此模式可以最大限度地提高性能,同时最大限度地减少存储激活所需的内存。要启用选择性激活重新计算,只需使用--recompute-activations 。
对于内存非常有限的情况, full重新计算仅保存变压器层或变压器层组或块的输入,并重新计算其他所有内容。要启用完全激活重新计算,请使用--recompute-granularity full 。使用full激活重新计算时,有两种方法: uniform和block ,使用--recompute-method参数进行选择。
uniform方法将 Transformer 层统一划分为层组(每组大小为--recompute-num-layers ),并将每组的输入激活存储在内存中。基线组大小为 1,在这种情况下,存储每个转换器层的输入激活。当 GPU 内存不足时,增加每组的层数可以减少内存使用量,从而可以训练更大的模型。例如,当--recompute-num-layers设置为 4 时,仅存储每组 4 个转换器层的输入激活。
block方法重新计算每个管道阶段的特定数量(由--recompute-num-layers给出)的各个 Transformer 层的输入激活,并将其余层的输入激活存储在管道阶段。减少--recompute-num-layers会导致将输入激活存储到更多转换器层,从而减少反向传播中所需的激活重新计算,从而提高训练性能,同时增加内存使用量。例如,当我们指定 5 层来重新计算每个管道阶段的 8 层时,只有前 5 个转换器层的输入激活在反向传播步骤中被重新计算,而最后 3 层的输入激活被存储。 --recompute-num-layers可以逐渐增加,直到所需的内存存储空间量刚好小到足以适合可用内存,从而最大限度地利用内存并最大化性能。
用法: --use-distributed-optimizer 。与所有模型和数据类型兼容。
分布式优化器是一种内存节省技术,优化器状态均匀分布在数据并行列之间(与跨数据并行列复制优化器状态的传统方法不同)。如《ZeRO:训练万亿参数模型的内存优化》中所述,我们的实现分布了与模型状态不重叠的所有优化器状态。例如,当使用 fp16 模型参数时,分布式优化器维护自己的 fp32 主要参数和梯度的单独副本,这些副本分布在 DP 等级中。然而,当使用 bf16 模型参数时,分布式优化器的 fp32 主参数与模型的 fp32 参数相同,因此这种情况下的参数不是分布式的(尽管 fp32 主参数仍然是分布式的,因为它们与 bf16 是分开的)模型参数)。
理论上的内存节省量根据模型的 param dtype 和 grad dtype 的组合而有所不同。在我们的实现中,每个参数的理论字节数为(其中“d”是数据并行大小):
| 非分布式优化 | 分布式优化 | |
|---|---|---|
| fp16 参数、fp16 梯度 | 20 | 4 + 16/天 |
| bf16 参数,fp32 等级 | 18 | 6+12/天 |
| fp32 参数、fp32 梯度 | 16 | 8+8/天 |
与常规数据并行性一样,可以使用--overlap-grad-reduce标志来促进梯度减少(在本例中为减少分散)与向后传递的重叠。此外,参数 all-gather 的重叠可以使用--overlap-param-gather与前向传递重叠。
用法: --use-flash-attn 。最多支持128个注意力头尺寸。
FlashAttention 是一种快速且节省内存的算法,用于计算精确注意力。它加快了模型训练速度并减少了内存需求。
安装 FlashAttention:
pip install flash-attn在examples/gpt3/train_gpt3_175b_distributed.sh中,我们提供了如何配置 Megatron 在 1024 个 GPU 上使用 1750 亿个参数训练 GPT-3 的示例。该脚本是为带有 pyxis 插件的 slurm 设计的,但可以轻松地应用于任何其他调度程序。它采用8路张量并行和16路管道并行。使用选项global-batch-size 1536和rampup-batch-size 16 16 5859375 ,训练将从全局批量大小 16 开始,并在增量步骤 16 的 5,859,375 个样本上将全局批量大小线性增加到 1536。训练数据集可以是单个集合或多个数据集与一组权重的组合。
在 1024 个 A100 GPU 上的完整全局批量大小为 1536 时,每次迭代大约需要 32 秒,导致每个 GPU 达到 138 teraFLOP,这是理论峰值 FLOP 的 44%。
Retro(Borgeaud 等人,2022)是一种经过检索增强预训练的自回归解码器语言模型 (LM)。 Retro 具有实用的可扩展性,可通过检索数万亿个代币来支持从头开始的大规模预训练。与在网络参数中隐式存储事实知识相比,带有检索的预训练提供了更有效的事实知识存储机制,从而大大减少了模型参数,同时实现了比标准 GPT 更低的困惑度。 Retro 还可以通过更新检索数据库来灵活地更新 LM 中存储的知识(Wang 等人,2023a),而无需再次训练 LM。
InstructRetro(Wang 等人,2023b)进一步将 Retro 的大小扩大到 48B,具有最大的经过检索预训练的 LLM(截至 2023 年 12 月)。获得的基础模型 Retro 48B 在困惑度方面大大优于 GPT 模型。通过对 Retro 进行指令调整,InstructRetro 在零样本设置中的下游任务上展示了比指令调整 GPT 的显着改进。具体来说,InstructRetro 在 8 项短格式 QA 任务中的平均改进比 GPT 同行提高了 7%,在 4 项具有挑战性的长格式 QA 任务中比 GPT 平均改进了 10%。我们还发现,可以从 InstructRetro 架构中消除编码器,并直接使用 InstructRetro 解码器主干作为 GPT,同时获得可比较的结果。
在此存储库中,我们提供了实现 Retro 和 InstructRetro 的端到端复制指南,涵盖
有关详细概述,请参阅tools/retro/README.md。
有关详细信息,请参阅示例/mamba。
我们提供了几个命令行参数(在下面列出的脚本中详细介绍)来处理各种零样本和微调的下游任务。但是,您还可以根据需要从其他语料库上的预训练检查点微调您的模型。为此,只需添加--finetune标志并调整原始训练脚本中的输入文件和训练参数即可。迭代计数将重置为零,优化器和内部状态将重新初始化。如果微调因任何原因中断,请务必在继续之前删除--finetune标志,否则训练将从头开始。
由于评估所需的内存比训练少得多,因此合并并行训练的模型以便在下游任务中在更少的 GPU 上使用可能会更有利。以下脚本完成此任务。此示例读取具有 4 路张量和 4 路管道模型并行性的 GPT 模型,并写出具有 2 路张量和 2 路管道模型并行性的模型。
python 工具/检查点/convert.py
--模型类型 GPT
--load-dir 检查点/gpt3_tp4_pp4
--save-dir 检查点/gpt3_tp2_pp2
--目标张量并行大小 2
--目标管道并行大小 2
下面描述了 GPT 和 BERT 模型的几个下游任务。它们可以在分布式和模型并行模式下运行,并在训练脚本中使用相同的更改。
我们在tools/run_text_generation_server.py中包含了一个简单的 REST 服务器,用于生成文本。您运行它就像开始预训练作业一样,指定适当的预训练检查点。还有一些可选参数: temperature 、 top-k和top-p 。有关详细信息,请参阅--help或源文件。有关如何运行服务器的示例,请参阅examples/inference/run_text_ Generation_server_345M.sh。
服务器运行后,您可以使用tools/text_generation_cli.py来查询它,它需要一个参数,即服务器正在运行的主机。
工具/text_ Generation_cli.py 本地主机:5000
您还可以使用 CURL 或任何其他工具直接查询服务器:
卷曲 'http://localhost:5000/api' -X 'PUT' -H '内容类型:application/json; charset=UTF-8' -d '{"prompts":["Hello world"], "tokens_to_generate":1}'
有关更多 API 选项,请参阅 megatron/inference/text_ Generation_server.py。
我们在examples/academic_paper_scripts/detxoify_lm/中包含一个示例,通过利用语言模型的生成能力来消除语言模型的毒害。
请参阅 example/academic_paper_scripts/detxoify_lm/README.md,了解有关如何使用自行生成的语料库执行领域自适应训练和解毒 LM 的分步教程。
我们提供了针对 WikiText 困惑度评估和 LAMBADA 完型填空准确性进行 GPT 评估的示例脚本。
为了与之前的作品进行比较,我们评估了单词级 WikiText-103 测试数据集的困惑度,并根据使用我们的子词标记生成器时标记的变化适当地计算困惑度。
我们使用以下命令在 345M 参数模型上运行 WikiText-103 评估。
任务=“WIKITEXT103”
VALID_DATA=<维基文本路径>.txt
VOCAB_FILE=gpt2-vocab.json
MERGE_FILE=gpt2-merges.txt
CHECKPOINT_PATH=检查点/gpt2_345m
COMMON_TASK_ARGS="--层数 24
--隐藏大小 1024
--num-attention-heads 16
--seq-长度 1024
--最大位置嵌入 1024
--fp16
--vocab-文件 $VOCAB_FILE"
python 任务/main.py
--任务 $TASK
$COMMON_TASK_ARGS
--有效数据 $VALID_DATA
--tokenizer-type GPT2BPETokenizer
--合并文件 $MERGE_FILE
--加载$CHECKPOINT_PATH
--微批量大小 8
--日志间隔 10
--无负载优化
--无负载-rng
为了计算 LAMBADA 完形填空准确性(在给定前面的标记的情况下预测最后一个标记的准确性),我们利用 LAMBADA 数据集的去标记化、处理版本。
我们使用以下命令在 345M 参数模型上运行 LAMBADA 评估。请注意,应使用--strict-lambada标志来要求整个单词匹配。确保lambada是文件路径的一部分。
任务=“兰巴达”
VALID_DATA=<兰巴达路径>.json
VOCAB_FILE=gpt2-vocab.json
MERGE_FILE=gpt2-merges.txt
CHECKPOINT_PATH=检查点/gpt2_345m
COMMON_TASK_ARGS=<与上面维基文本困惑度评估中的相同>
python 任务/main.py
--任务 $TASK
$COMMON_TASK_ARGS
--有效数据 $VALID_DATA
--tokenizer-type GPT2BPETokenizer
--严格-兰巴达
--合并文件 $MERGE_FILE
--加载$CHECKPOINT_PATH
--微批量大小 8
--日志间隔 10
--无负载优化
--无负载-rng
源文件main.py中描述了更多命令行参数
以下脚本微调 BERT 模型以在 RACE 数据集上进行评估。 TRAIN_DATA和VALID_DATA目录包含 RACE 数据集作为单独的.txt文件。请注意,对于 RACE,批量大小是要评估的 RACE 查询的数量。由于每个 RACE 查询都有四个样本,因此通过模型传递的有效批量大小将是命令行上指定的批量大小的四倍。
TRAIN_DATA =“数据/比赛/火车/中间”
VALID_DATA =“数据/种族/开发/中间
数据/种族/开发/高”
VOCAB_FILE=bert-vocab.txt
PRETRAINED_CHECKPOINT=检查点/bert_345m
CHECKPOINT_PATH=检查点/bert_345m_race
COMMON_TASK_ARGS="--层数 24
--隐藏大小 1024
--num-attention-heads 16
--seq-长度 512
--最大位置嵌入 512
--fp16
--vocab-文件 $VOCAB_FILE"
COMMON_TASK_ARGS_EXT="--train-data $TRAIN_DATA
--有效数据 $VALID_DATA
--pretrained-checkpoint $PRETRAINED_CHECKPOINT
--保存间隔 10000
--保存$CHECKPOINT_PATH
--日志间隔 100
--评估间隔 1000
--评估迭代 10
--重量衰减 1.0e-1"
python 任务/main.py
--任务竞赛
$COMMON_TASK_ARGS
$COMMON_TASK_ARGS_EXT
--tokenizer-type BertWordPieceLowerCase
--纪元 3
--微批量大小 4
--lr 1.0e-5
--lr-预热分数 0.06
以下脚本对 BERT 模型进行微调,以使用 MultiNLI 句子对语料库进行评估。由于匹配任务非常相似,因此可以快速调整脚本以使用 Quora 问题对 (QQP) 数据集。
TRAIN_DATA =“数据/glue_data/MNLI/train.tsv”
VALID_DATA =“数据/glue_data/MNLI/dev_matched.tsv
数据/glue_data/MNLI/dev_mismatched.tsv”
PRETRAINED_CHECKPOINT=检查点/bert_345m
VOCAB_FILE=bert-vocab.txt
CHECKPOINT_PATH=检查点/bert_345m_mnli
COMMON_TASK_ARGS=<与上面RACE评估中的相同>
COMMON_TASK_ARGS_EXT=<与上面RACE评估中的相同>
python 任务/main.py
--任务 MNLI
$COMMON_TASK_ARGS
$COMMON_TASK_ARGS_EXT
--tokenizer-type BertWordPieceLowerCase
--纪元 5
--微批量大小 8
--lr 5.0e-5
--lr-预热分数 0.065
Llama-2 系列模型是一组开源的预训练和微调(用于聊天)模型,在广泛的基准测试中取得了出色的结果。在发布时,Llama-2 模型取得了开源模型中最好的结果之一,并且与闭源 GPT-3.5 模型具有竞争力(参见 https://arxiv.org/pdf/2307.09288.pdf)。
Llama-2 检查点可以加载到威震天中进行推理和微调。请参阅此处的文档。
Megatron-Core (MCore) GPTModel系列通过 TensorRT-LLM 支持高级量化算法和高性能推理。
有关llama2和nemotron3示例,请参阅威震天模型优化和部署。
我们不托管任何用于 GPT 或 BERT 训练的数据集,但是,我们详细说明了它们的集合,以便可以重现我们的结果。
我们建议遵循 Google 研究指定的维基百科数据提取过程:“建议的预处理是下载最新的转储,使用 WikiExtractor.py 提取文本,然后应用任何必要的清理将其转换为纯文本。”
我们建议在使用 WikiExtractor 时使用--json参数,它将把 Wikipedia 数据转储为松散的 json 格式(每行一个 json 对象),使其在文件系统上更易于管理,也易于我们的代码库使用。我们建议使用 nltk 标点符号标准化进一步预处理此 json 数据集。对于 BERT 训练,请如上所述使用--split-sentences标志到preprocess_data.py以在生成的索引中包含句子中断。如果您想使用 Wikipedia 数据进行 GPT 训练,您仍然应该使用 nltk/spacy/ftfy 清理它,但不要使用--split-sentences标志。
我们利用 jcpeterson 和 eukaryote31 的公开可用的 OpenWebText 库来下载 URL。然后,我们根据 openwebtext 目录中描述的过程过滤、清理和删除所有下载的内容。对于截至 2018 年 10 月的内容对应的 Reddit URL,我们得到了大约 37GB 的内容。
威震天训练可以按位重现;要启用此模式,请使用--deterministic-mode 。这意味着相同的训练配置在相同的硬件和软件环境中运行两次应该产生相同的模型检查点、损失和准确性指标值(迭代时间指标可能会有所不同)。
目前存在三种已知的威震天优化,这些优化破坏了可重复性,同时仍然产生几乎相同的训练运行:
NCCL_ALGO指定)非常重要。我们测试了以下内容: ^NVLS 、 Tree 、 Ring 、 CollnetDirect 、 CollnetChain 。该代码允许使用^NVLS ,这允许 NCCL 选择非 NVLS 算法;它的选择似乎是稳定的。--use-flash-attn 。NVTE_ALLOW_NONDETERMINISTIC_ALGO=0 。此外,确定性仅在 23.12 及更高版本的 NGC PyTorch 容器中进行了验证。如果您在其他情况下观察到威震天训练中的不确定性,请提出问题。
以下是我们直接使用威震天的一些项目:


