metal flash attention
v1.0.1
该存储库将 FlashAttention 的官方实现移植到 Apple 芯片上。它是一个最小的、可维护的源文件集,可重现 FlashAttention 算法。
仅单头注意力,关注不同注意力算法的核心瓶颈(寄存器压力、并行性)。正确完成基本算法后,添加块稀疏性等自定义内容应该相对简单。
一切都是在运行时编译的。这与之前的实现形成鲜明对比,后者依赖于 Xcode 14.2 中嵌入的可执行文件。
向后传递比 Dao-AILab/flash-attention 使用更少的内存。官方实现为原子和部分和分配临时空间。 Apple 硬件缺乏原生 FP32 原子(模拟metal::atomic<float> )。在试图规避硬件支持不足的同时,FlashAttention-2 后向内核中的带宽和并行化瓶颈也暴露出来。另一种向后传递的设计具有更高的计算成本(7 个 GEMM,而不是 5 个 GEMM)。它在注意力矩阵的行和列维度上实现了 100% 的并行化效率。最重要的是,它更容易编码和维护。
为了克服寄存器压力瓶颈,我们做了很多疯狂的事情。当头尺寸较大时(例如 256),没有任何矩阵块可以装入寄存器。甚至累加器也不能。因此,有意进行寄存器溢出,但以更优化的方式进行。注意力算法中添加了第三个块维度,该维度沿着D进行块化。注意力矩阵块的纵横比被严重扭曲,以最大限度地减少寄存器溢出的带宽成本。例如,沿并行化维度为 16-32,沿遍历维度为 80-128。有一个很大的参数文件,它采用D维度,并确定哪些操作数可以放入寄存器中。然后,它分配一个块大小来平衡许多竞争瓶颈。
最终结果是在 M1 Max 上每秒稳定执行 4400 条千兆指令(ALU 利用率为 83%),并且序列长度和头部尺寸无限。假设 BF16 仿真用于混合精度(Metal 的bfloat具有符合 IEEE 规范的舍入,这是没有硬件 BF16 的旧芯片的主要开销)。
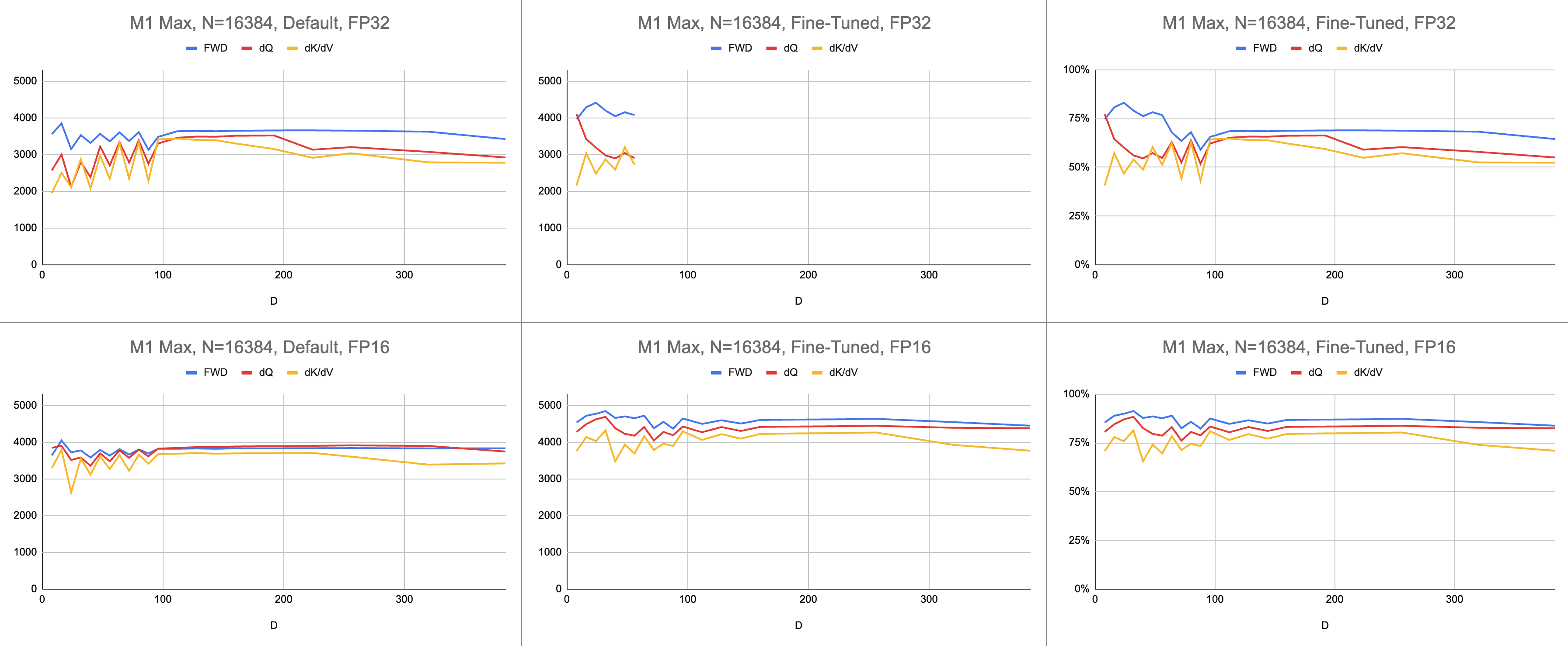
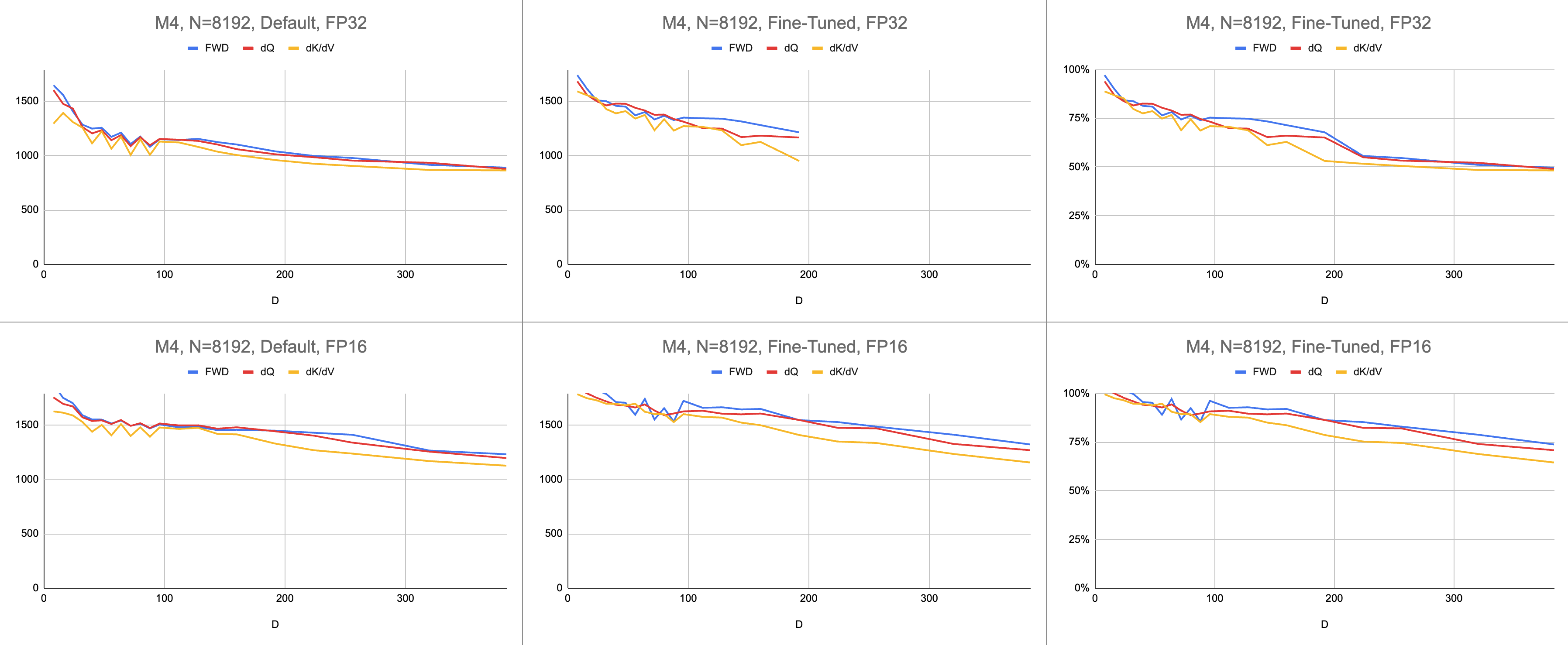
原始数据:https://docs.google.com/spreadsheets/d/1Xf4jrJ7e19I32J1IWIekGE9uMFTeZKoOpQ6hlUoh-xY/edit?usp=sharing
在人工智能领域,性能最常以每秒千兆浮点运算(GFLOPS)来报告。该指标反映了简化的性能模型,即每条指令都发生在 GEMM 中。随着硬件从早期的 FPU 发展到现代向量处理器,最常见的浮点运算被融合到单个指令中。融合乘加 (FMA)。当两个 100x100 矩阵相乘时,会发出 100 万条 FMA 指令。为什么我们必须将这个 FMA 视为两个单独的指令?
这个问题与注意力相关,其中并非所有浮点运算都是相同的。假定大多数其他指令都进入 FMA 单元,softmax 期间的求幂发生在单个时钟周期内。 softmax 期间的一些乘法和加法不能与附近的加法或乘法融合。我们是否应该将它们视为 FMA,并假装硬件执行 FMA 的速度减慢两倍?目前尚不清楚 GEMM 性能模型如何解释我的着色器是否有效地使用 ALU 硬件。
我使用千兆指令来了解着色器的性能,而不是千兆浮点运算。它更直接地映射到算法。例如,一个GEMM是N^3 FMA指令。前向注意力执行两个矩阵乘法,或2 * D * N^2 FMA 指令。后向注意力(由 Dao-AILab/flash-attention 实现)是5 * D * N^2 FMA 指令。尝试将此表与 Flash1、Flash2 或 Flash3 论文中的屋顶线模型进行比较。
| 手术 | 工作 |
|---|---|
| 方形GEMM | N^3 |
| 前向关注 | (2D + 5) * N^2 |
| 落后的天真注意力 | 4D * N^2 |
| 向后闪光注意 | (5D + 5) * N^2 |
| 前轮驱动 + 后轮驱动组合 | (7D + 10) * N^2 |
由于 FP32 原子的复杂性,MFA 使用了不同的方法进行后向传递。这具有较高的计算成本。它将向后传递分成两个单独的内核: dQ和dK/dV 。下拉列表显示伪代码。将此与 Flash1、Flash2 或 Flash3 论文中的算法之一进行比较。
| 手术 | 工作 |
|---|---|
| 向前 | (2D + 5) * N^2 |
| 后向dQ | (3D + 5) * N^2 |
| 后向dK/dV | (4D + 5) * N^2 |
| 前轮驱动 + 后轮驱动组合 | (9D + 15) * N^2 |
// Forward
// for c in 0..<C {
// load K[c]
// S = Q * K^T
// (m, l, P) = softmax(m, l, S * scaleFactor)
//
// O *= correction
// load V[c]
// O += P * V
// }
// O /= l
//
// L = m + logBaseE(l)
//
// Backward Query
// D = dO * O
//
// for c in 0..<C {
// load K[c]
// S = Q * K^T
// P = exp(S - L)
//
// load V[c]
// dP = dO * V^T
// dS = P * (dP - D) * scaleFactor
//
// load K[c]
// dQ += dS * K
// }
//
// Backward Key-Value
// for r in 0..<R {
// load Q[r]
// load L[r]
// S^T = K * Q^T
// P^T = exp(S^T - L)
//
// load dO[r]
// dV += P^T * dO
//
// load dO[r]
// load D[r]
// dP^T = V * dO^T
// dS^T = P^T * (dP^T - D) * scaleFactor
//
// load Q[r]
// dK += dS^T * Q
// }性能是通过计算计算工作量然后除以秒来衡量的。最终结果是“每秒千兆指令”。接下来,我们需要一个屋顶线模型。下表显示了 GINSTRS 的屋顶线,以 GFLOPS 的一半计算。 ALU 利用率为(每秒实际千兆指令)/(每秒预期千兆指令)。例如,M1 Max 通常可实现 80% 的 ALU 利用率和混合精度。
该模型存在局限性。它在 M3 一代中因头部尺寸较小而崩溃。不同的计算单元可以同时使用,使表观利用率超过100%。在大多数情况下,基准测试提供了一个准确的模型,表明还剩下多少性能。
var operations : Int
switch benchmarkedKernel {
case . forward :
operations = 2 * headDimension + 5
case . backwardQuery :
operations = 3 * headDimension + 5
case . backwardKeyValue :
operations = 4 * headDimension + 5
}
operations *= ( sequenceDimension * sequenceDimension )
operations *= dispatchCount
// Divide the work by the latency, resulting in throughput.
let instrs = Double ( operations ) / Double ( latencySeconds )
let ginstrs = Int ( instrs / 1e9 )| 硬件 | 浮点运算次数 | 金斯瑞 |
|---|---|---|
| M1最大 | 10616 | 5308 |
| M4 | 3580 | 1790 |
Metal 端口与官方 FlashAttention 存储库相比效果如何?想象一下,我采用“原子 dQ”算法并实现了 100% 的性能。然后,切换到实际的 MFA 存储库,发现模型训练速度慢了 4 倍。这将占官方存储库屋顶线的 25%。要获得此百分比,请将所有三个内核的平均 ALU 利用率乘以7 / 9 。苹果硬件的统计数据使用了一个更细致的模型,但这就是它的要点。
为了计算 Nvidia 硬件的利用率,我使用 FP16/BF16 ALU 的 GFLOPS。我将论文中每张图中的最高 GFLOPS 除以 312000 (A100 SXM)、989000 (H100 SXM)。请注意,对于较大的头部尺寸和寄存器密集型内核(向后传递),没有报告基准。我确认他们没有解决无限头部尺寸的套准压力问题。例如,累加器始终保存在寄存器中。在撰写本文时,我还没有看到 D=256 反向梯度执行并获得正确结果的具体证据。
| A100、Flash2、FP16 | d = 64 | d = 128 | d = 256 |
|---|---|---|---|
| 向前 | 192000 | 223000 | 0 |
| 落后 | 170000 | 196000 | 0 |
| 前进+后退 | 176000 | 203000 | 0 |
| H100、Flash3、FP16 | d = 64 | d = 128 | d = 256 |
|---|---|---|---|
| 向前 | 497000 | 648000 | 756000 |
| 落后 | 474000 | 561000 | 0 |
| 前进+后退 | 480000 | 585000 | 0 |
| H100、Flash3、FP8 | d = 64 | d = 128 | d = 256 |
|---|---|---|---|
| 向前 | 613000 | 1008000 | 1171000 |
| 落后 | 0 | 0 | 0 |
| 前进+后退 | 0 | 0 | 0 |
| A100、Flash2、FP16 | d = 64 | d = 128 | d = 256 |
|---|---|---|---|
| 向前 | 62% | 71% | 0% |
| 前进+后退 | 56% | 65% | 0% |
| H100、Flash3、FP16 | d = 64 | d = 128 | d = 256 |
|---|---|---|---|
| 向前 | 50% | 66% | 76% |
| 前进+后退 | 48% | 59% | 0% |
| M1架构,FP16 | d = 64 | d = 128 | d = 256 |
|---|---|---|---|
| 向前 | 86% | 85% | 86% |
| 前进+后退 | 62% | 63% | 64% |
| M3架构,FP16 | d = 64 | d = 128 | d = 256 |
|---|---|---|---|
| 向前 | 94% | 91% | 82% |
| 前进+后退 | 71% | 69% | 61% |
| 2020年生产的硬件 | d = 64 | d = 128 | d = 256 |
|---|---|---|---|
| A100 | 56% | 65% | 0% |
| M1—M2架构 | 62% | 63% | 64% |
| 2023 年生产的硬件 | d = 64 | d = 128 | d = 256 |
|---|---|---|---|
| H100(使用 FP8 GFLOPS) | 24% | 30% | 0% |
| H100(使用 FP16 GFLOPS) | 48% | 59% | 0% |
| M3—M4架构 | 71% | 69% | 61% |
尽管进行了更多的计算,Apple 硬件训练 Transformer 的速度比执行相同工作的 Nvidia 硬件更快。针对不同 GPU 之间的大小差异进行标准化。只需关注 GPU 的利用效率即可。
也许主存储库应该尝试避免 FP32 原子的算法,并在寄存器无法容纳 GPU 核心时故意溢出寄存器。这似乎不太可能,因为它们对可能问题大小的一小部分提供了硬编码支持。动机似乎是支持最常见的模型,其中D是 2 的幂,并且小于 128。对于其他任何事情,用户需要依赖替代的后备实现(例如 MFA 存储库),这可能使用完全不同的底层算法。
在 macOS 上,下载 Swift 包并使用-Xswiftc -Ounchecked进行编译。对性能敏感的 CPU 代码需要此编译器选项。不能使用发布模式,因为它会强制每次发生单个更改时从头开始重新编译整个代码库。在 Finder 中导航到 Git 存储库,然后双击Package.swift 。应该会弹出一个 Xcode 窗口。左边应该有一个文件层次结构。如果你无法解开层次结构,那就说明出了问题。
git clone https://github.com/philipturner/metal-flash-attention
swift build -Xswiftc -Ounchecked # Does it even compile?
swift test -Xswiftc -Ounchecked # Does the test suite finish in ~10 seconds?
或者,使用 SwiftUI 模板创建一个新的 Xcode 项目。覆盖"Hello, world!" string 并调用返回String的函数。此函数将执行您选择的脚本,然后调用exit(0) ,因此应用程序在将任何内容渲染到屏幕之前崩溃。您将使用 Xcode 控制台中的输出作为有关代码的反馈。此工作流程与 macOS 和 iOS 兼容。
通过Project > your project's name > Build Settings > Swift Compiler - Code Generation > Optimization Level添加-Xswiftc -Ounchecked选项。表的第二列列出了您的项目名称。单击下拉列表中的“其他” ,然后在出现的面板中键入-Ounchecked 。接下来,将此存储库添加为 Swift 包依赖项。查看Tests/FlashAttention下的一些测试。将这些测试之一的原始源代码复制到您的项目中。从上一段中的函数调用测试。检查控制台上显示的内容。
要修改 Metal 代码生成(例如添加多头或掩模支持),请将原始 Swift 代码复制到您的 Xcode 项目中。可以在单独的文件夹中使用git clone ,也可以在 GitHub 上以 ZIP 形式下载原始文件。还有一种方法可以链接到您的metal-flash-attention分支并将您的更改自动保存到云端,但这更难以设置。删除上一段中的 Swift 包依赖项。重新运行您选择的测试。它会编译并在控制台中显示某些内容吗?
在以下任一文件夹中找到多行字符串文字之一:
Sources/FlashAttention/Attention/AttentionKernel
Sources/FlashAttention/GEMM/GEMMKernel
将随机文本添加到其中之一。再次编译并运行该项目。应该出了严重的问题。例如,Metal 编译器可能会抛出错误。如果这种情况没有发生,请尝试在其他地方弄乱另一行代码。如果测试仍然通过,则 Xcode 不会注册您的更改。
继续对块稀疏性或其他内容进行编码。获取有关代码是否完全有效、是否快速工作、是否在每个问题大小上都快速工作的反馈。将原始源代码集成到您的应用程序中,或将其翻译为另一种编程语言。


