disclosure backend static
1.0.0
disclosure-backend-static存储库是为 Open Disclosure California 提供支持的后端。
它是在 2016 年大选之前仓促创建的,因此是围绕“完成任务”的理念设计的。那时,我们已经设计了一个API并构建了(大部分)前端;创建此存储库是为了尽快实施这些内容。
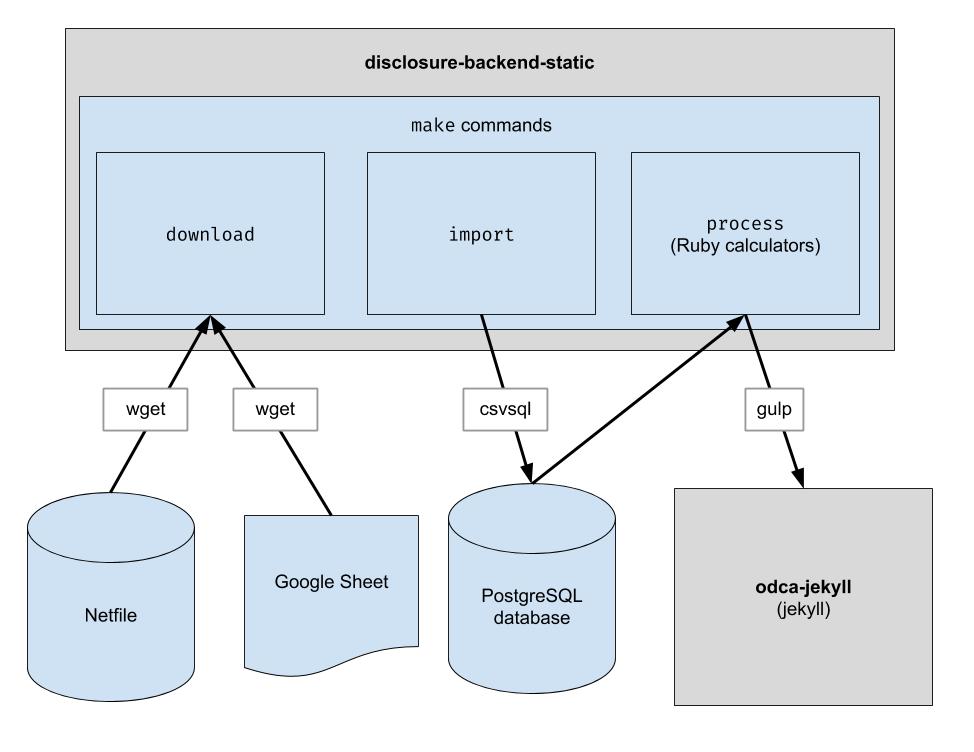
该项目实现了一个基本的 ETL 管道来下载奥克兰网络文件数据、下载奥克兰的 CSV 人工管理数据,并将两者结合起来。输出是一个 JSON 文件目录,它模仿现有的 API 结构,因此不需要更改客户端代码。
.ruby-version中的版本) 注意:您不需要运行这些命令来在前端进行开发。您需要做的就是克隆与前端存储库相邻的存储库。
如果您打算修改后端代码,请按照以下步骤设置所有必要的开发依赖项,包括新的 PostgreSQL 数据库和 Python 3:
brew update && brew upgrade
brew install postgresql@16
brew services start postgresql@16
python3 -m pip而不是pip以确保使用 Python 3: python3 -m pip install ...
pip指向Python 3,你可以直接使用pip : pip install ...
sudo -H python -m pip install -r requirements.txt
gem install pg bundler
bundle install
该存储库设置为在 Codespaces 下的容器中工作。换句话说,您可以启动已设置的环境,而无需执行设置本地环境所需的任何安装步骤。这可以用作在将代码提交到生产管道之前对其进行故障排除的一种方法。以下信息可能有助于开始使用 Codespaces:
Code按钮,然后单击下拉列表中的Codespaces选项卡/workspace处的终端提示,如果您之前使用过 VS Code,这看起来会很熟悉make downloadpsql即可连接到服务器make import命令将填充 Postgres 数据库git push它最终不会出现在 GitHub 存储库中该存储库还配置为在 Docker 容器中运行。这与 Codespaces 类似,只不过您可以使用您喜欢的任何 IDE 和本地设置。以下是如何开始将 Docker 与 VSCode 结合使用:
下载原始数据文件。您只需偶尔运行一次即可获取最新数据。
$ make download
将数据导入数据库以便于处理。您只需在下载新数据后运行此命令。
$ make import
运行计算器。所有内容都输出到“build”文件夹中。
$ make process
(可选)将构建输出重新索引到 Algolia 中。 (重新索引需要 ALGOLIASEARCH_APPLICATION_ID 和 ALGOLIASEARCH_API_KEY 环境变量)。
$ make reindex
如果您想通过本地 Web 服务器提供静态 JSON 文件:
$ make run
运行make import时,会创建许多 postgres 表用于导入下载的数据。这些表的模式在dbschema目录中显式定义,并且将来可能需要更新以适应未来的数据。保存字符串数据的列的大小可能不足以容纳未来的数据。例如,如果名称列最多接受 20 个字符的名称,而将来我们有名称长度为 21 个字符的数据,则数据导入将失败。发生这种情况时,我们将不得不更新dbschema中相应的模式文件以支持更多字符。只需进行更改并重新运行make import即可验证其是否成功。
该存储库用于生成网站使用的数据文件。运行make process后,会生成一个包含数据文件的build目录。该目录被签入存储库,稍后在生成网站时签出。进行代码更改后,将生成的build目录与代码更改之前生成的build目录进行比较并验证代码更改是否符合预期非常重要。
由于对build目录的所有内容的严格比较将始终包括独立于任何代码更改而发生的更改,因此每个开发人员都必须了解这些预期的更改才能执行此检查。为了消除这种需要,特定文件bin/create-digests.py会在排除这些预期更改后在build目录中生成 JSON 数据的摘要。要查找排除这些预期更改的更改,只需在build/digests.json文件中查找更改即可。
目前,这些是独立于任何代码更改而发生的预期更改:
在build目录中的数据摘要之前,将排除预期的更改。其逻辑可以在函数clean_data中找到,该函数位于文件bin/create-digests.py中。修改代码使得预期的更改不再存在后,可以从clean_data中删除对该更改的排除。例如,由于环境的差异,每次运行make process时,浮点数的舍入不一致。当代码被修复后,只要数据没有改变,浮点数的舍入就相同,那么可以删除clean_data中的round_float调用。
已创建一个附加脚本来生成报告,以便比较候选人的总数。该脚本是bin/report-candidates.py ,它生成build/candidates.csv和build/candidates.xlsx 。这些报告包括所有候选人的列表以及通过多种方式计算得出的总数,这些总数应达到相同的数字。
为了确保数据库架构更改在拉取请求中可见,完整的 postgres 架构也会保存到build目录中的schema.sql文件中。由于build目录会自动为 PR 中的每个分支重新构建并提交到存储库,因此在查看 PR 时,由代码更改引起的架构的任何更改都将在schema.sql文件中显示差异。
关于候选人的每个指标都是独立计算的。指标可能是“收到的捐款总额”之类的东西,也可能是更复杂的东西,例如“少于 100 美元的捐款百分比”。
添加新计算时,最好首先从官方表格 460 开始。您要查找的数据是否报告在该表格上?如果是这样,您可能会在导入过程后在数据库中找到它。我们还导入了一些其他表格,例如表格 496。(这些是input目录中文件的名称。检查一下。)
每个表单的每个时间表都会导入到单独的 postgres 表中。例如,表格 460 的附表 A 被导入到A-Contributions表中。
现在您已经有了查询数据的方法,您应该提出一个 SQL 查询来计算您想要获取的值。一旦您可以将计算表达为 SQL,请将其放入计算器文件中,如下所示:
calculators/[your_thing]_calculator.rb的新文件 # the name of this class _must_ match the filename of this file, i.e. end
# with "Calculator" if the file ends with "_calculator.rb"
class YourThingCalculator
def initialize ( candidates : [ ] , ballot_measures : [ ] , committees : [ ] )
@candidates = candidates
@candidates_by_filer_id = @candidates . where ( '"FPPC" IS NOT NULL' )
. index_by { | candidate | candidate [ 'FPPC' ] }
end
def fetch
@results = ActiveRecord :: Base . connection . execute ( <<-SQL )
-- your sql query here
SQL
@results . each do | row |
# make sure Filer_ID is returned as a column by your query!
candidate = @candidates_by_filer_id [ row [ 'Filer_ID' ] . to_i ]
# change this!
candidate . save_calculation ( :your_thing , row [ column_with_your_desired_data ] )
end
end
endFiler_ID列。candidate.save_calculation的调用。该方法会将其第二个参数序列化为 JSON,因此它可以存储任何类型的数据。candidate.calculation(:your_thing)检索您的计算结果。您需要将其添加到process.rb文件中的 API 响应中。 这就是数据流经后端的方式。财务数据从 Netfile 中提取,并辅以 Google Sheet,将 Filer Id 映射到投票信息,如候选人姓名、办公室、投票措施等。一旦数据被过滤、聚合和转换,前端就会使用它并构建静态 HTML前端。
捆绑安装期间
error: use of undeclared identifier 'LZMA_OK'
尝试:
brew unlink xz
bundle install
brew link xz
make download期间
wget: command not found
运行brew install wget 。
在make import期间
使用 Apple 芯片的 Macintosh 系统似乎存在问题。
ImportError: You don't appear to have the necessary database backend installed for connection string you're trying to use. Available backends include:
PostgreSQL: pip install psycopg2
请尝试以下操作:
pip uninstall psycopg2-binary
pip install psycopg2-binary --no-cache-dir


