eye in the sky
1.0.0
卫星图像分类,InterIIT Techmeet 2018,IIT 孟买。
团队:Manideep Kolla、Aniket Mandle、Apoorva Kumar
该存储库包含两种算法的实现,即 U-Net:用于生物医学图像分割的卷积网络和针对卫星图像分类问题进行修改的金字塔场景解析网络。
main_unet.py :用于使用 U-Net 架构训练算法的 Python 代码,包括基本事实的编码。unet.py :包含我们对 U-Net 层的实现。test_unet.py :用于测试、计算精度、计算训练和验证的混淆矩阵以及保存 U-Net 模型对训练、验证和测试图像的预测的代码。Inter-IIT-CSRE :包含所有训练、验证和测试数据。Comparison_Test.pdf :将测试数据与 U-Net 模型对数据的预测进行并排比较。train_predictions :U-Net 模型对训练和验证图像的预测。plots :U-Net 架构训练和验证的准确性和损失图。Test_images 、 Test_outputs :包含测试图像及其 U-Net 模型的预测。class_masks 、 compare_pred_to_gt 、 images_for_doc :包含用于文档的多个图像。PSPNet :包含用于实现卫星图像分类 PSPNet 算法的训练文件。 克隆存储库,将当前工作目录更改为克隆的目录。创建名为train_predictions和test_outputs的文件夹,以保存训练和测试图像上的模型预测输出(现在不需要,因为存储库已包含这些文件夹)
$ git clone https://github.com/manideep2510/eye-in-the-sky.git
$ cd eye-in-the-sky
$ mkdir train_predictions
$ mkdir test_outputs
要训练 U-Net 模型并节省权重,请运行以下命令
$ python3 main_unet.py
测试 U-Net 模型,计算准确性,计算训练和验证的混淆矩阵,并保存模型对训练、验证和测试图像的预测。
$ python3 test_unet.py
运行我们的代码时,您可能会收到错误xrange is not defined 。这个错误不是由于我们的代码中的错误引起的,而是由于名为libtiff的 python 包不是最新的(该包的源代码的某些部分在 python2 中,一些在 python3 中),我们用来读取数据集,其中图像为 .tif 格式。我们无法使用 openCV 或 PIL 等其他库来读取图像,因为它们无法正确支持读取 4 通道 .tif 图像。
可以通过编辑libtiff库的源代码来解决此错误。
转到出现错误的库源代码中的文件(显示错误时文件名将显示在终端中)并将文件中的所有xrange() (python2) 函数替换为range() (python3)。
我们在这里提供了一些相当好的预训练权重,以便用户不需要从头开始训练。
| 描述 | 任务 | 数据集 | 模型 |
|---|---|---|---|
| UNet架构 | 卫星图像分类 | IITB 数据集(请参阅Inter-IIT-CSRE文件夹) | 下载(.h5) |
要使用预先训练的权重,请更改test_unet.py中提到的 .h5(权重文件)文件的名称,以匹配您在需要时下载的权重文件的名称。
现在我们来讨论一下
1. 这个项目是关于什么的,
2.我们使用和试验过的架构
3. 我们在项目中使用的一些新颖的训练策略
遥感是从远处(通常是从飞机或卫星)获取有关物体或区域信息的科学。
我们将卫星图像分类问题理解为语义分割问题,并在深度学习中构建了语义分割算法来解决这个问题。
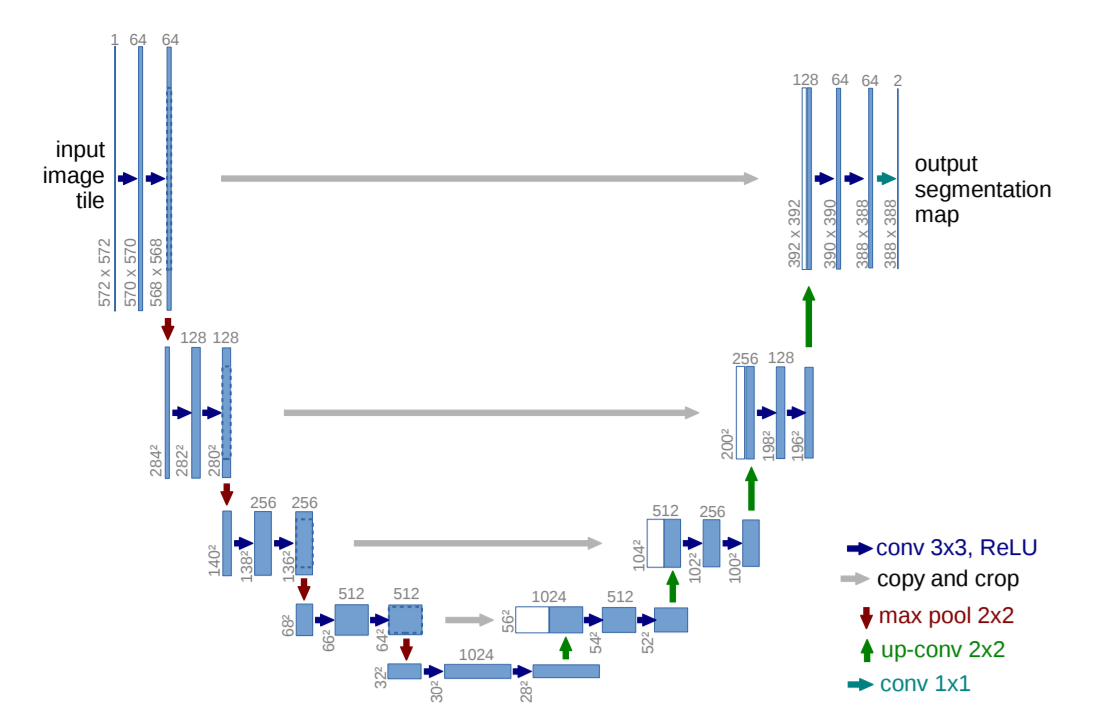
U-Net:用于生物医学图像分割的卷积网络
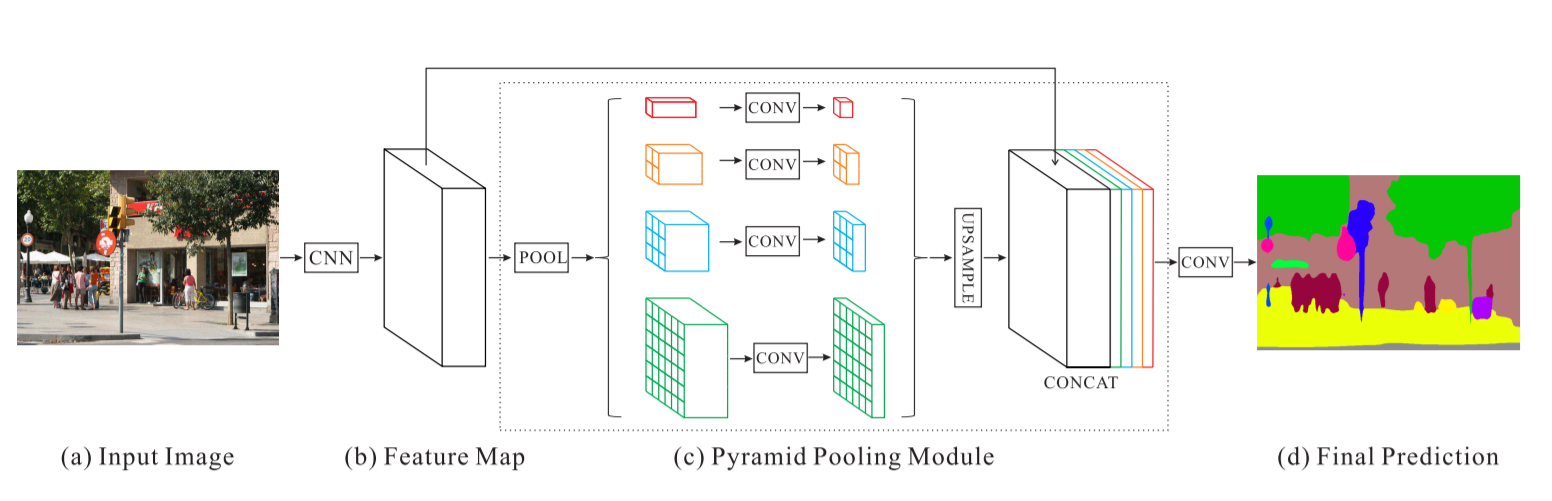
金字塔场景解析网络 - PSPNet
提供的基本事实是 3 通道 RGB 图像。在当前数据集中,基本事实中只有 9 个唯一的 RGB 值,因为有 9 个类别需要分类。这 9 个不同的 RGB 值经过 one-hot 编码,生成 9 通道编码的基本事实,每个通道代表一个特定类别。
下面是编码方案
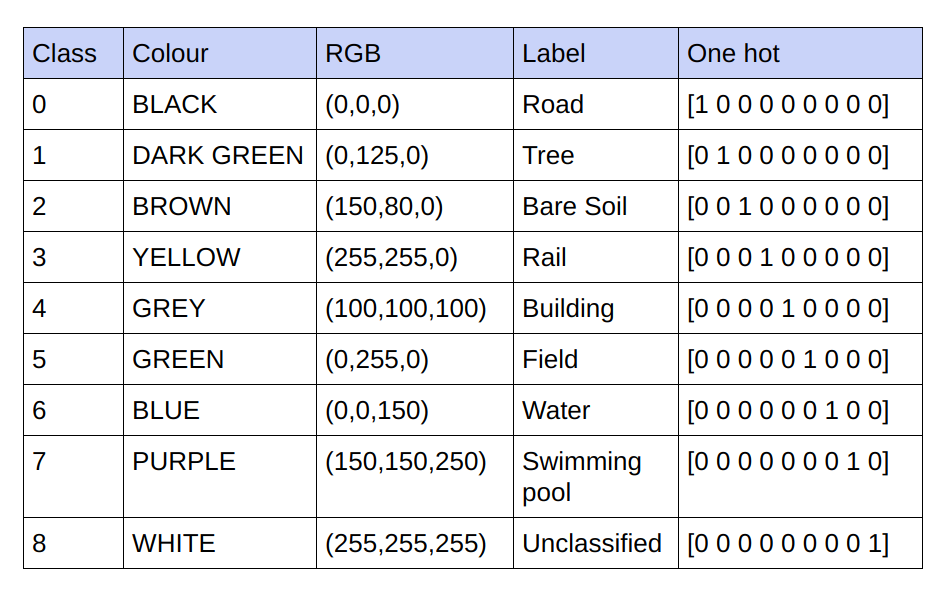
将编码的地面实况中的每个通道实现为一个类

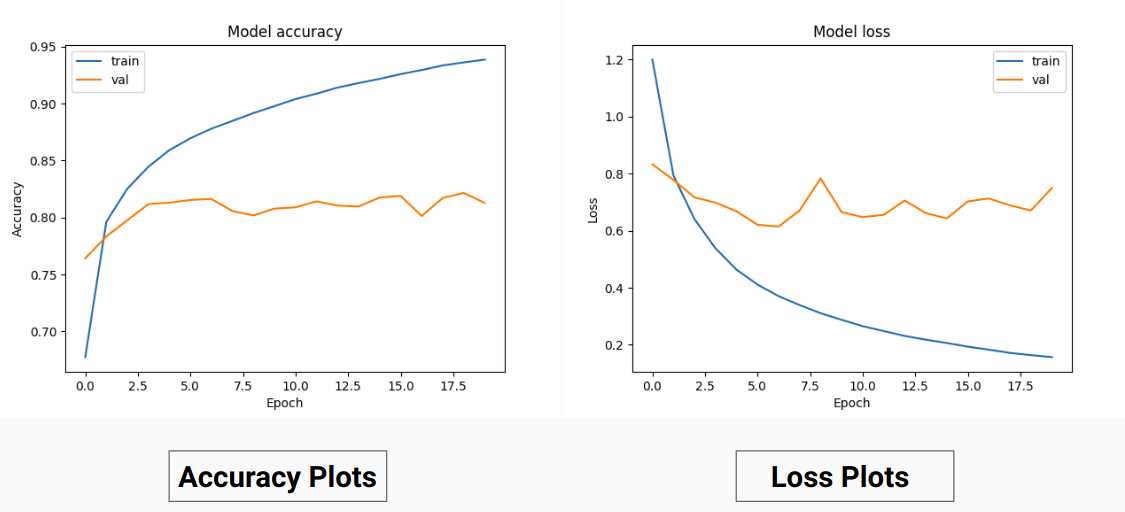
因此,我们没有对真实值的 RGB 值进行训练,而是将它们转换为不同类别的 one-hot 值。这种方法使我们的验证准确率达到 85%,训练准确率达到 92%,而当我们使用 RGB 真实值进行训练时,验证准确度为 71%,训练准确度为 65%。
这可能是由于训练数据的基本事实的方差和均值减少,因为它充当了有效的标准化技术。这种训练技术的更好性能还因为该模型给出了带有 9 个特征图的输出,每个图指示一个类,即,这种训练技术的作用就好像模型在某种程度上分别在 9 个类中的每一个上进行训练(但在这里,对应于特定类别的一个通道的预测肯定取决于其他通道) 。
我们在 PSPNet 上进行卫星图像分类的结果:
训练准确度 - 49% 验证准确度 - 60%
理由:
U网:
修改后的U-Net:
为了进行训练和验证,我们使用了Inter-IIT-CSRE/The-Eye-in-the-Sky-dataset文件夹中的 14 个“.tif”图像。
为了进行训练,我们使用了数据集中的前 13 张图像,为了验证,我们使用了第 14 张图像。
sat文件夹中的每个卫星图像包含 4 个通道,即 R(波段 1)、G(波段 2)、B(波段 3)和 NIR(波段 4)。
gt目录中的地面真实图像是 RGB 图像,描绘了 8 个类别 - 道路、建筑物、树木、草地、裸土、水、铁路和游泳池
我们只考虑一张图像(第 14 张图像)作为验证集的原因是它是数据集中最小的图像之一,并且我们不想留下更少的数据用于训练,因为数据集非常小。我们考虑的验证集(第 14 张图像)中不存在具有相当高训练精度的 3 个类别(裸土、铁路、游泳民意调查)。如果我们考虑一张包含所有类的图像(数据集中没有图像包含所有类,所有图像中至少缺少一个类),验证准确性会更好。
跨步裁剪:
为了从给定的高清图像中获得足够的训练数据,需要进行裁剪来训练分类器,该分类器具有 U-Net 实现的约 31M 参数。我们发现 64x64 的裁剪尺寸对各个类的代表性不足,并且对象的几何形状和连续性丢失,从而减少了卷积的视野。
使用 128x128 像素的裁剪窗口,步幅为 32,生成 15887 个训练 414 个验证图像。
图像尺寸:
在裁剪之前,训练图像的尺寸被转换为步幅的倍数,以方便跨步裁剪。
对于没有的情况。作物的数量不是我们最初尝试零填充的图像尺寸的倍数,我们意识到添加填充会在训练和测试图像中以黑色像素的形式添加不需要的伪影,从而导致对错误数据和图像边界进行训练。
或者,我们通过在图像的最右侧和底部添加额外的像素来正确更改图像尺寸。因此,我们将图像最左侧的差异填充到其右侧的缺陷端,图像的顶部和底部也是如此。
训练示例 1:训练数据中的图像“2.tif”
训练示例 2:训练数据中的图像“4.tif”
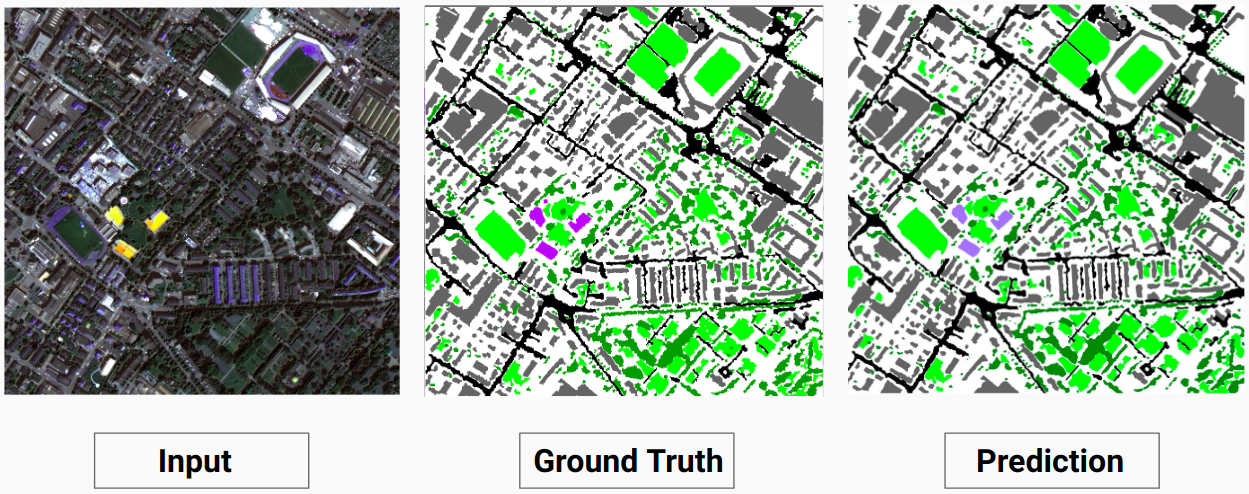
验证示例:数据集中的图像“14.tif”

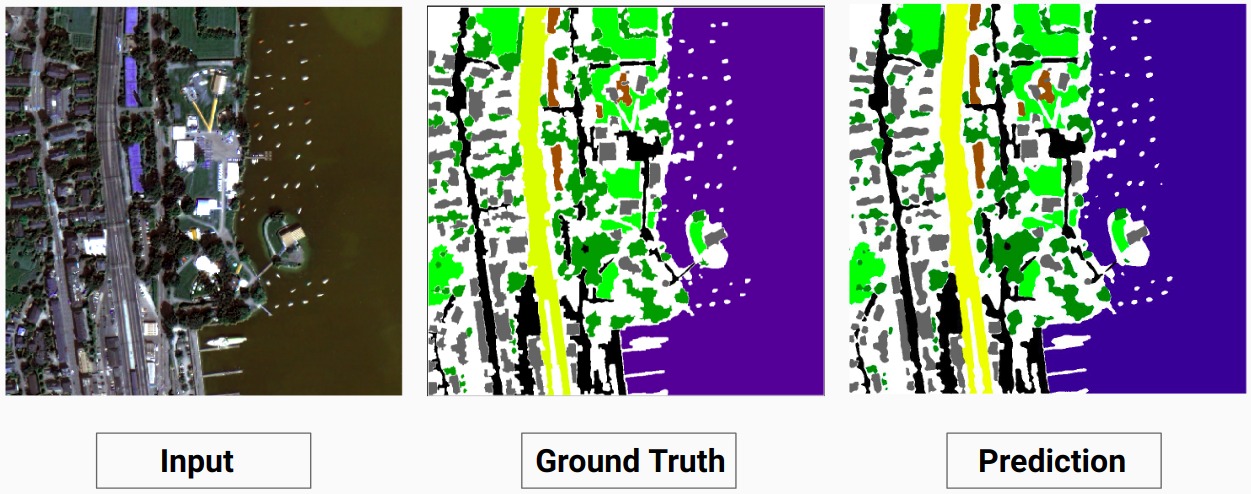
我们的模型能够预测人类注释者无法预测的一些类。图像中无法识别的类别被人类注释者标记为白色像素。我们的模型能够将其中一些白色像素正确预测为某个类别,但这会导致整体精度下降,因为模型将白色像素视为单独的类别。
这里,模型能够将白色像素预测为建筑物,这是正确的并且可以在输入图像中清楚地看到
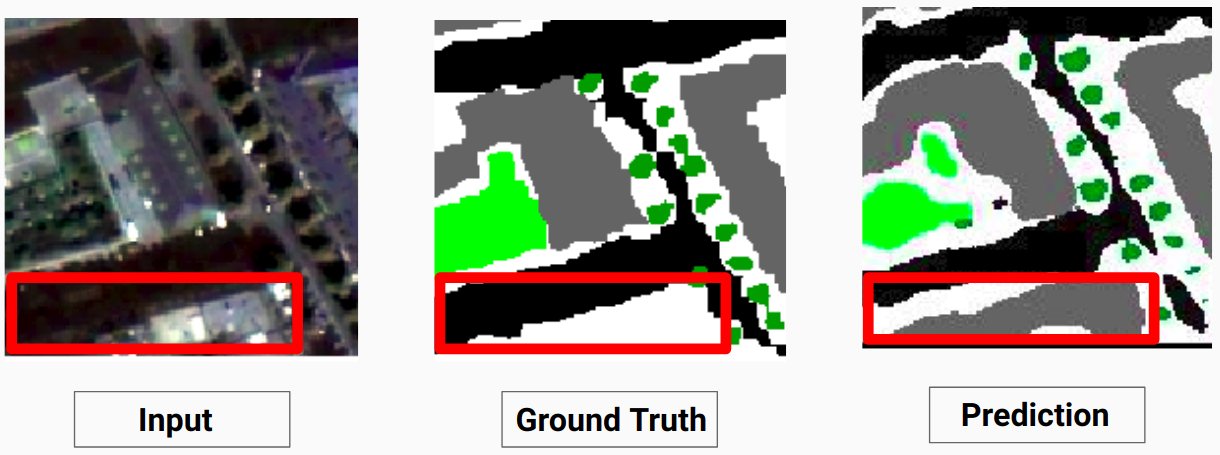
查看Comparison_Test.pdf以比较测试图像与模型预测的输出
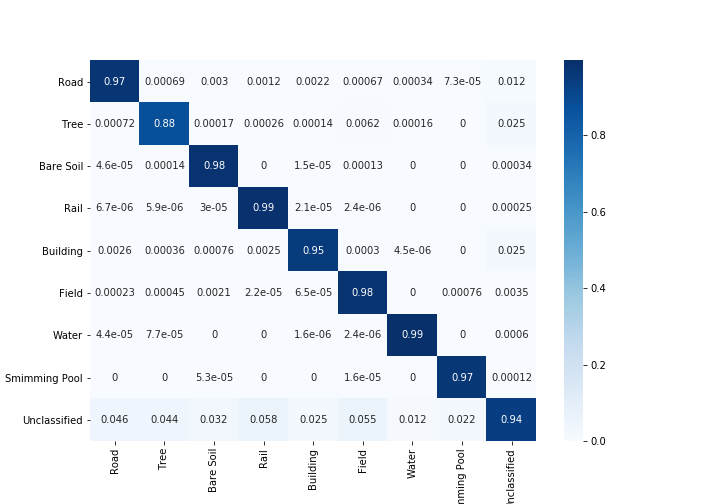
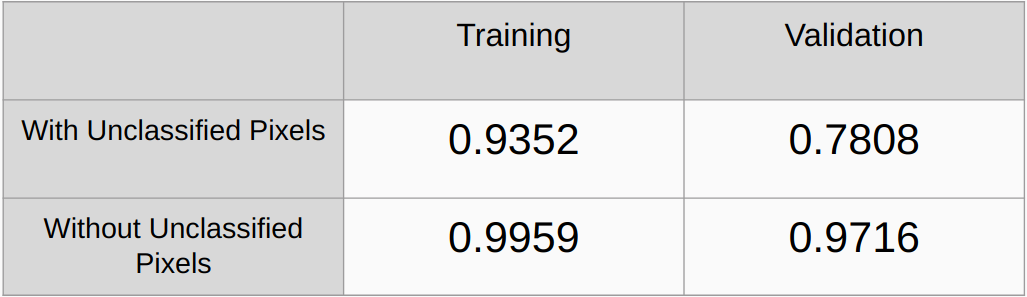
考虑和不考虑未分类像素的 Kappa 系数
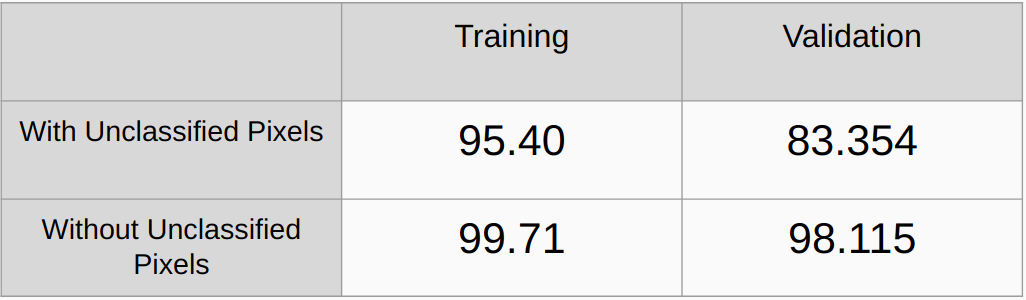
考虑和不考虑未分类像素的总体精度
需要添加L2正则化和dropout等正则化方法并检查性能
实现一种算法来自动检测基本事实中的所有唯一 RGB 值并对它们进行 onehot 编码,而不是手动查找 RGB 值。
[1] U-Net:用于生物医学图像分割的卷积网络,Olaf Ronneberger、Philipp Fischer 和 Thomas Brox
[2] 金字塔场景解析网络,赵恒双,石建平,齐小娟,王小刚,贾佳雅
[3] 2017 年深度学习语义分割指南,Sasank Chilamkurthy


