作者:郑步前(buqiianz)、黄永康(yongkan1)
海报
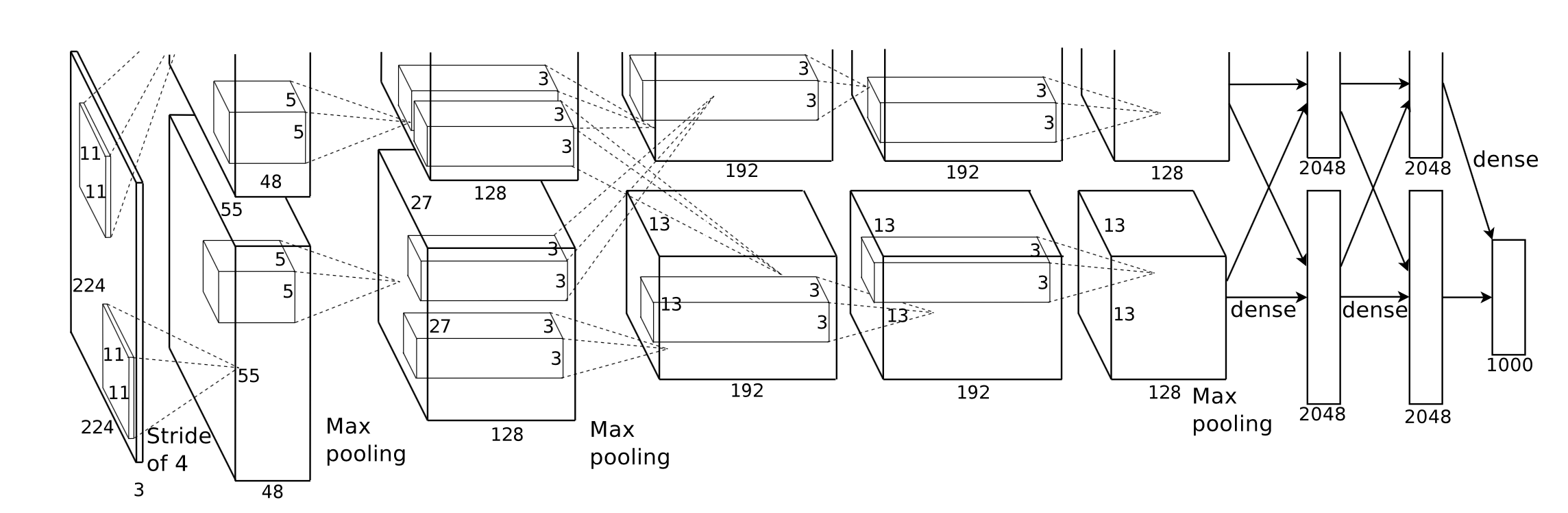
我们在 Swift 和 Metal 中实现了 Corgy,一个深度学习框架。 Corgy 可以嵌入到 macOS 和 iOS 应用程序中,并用于构建经过训练的神经网络并轻松对其进行评估。我们在具有不同 GPU 的不同设备上实现了超过 60 倍的加速。

Metal 2 框架是 Apple 提供的接口,可提供对 iPhone/iPad 和 Mac 上图形处理单元 (GPU) 近乎直接的访问。除了图形之外,Metal 2 还集成了一系列库,为能够在各种 Apple 设备中运行的必要线性代数运算和信号处理函数提供出色的并行支持。这些库使我们能够基于其他框架提供的训练模型在 iOS 设备上构建良好实现的 GPU 加速的深度学习模型。 1
一般来说,经过训练的神经网络的推理阶段是计算密集型的,特别是对于那些具有相当大的层数或应用于处理高分辨率图像所需的场景的模型。值得注意的是,存在大量的矩阵计算(例如卷积层) ,适合应用并行操作来优化性能。
我们面临的第一个挑战是设计一个良好的应用程序编程接口抽象,该接口具有表现力、易于使用、学习曲线低、易于用户使用。
在整个开发过程中,我们尽最大努力使公共 API 尽可能简单,同时利用 Swift 提供的函数式编程机制创建所需的每个组件所需的所有必要属性。我们还故意隐藏了 Metal 提供的不必要的硬件抽象,以平滑学习曲线。
尽管各种网络的训练模型很容易在互联网上获得,但由于使用各种工具的不同实现而导致它们之间的异构性,导致了创建通用模型导入器的工作。
有些计算的概念很容易理解,但当您想通过抽象来创建有效的实现时,需要仔细思考。卷积是一个代表性的例子。
卷积运算的内在属性不具有良好的局部性,普通的实现很难理解并且对于复杂的 for 循环无效。此外,我们需要考虑 Metal 2 提供的抽象,并创建一种方便的方法来在主机和设备之间共享必要的信息和数据结构,同时仔细考虑数据表示和内存布局。
在开发阶段,我们非常认真地对待我们的代码能够在 macOS 和 iOS 上正常运行的能力,同时不影响这两个平台的性能。我们尽力维护能够在两个平台上编译和执行的代码库。我们谨慎地最大化不同目标之间共享的代码并尽可能地重用代码。
由于神经网络层的完全实现的组件应该提供合理数量的参数支持,使组件足够可用,因此组件的复杂性实际上相当令人印象深刻。例如,卷积层应支持包含填充、扩张步幅等的参数,并且在进行并行化以实现合理性能时应谨慎考虑所有这些参数。我们构建了一些简单的网络来进行回归测试。测试用例是在其他框架(主要是 PyTorch 和 Keras)中创建的,以确保所有实现都能正常工作。
Swift于2010年7月首次开发,并于2014年发布并开源。虽然发布已近4年,但缺乏有影响力的库仍然是一个不可忽视的问题。造成这种情况是有原因的,Apple的主导地位和Swift的快速迭代特性可能是造成这种现象的原因。一些对我们至关重要的库要么不够强大,功能不够满足我们的需求,要么发明它们的个人开发人员维护得不好。我们花了相当多的时间来实现一个功能良好的张量类Variable来满足我们的需求。
此外,文件和字符串处理功能的能力非常有限,这也是阻碍通用模型解析器开发的另一个原因。
另外,开发和调试工具基本上仅限于Xcode,虽然还有其他对我们来说更通用的选择,但Xcode仍然是我们开发事实上的标准工具。
对于移动设备的性能调优,苹果没有为其 SoC 提供详细的硬件规格,媒体广泛使用营销名称,很难推断特定硬件功能的确切影响以及微调实现的性能。
我们使用 Swift 编程语言,具体来说,Swift 4.2,这是迄今为止最新的; Metal 2框架和Metal Performance Shader提供的一些库函数(基本线性代数函数)。尽管Apple在2017年春季推出了CoreML SDK,其中包含了对卷积神经网络的一些支持,但我们并没有在Corgy中使用它们来获得开发网络层并行实现的宝贵经验,并提供简洁直观的API,具有良好的可用性和平滑的学习曲线让用户轻松地从其他框架迁移模型。
我们的目标机器是所有运行 macOS 和 iOS 的设备,例如 iMac、MacBook、iPhone 和 iPad。具体来说,支持MPS线性代数库的平台的设备(即iOS 10.0和macOS 10.13之后),这意味着iPhone 5之后推出的iPhone,iPad(第四代)和iPod Touch(第六代)之后推出的iPad均支持 iOS 平台。 Mac产品线的覆盖范围更加广泛,包括2009年末或更新版本之后生产的iMac、2010年中期之后推出的所有MacBook系列以及iMac Pro。
Metal 2 的并行抽象与 CUDA 非常相似:当将计算机传递给 GPU 时,程序员将首先编写将由每个线程执行的内核函数,然后指定网格中的线程组(也称为 CUDA 中的块)的数量,以及每个线程组中的线程数,Metal 将在该网格上执行内核,该内核是用名为 Metal 着色语言的 C++14 方言实现的。每个线程组内部都有一个更小的单元,称为SIMD组,意思是一堆共享相同SIMD指令的线程。但在我们的实现下,不需要考虑这个。
Metal 提供了一个名为 MTLCommandBuffer 的 API,它存储由 GPU 提交和执行的编码命令。每次我们想要启动一个由 GPU 执行的任务时,预编译的内核函数都会被编码为 GPU 指令,嵌入到 Metal 着色管道中并发送到 MTLCommandBuffer。用于存储需要传递给设备的计算参数的Metal缓冲区也在这个阶段设置。然后,通过指定数量的线程组和每组线程,命令缓冲区处理的命令将被完全编码,并全部设置为提交到设备。 GPU会对任务进行调度,执行完成后通知CPU线程提交工作。
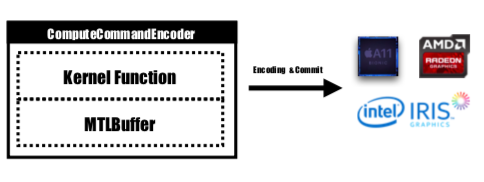
内核函数将由MTLComputeCommandEncoder进行编码,并且将为所有支持的平台创建任务。
在我们的实现中,我们广泛采用了一种直观的方式将元素映射到 GPU 线程:将当前层输出张量中的每个元素映射到一个 GPU 线程:每个线程计算并更新输出的一个元素,输入将是只读,所以我们不需要担心线程之间的同步。在此映射下,具有连续 id 的线程可能会从不同的内存位置读取输入数据,但始终会写入连续的内存位置。因此,当SIMD组写入内存时,不会出现分散操作。
我们设计了一个张量类Variable作为所有实现的基础,我们利用并将线性代数运算封装到Variable类中,而不是编写额外的内核来深入研究不是我们主要关注的操作,以降低实现的复杂性并节省我们的时间来专注于加速网络层。
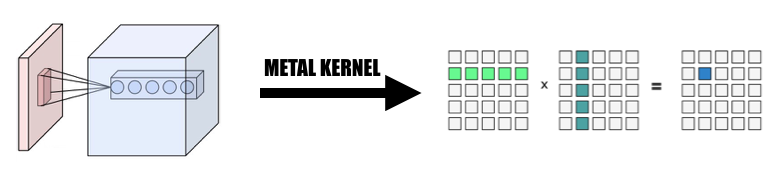
1.将卷积改为巨矩阵乘法
我们以并行方式从输入中收集数据,形成输入变量和权重的巨大矩阵。我们缓存每个卷积层的权重以避免重新计算。卷积层的填充将在计算过程中的并行化转换过程中生成,然后我们对巨型矩阵调用 MPSMatrixMultiply,并将巨型矩阵中的数据转换回我们创建的普通张量类。该方法在课堂幻灯片中进行了描述。
2.Variable类的设计与实现
变量类是我们实现张量表示的基础。我们封装了变量的 MPSMatrixMultiplication(将 Unicode 乘法符号 (×) 定义为中缀运算符以优雅地表示它:-))。
该变量的底层数据结构是一个指向数据类型的UnsafemutableBufferPointer ,为了简单起见,我们选择了32位Float。 Variable类维护了两个数据大小, count保存了实际存储的元素个数, actualCount是所有元素的大小四舍五入到使用getpagesize()获得的平台页面大小。
我们维护这两个值以确保makeBuffer(bytesNoCopy:)直接在指定的 VM 区域上创建缓冲区,并避免冗余重新分配,从而减少开销。如果传递给 Metal 的内存不是页对齐的,那么 Metal 将无法使用该内存作为输入或输出缓冲区。我们必须使用makeBuffer(bytes:)方法,该方法将创建一个新的缓冲区并从输入内存位置复制数据。因此,我们总是需要分配比需要更多的内存,以确保Variable中的所有内存都是页对齐的。因此,我们需要两个值来跟踪这块内存到底有多大以及我们应该使用多大。
3、单个线程处理的元素数量
我们尝试将一个线程映射到多个元素,从每个线程 2 到 16 个元素,性能几乎相同,但给我们的项目增加了很多复杂性,因此我们放弃了这种方法。
下面提到的所有 CPU 版本都是未经 SIMD 优化的简单单线程 CPU 代码。应用了-Ofast级别的编译器优化。
我们的实施效果不错,但还不够好。
我们使用 iPhone 6s 和 15 英寸 MacBook Pro 作为基准平台。硬件具体说明如下:
MacBook Pro(视网膜 15 英寸,2015 年中)
iPhone 6S
与没有并行性的简单 CPU 版本实现相比,我们的 GPU 版本快了 60 倍以上。
由于 MNIST 模型太小,其结果可能无法准确反映加速比。而且我们没有一个实现良好的单线程版本,我们无法给出准确的加速数字。由于 CPU 版本太慢,Tiny YOLO 上的加速比大得令人难以置信。
实验网络属性:
国家标准技术研究所:
约洛:
测量结果:
| iPhone 6s | MNIST | 小YOLO |
|---|---|---|
| 中央处理器 | 1500毫秒 | 753s |
| 图形处理器 | 0.025秒 | 0.5秒 |
| 加快 | 〜60倍 | 〜1500x |
| Macbook 专业版 | MNIST | 小YOLO |
|---|---|---|
| 中央处理器 | 650毫秒 | 729s |
| 图形处理器 | 10毫秒 | 0.028秒 |
| 加快 | 〜65x | 〜26000x |
根据上述基准,我们可以看到,随着问题规模的增加,
为什么我们说我们的加速不够好?因为与苹果官方实现的MPSCNNConvolution相比,我们的速度只有三分之一左右,这意味着还有很大的优化空间。此比较基于 YOLO 在 iPhone 上的开源实现,使用官方MPSCNNConvolution ,每秒可以识别约 5 个图像,而我们的实现每秒只能识别约 2 个图像。
而且由于时间有限,我们无法创建更好的基线版本和CPU并行版本来进行基准测试,这使得加速数字太大。
此外,值得报告不同问题大小的性能增益。我们可以看到,MNIST 只有 10 万个权重,而 Tiny YOLO 有 1700 万个。 Tiny YOLO 比 MNIST 复杂得多,但 GPU 版本的运行时间并没有那么多。这又是因为阿姆达尔定律。每启动一个GPU任务,都需要将相应的GPU命令编码到命令缓冲区中。这个过程本质上是串行的。当问题规模较小时,该过程对总运行时间贡献很大,因此通过并行化 MINST 中的神经网络推理阶段可能无法获得与 Tiny YOLO 相同的速度,后者的运行时间开销可以忽略不计。
是什么限制了你的加速?
if和for可能会导致发散,从而导致 SIMD 利用率不佳。更深入的分析:细分不同阶段的执行时间。
以Tiny YOLO为例,在Macbook上总运行时间为227ms的示例运行中,卷积层使用了207ms,占总运行时间的92%。 Pooling 层使用了 14ms(6%),ReLU 使用了 6ms(2%)。根据阿姆达尔定律,如果我们想进一步提高性能,我们肯定应该在卷积层上继续努力。
总的来说,我们相信我们选择 Metal 框架在 iOS 和 macOS 设备上进行神经网络加速是合理的,特别是对于 iOS 设备。由于它的核心较少,即使使用 SIMD 指令,经过良好调优的 CPU 版本也不太可能获得与 GPU 版本相似的性能。
两个团队成员完成同等的工作。
1 https://developer.apple.com/metal/ ↩
2 https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf ↩
3 http://pytorch.org ↩
4 https://github.com/BVLC/caffe ↩
5 https://developer.apple.com/documentation/metal/compute_processing/about_threads_and_threadgroups ↩
6 https://developer.apple.com/library/content/documentation/Miscellaneous/Conceptual/MetalProgrammingGuide/Render-Ctx/Render-Ctx.html ↩


