vit pytorch
1.9.1
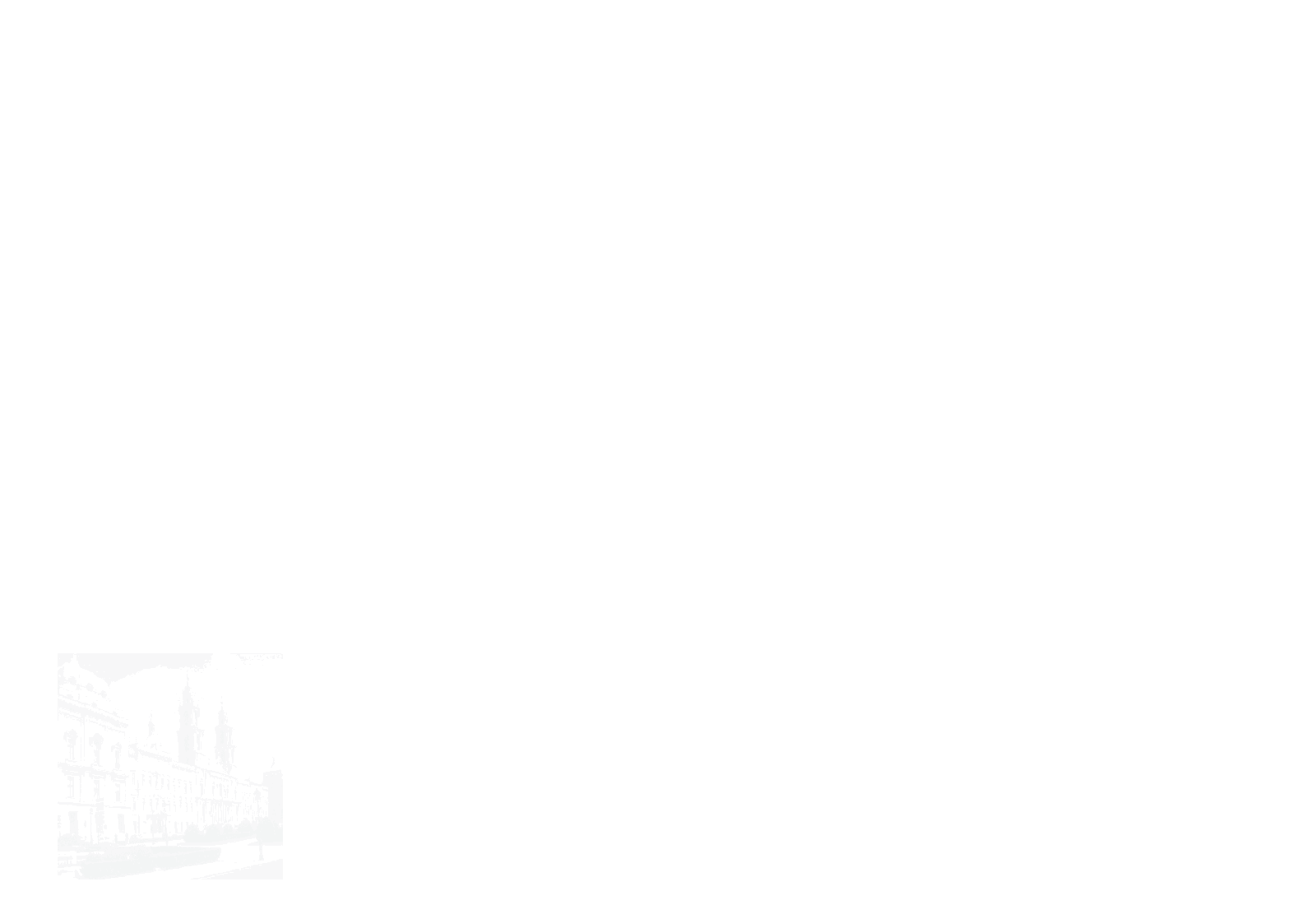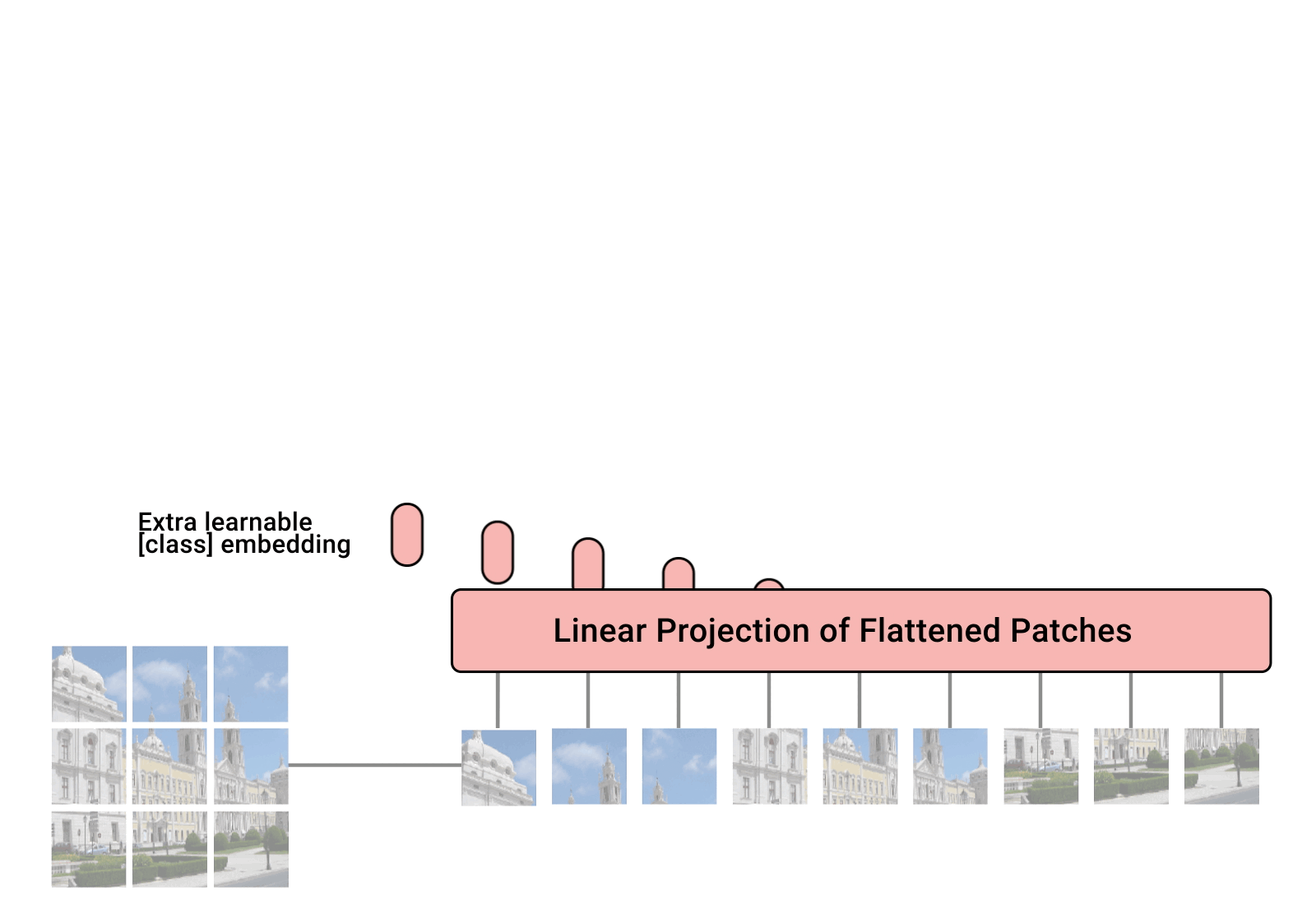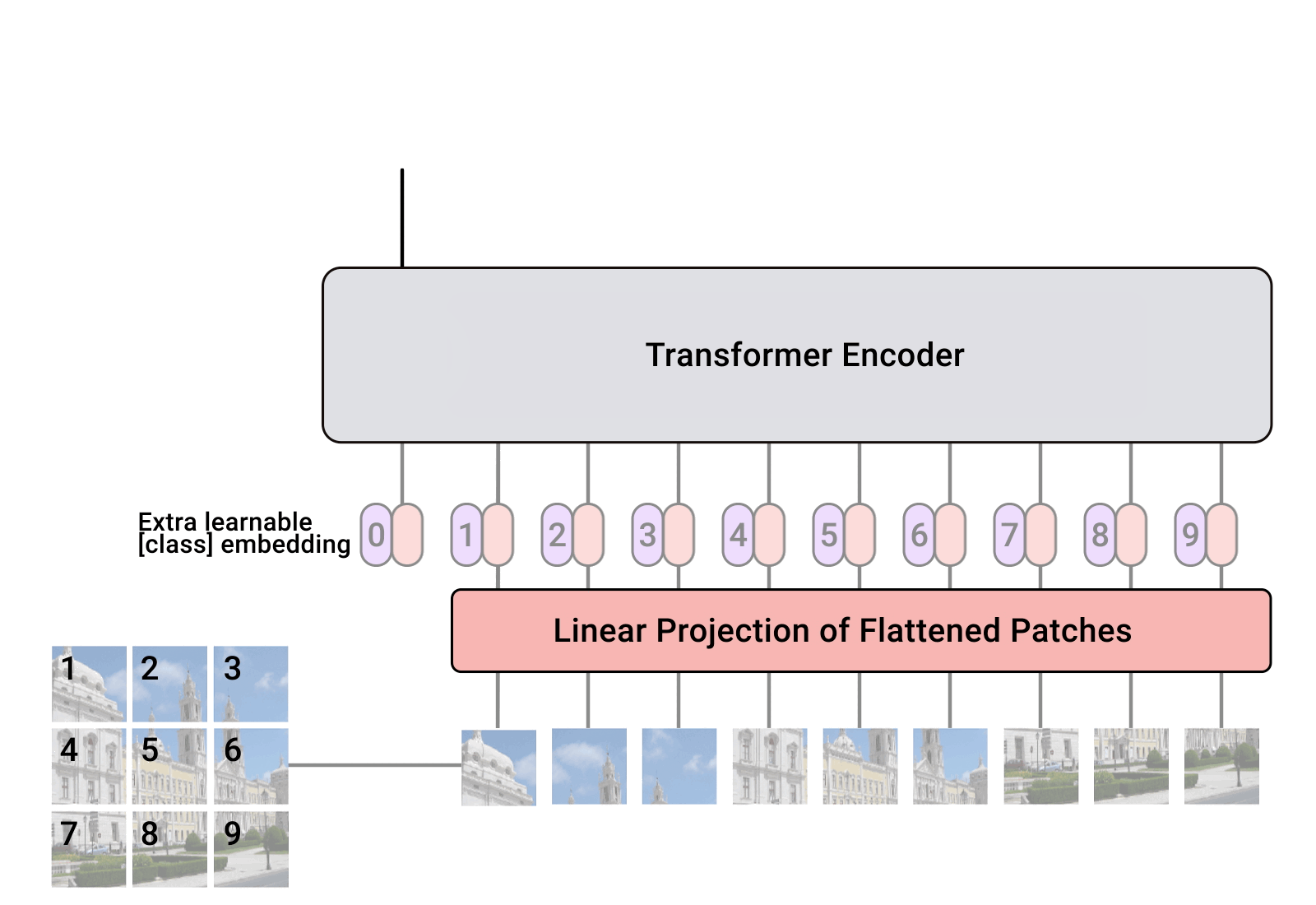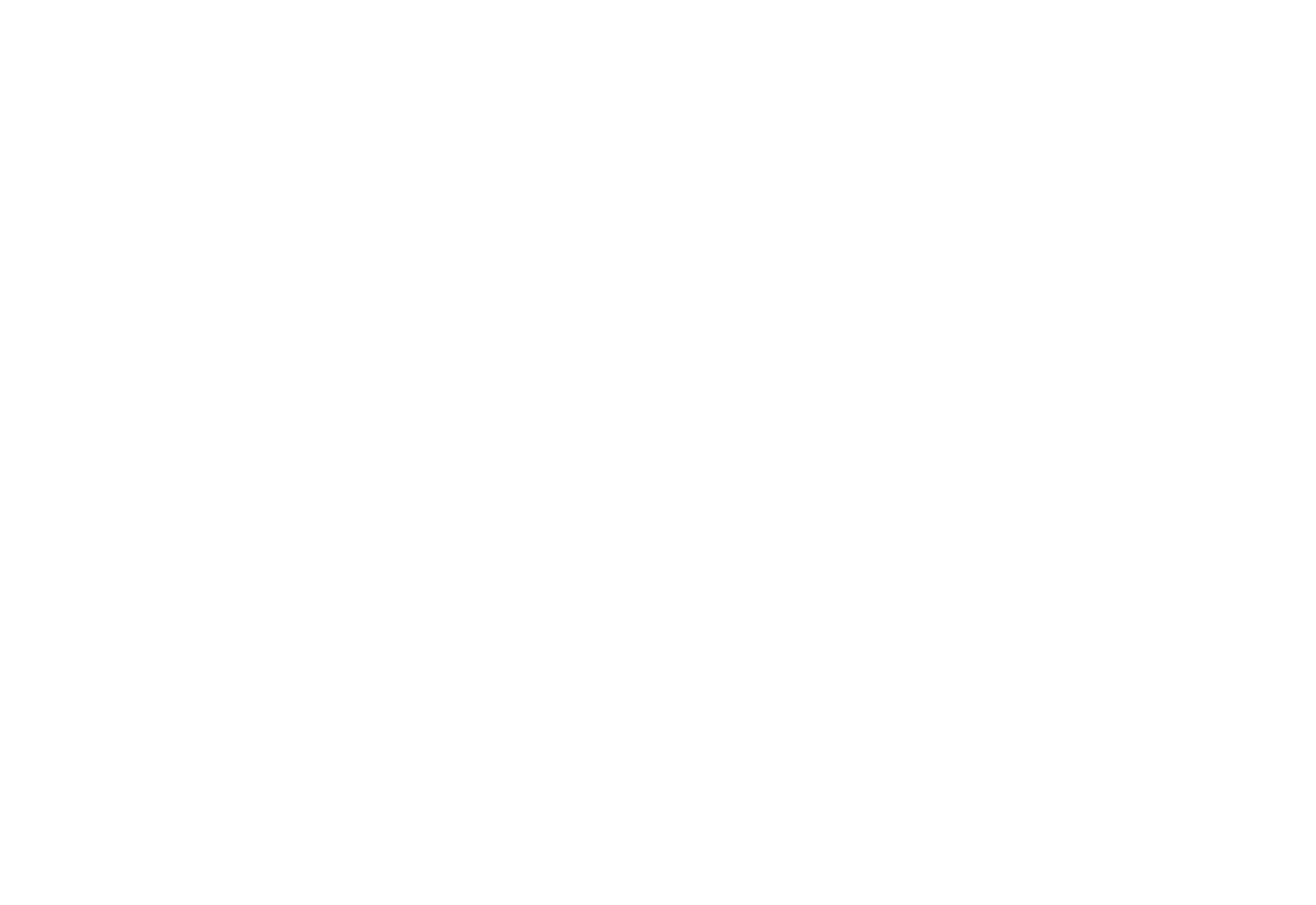
在 Pytorch 中实现 Vision Transformer,这是一种仅使用单个 Transformer 编码器即可在视觉分类中实现 SOTA 的简单方法。 Yannic Kilcher 的视频进一步解释了其意义。这里确实没有太多需要编码的内容,但不妨为每个人展示一下,以便我们加快注意力革命。
有关预训练模型的 Pytorch 实现,请参阅此处 Ross Wightman 的存储库。
官方 Jax 存储库位于此处。
这里还存在由研究科学家 Junho Kim 创建的 tensorflow2 翻译!
Enrico Shippole 的亚麻翻译!
$ pip install vit-pytorch import torch
from vit_pytorch import ViT
v = ViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 1 , 3 , 256 , 256 )
preds = v ( img ) # (1, 1000) image_size :整数。patch_size :整数。image_size必须能被patch_size整除。n = (image_size // patch_size) ** 2并且n必须大于 16 。num_classes :整数。dim :int。nn.Linear(..., dim) 。depth :整数。heads :int。mlp_dim :整数。channels :int,默认3 。dropout : 在[0, 1]之间浮动,默认0. ..emb_dropout :在[0, 1]之间浮动,默认0 。pool : 字符串, cls令牌池或mean池原论文的一些同一作者的更新提出了对ViT简化,使其能够更快更好地训练。
这些简化包括 2d 正弦位置嵌入、全局平均池化(无 CLS 令牌)、无 dropout、批量大小为 1024 而不是 4096,以及使用 RandAugment 和 MixUp 增强。他们还表明,末端的简单线性并不比原始 MLP 头明显差
您可以通过导入SimpleViT来使用它,如下所示
import torch
from vit_pytorch import SimpleViT
v = SimpleViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048
)
img = torch . randn ( 1 , 3 , 256 , 256 )
preds = v ( img ) # (1, 1000) 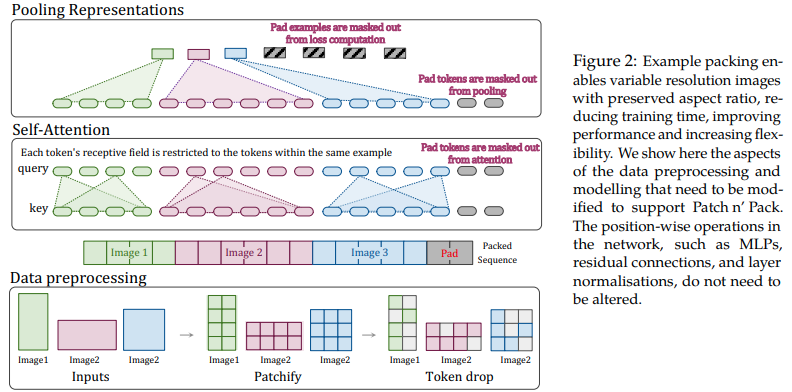
本文提出利用可变长度序列的注意力和掩蔽的灵活性来训练多种分辨率的图像,并将其打包到单个批次中。它们展示了更快的训练速度和更高的准确性,唯一的成本是架构和数据加载的额外复杂性。他们使用因式分解的二维位置编码、令牌删除以及查询键标准化。
您可以按如下方式使用它
import torch
from vit_pytorch . na_vit import NaViT
v = NaViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1 ,
token_dropout_prob = 0.1 # token dropout of 10% (keep 90% of tokens)
)
# 5 images of different resolutions - List[List[Tensor]]
# for now, you'll have to correctly place images in same batch element as to not exceed maximum allowed sequence length for self-attention w/ masking
images = [
[ torch . randn ( 3 , 256 , 256 ), torch . randn ( 3 , 128 , 128 )],
[ torch . randn ( 3 , 128 , 256 ), torch . randn ( 3 , 256 , 128 )],
[ torch . randn ( 3 , 64 , 256 )]
]
preds = v ( images ) # (5, 1000) - 5, because 5 images of different resolution above或者,如果您希望框架自动将图像分组为不超过特定最大长度的可变长度序列
images = [
torch . randn ( 3 , 256 , 256 ),
torch . randn ( 3 , 128 , 128 ),
torch . randn ( 3 , 128 , 256 ),
torch . randn ( 3 , 256 , 128 ),
torch . randn ( 3 , 64 , 256 )
]
preds = v (
images ,
group_images = True ,
group_max_seq_len = 64
) # (5, 1000)最后,如果您想使用嵌套张量的 NaViT 风格(这将完全省略大量掩蔽和填充),请确保您使用的是2.5版本并按如下方式导入
import torch
from vit_pytorch . na_vit_nested_tensor import NaViT
v = NaViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0. ,
emb_dropout = 0. ,
token_dropout_prob = 0.1
)
# 5 images of different resolutions - List[Tensor]
images = [
torch . randn ( 3 , 256 , 256 ), torch . randn ( 3 , 128 , 128 ),
torch . randn ( 3 , 128 , 256 ), torch . randn ( 3 , 256 , 128 ),
torch . randn ( 3 , 64 , 256 )
]
preds = v ( images )
assert preds . shape == ( 5 , 1000 )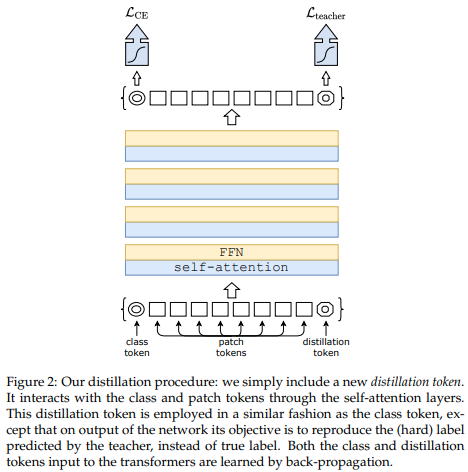
最近的一篇论文表明,使用蒸馏令牌将知识从卷积网络提取到视觉变压器可以产生小型且高效的视觉变压器。该存储库提供了轻松进行蒸馏的方法。
前任。从 Resnet50(或任何教师)中提取到视觉转换器
import torch
from torchvision . models import resnet50
from vit_pytorch . distill import DistillableViT , DistillWrapper
teacher = resnet50 ( pretrained = True )
v = DistillableViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
distiller = DistillWrapper (
student = v ,
teacher = teacher ,
temperature = 3 , # temperature of distillation
alpha = 0.5 , # trade between main loss and distillation loss
hard = False # whether to use soft or hard distillation
)
img = torch . randn ( 2 , 3 , 256 , 256 )
labels = torch . randint ( 0 , 1000 , ( 2 ,))
loss = distiller ( img , labels )
loss . backward ()
# after lots of training above ...
pred = v ( img ) # (2, 1000) DistillableViT类与ViT相同,只是前向传递的处理方式不同,因此您应该能够在完成蒸馏训练后将参数加载回ViT 。
您还可以在DistillableViT实例上使用方便的.to_vit方法来获取ViT实例。
v = v . to_vit ()
type ( v ) # <class 'vit_pytorch.vit_pytorch.ViT'> 本文指出,ViT 很难在更大的深度(过去 12 层)进行关注,并建议在 softmax 后混合每个头的注意力作为解决方案,称为重新注意力。结果与 NLP 的 Talking Heads 论文一致。
您可以按如下方式使用它
import torch
from vit_pytorch . deepvit import DeepViT
v = DeepViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 1 , 3 , 256 , 256 )
preds = v ( img ) # (1, 1000) 本文还指出了更深度地训练视觉变换器的困难,并提出了两种解决方案。首先,它建议对残差块的输出进行每通道乘法。其次,它建议让补丁相互关注,并且只允许 CLS 代币参与最后几层的补丁。
他们还添加了 Talking Heads,指出了改进
您可以按如下方式使用该方案
import torch
from vit_pytorch . cait import CaiT
v = CaiT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 12 , # depth of transformer for patch to patch attention only
cls_depth = 2 , # depth of cross attention of CLS tokens to patch
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1 ,
layer_dropout = 0.05 # randomly dropout 5% of the layers
)
img = torch . randn ( 1 , 3 , 256 , 256 )
preds = v ( img ) # (1, 1000) 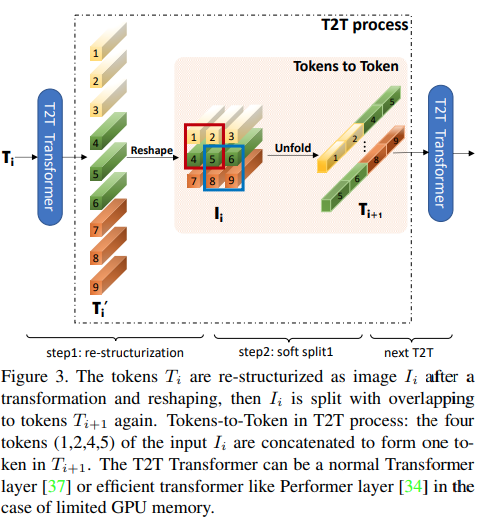
本文提出,前几层应通过展开对图像序列进行下采样,从而导致每个标记中的图像数据重叠,如上图所示。您可以按如下方式使用ViT的此变体。
import torch
from vit_pytorch . t2t import T2TViT
v = T2TViT (
dim = 512 ,
image_size = 224 ,
depth = 5 ,
heads = 8 ,
mlp_dim = 512 ,
num_classes = 1000 ,
t2t_layers = (( 7 , 4 ), ( 3 , 2 ), ( 3 , 2 )) # tuples of the kernel size and stride of each consecutive layers of the initial token to token module
)
img = torch . randn ( 1 , 3 , 224 , 224 )
preds = v ( img ) # (1, 1000) CCT 通过使用卷积而不是修补和执行序列池来提出紧凑的转换器。这使得 CCT 具有高精度和少量参数。
您可以通过两种方法使用它
import torch
from vit_pytorch . cct import CCT
cct = CCT (
img_size = ( 224 , 448 ),
embedding_dim = 384 ,
n_conv_layers = 2 ,
kernel_size = 7 ,
stride = 2 ,
padding = 3 ,
pooling_kernel_size = 3 ,
pooling_stride = 2 ,
pooling_padding = 1 ,
num_layers = 14 ,
num_heads = 6 ,
mlp_ratio = 3. ,
num_classes = 1000 ,
positional_embedding = 'learnable' , # ['sine', 'learnable', 'none']
)
img = torch . randn ( 1 , 3 , 224 , 448 )
pred = cct ( img ) # (1, 1000)或者,您可以使用几个预定义模型[2,4,6,7,8,14,16]之一,它们预定义层数、注意力头数、mlp 比率和嵌入维度。
import torch
from vit_pytorch . cct import cct_14
cct = cct_14 (
img_size = 224 ,
n_conv_layers = 1 ,
kernel_size = 7 ,
stride = 2 ,
padding = 3 ,
pooling_kernel_size = 3 ,
pooling_stride = 2 ,
pooling_padding = 1 ,
num_classes = 1000 ,
positional_embedding = 'learnable' , # ['sine', 'learnable', 'none']
)官方存储库包含预训练模型检查点的链接。
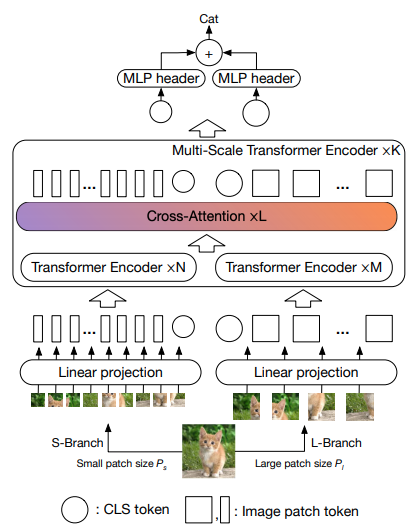
本文提出让两个视觉变换器以不同的尺度处理图像,每隔一段时间交叉处理一个。他们展示了基础视觉转换器之上的改进。
import torch
from vit_pytorch . cross_vit import CrossViT
v = CrossViT (
image_size = 256 ,
num_classes = 1000 ,
depth = 4 , # number of multi-scale encoding blocks
sm_dim = 192 , # high res dimension
sm_patch_size = 16 , # high res patch size (should be smaller than lg_patch_size)
sm_enc_depth = 2 , # high res depth
sm_enc_heads = 8 , # high res heads
sm_enc_mlp_dim = 2048 , # high res feedforward dimension
lg_dim = 384 , # low res dimension
lg_patch_size = 64 , # low res patch size
lg_enc_depth = 3 , # low res depth
lg_enc_heads = 8 , # low res heads
lg_enc_mlp_dim = 2048 , # low res feedforward dimensions
cross_attn_depth = 2 , # cross attention rounds
cross_attn_heads = 8 , # cross attention heads
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 1 , 3 , 256 , 256 )
pred = v ( img ) # (1, 1000) 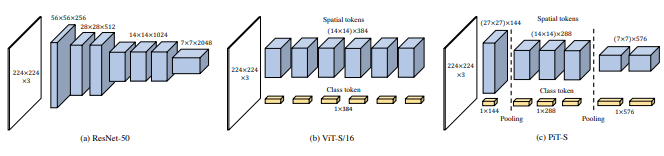
本文建议通过使用深度卷积的池化过程对标记进行下采样。
import torch
from vit_pytorch . pit import PiT
v = PiT (
image_size = 224 ,
patch_size = 14 ,
dim = 256 ,
num_classes = 1000 ,
depth = ( 3 , 3 , 3 ), # list of depths, indicating the number of rounds of each stage before a downsample
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
# forward pass now returns predictions and the attention maps
img = torch . randn ( 1 , 3 , 224 , 224 )
preds = v ( img ) # (1, 1000) 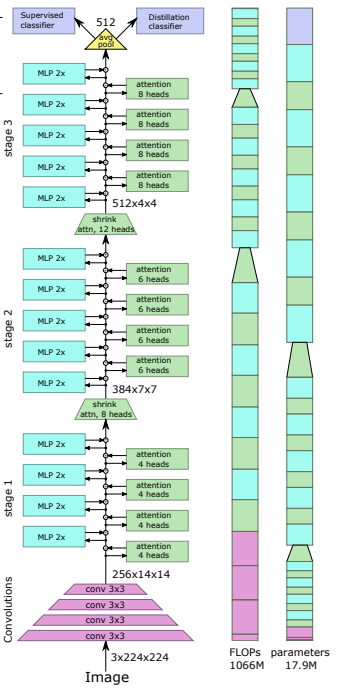
本文提出了一些变化,包括(1)卷积嵌入而不是逐块投影(2)阶段下采样(3)注意力中的额外非线性(4)二维相对位置偏差而不是初始绝对位置偏差(5) )batchnorm 代替 Layernorm。
官方存储库
import torch
from vit_pytorch . levit import LeViT
levit = LeViT (
image_size = 224 ,
num_classes = 1000 ,
stages = 3 , # number of stages
dim = ( 256 , 384 , 512 ), # dimensions at each stage
depth = 4 , # transformer of depth 4 at each stage
heads = ( 4 , 6 , 8 ), # heads at each stage
mlp_mult = 2 ,
dropout = 0.1
)
img = torch . randn ( 1 , 3 , 224 , 224 )
levit ( img ) # (1, 1000) 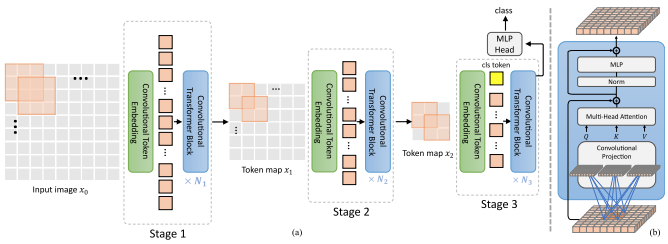
本文提出混合卷积和注意力。具体来说,卷积用于分三个阶段嵌入和下采样图像/特征图。深度卷积还用于投影查询、键和值以引起注意。
import torch
from vit_pytorch . cvt import CvT
v = CvT (
num_classes = 1000 ,
s1_emb_dim = 64 , # stage 1 - dimension
s1_emb_kernel = 7 , # stage 1 - conv kernel
s1_emb_stride = 4 , # stage 1 - conv stride
s1_proj_kernel = 3 , # stage 1 - attention ds-conv kernel size
s1_kv_proj_stride = 2 , # stage 1 - attention key / value projection stride
s1_heads = 1 , # stage 1 - heads
s1_depth = 1 , # stage 1 - depth
s1_mlp_mult = 4 , # stage 1 - feedforward expansion factor
s2_emb_dim = 192 , # stage 2 - (same as above)
s2_emb_kernel = 3 ,
s2_emb_stride = 2 ,
s2_proj_kernel = 3 ,
s2_kv_proj_stride = 2 ,
s2_heads = 3 ,
s2_depth = 2 ,
s2_mlp_mult = 4 ,
s3_emb_dim = 384 , # stage 3 - (same as above)
s3_emb_kernel = 3 ,
s3_emb_stride = 2 ,
s3_proj_kernel = 3 ,
s3_kv_proj_stride = 2 ,
s3_heads = 4 ,
s3_depth = 10 ,
s3_mlp_mult = 4 ,
dropout = 0.
)
img = torch . randn ( 1 , 3 , 224 , 224 )
pred = v ( img ) # (1, 1000) 
本文提出混合局部和全局注意力,以及位置编码生成器(在 CPVT 中提出)和全局平均池化,以实现与 Swin 相同的结果,而无需移动窗口、CLS 令牌或位置嵌入的额外复杂性。
import torch
from vit_pytorch . twins_svt import TwinsSVT
model = TwinsSVT (
num_classes = 1000 , # number of output classes
s1_emb_dim = 64 , # stage 1 - patch embedding projected dimension
s1_patch_size = 4 , # stage 1 - patch size for patch embedding
s1_local_patch_size = 7 , # stage 1 - patch size for local attention
s1_global_k = 7 , # stage 1 - global attention key / value reduction factor, defaults to 7 as specified in paper
s1_depth = 1 , # stage 1 - number of transformer blocks (local attn -> ff -> global attn -> ff)
s2_emb_dim = 128 , # stage 2 (same as above)
s2_patch_size = 2 ,
s2_local_patch_size = 7 ,
s2_global_k = 7 ,
s2_depth = 1 ,
s3_emb_dim = 256 , # stage 3 (same as above)
s3_patch_size = 2 ,
s3_local_patch_size = 7 ,
s3_global_k = 7 ,
s3_depth = 5 ,
s4_emb_dim = 512 , # stage 4 (same as above)
s4_patch_size = 2 ,
s4_local_patch_size = 7 ,
s4_global_k = 7 ,
s4_depth = 4 ,
peg_kernel_size = 3 , # positional encoding generator kernel size
dropout = 0. # dropout
)
img = torch . randn ( 1 , 3 , 224 , 224 )
pred = model ( img ) # (1, 1000) 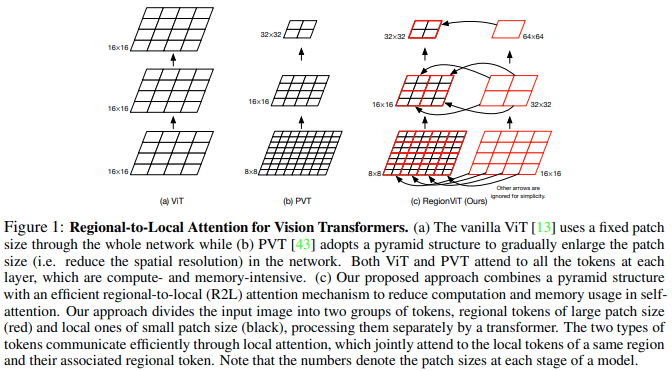
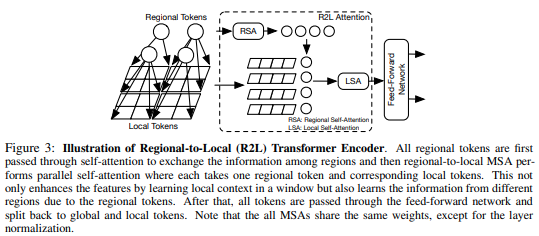
本文提出将特征图划分为局部区域,从而局部标记相互关注。每个本地区域都有自己的区域令牌,然后处理其所有本地令牌以及其他区域令牌。
您可以按如下方式使用它
import torch
from vit_pytorch . regionvit import RegionViT
model = RegionViT (
dim = ( 64 , 128 , 256 , 512 ), # tuple of size 4, indicating dimension at each stage
depth = ( 2 , 2 , 8 , 2 ), # depth of the region to local transformer at each stage
window_size = 7 , # window size, which should be either 7 or 14
num_classes = 1000 , # number of output classes
tokenize_local_3_conv = False , # whether to use a 3 layer convolution to encode the local tokens from the image. the paper uses this for the smaller models, but uses only 1 conv (set to False) for the larger models
use_peg = False , # whether to use positional generating module. they used this for object detection for a boost in performance
)
img = torch . randn ( 1 , 3 , 224 , 224 )
pred = model ( img ) # (1, 1000) 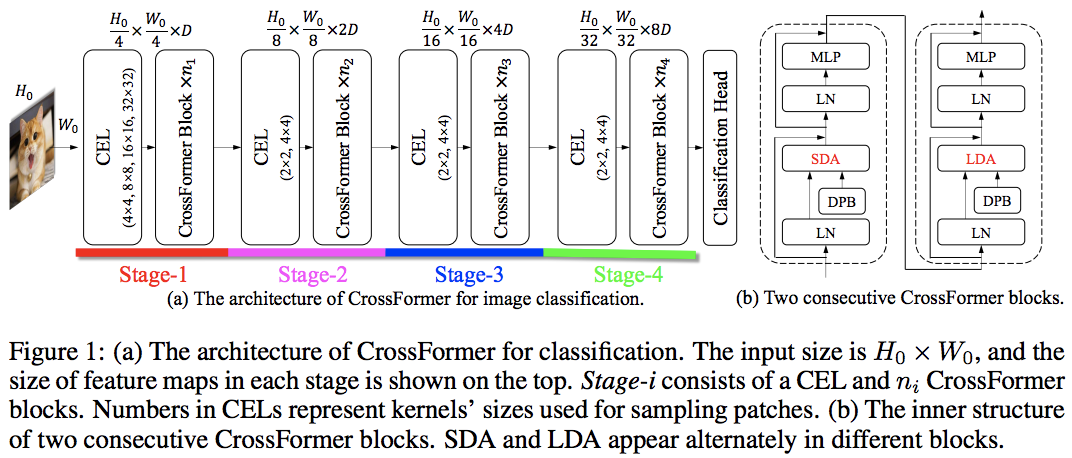
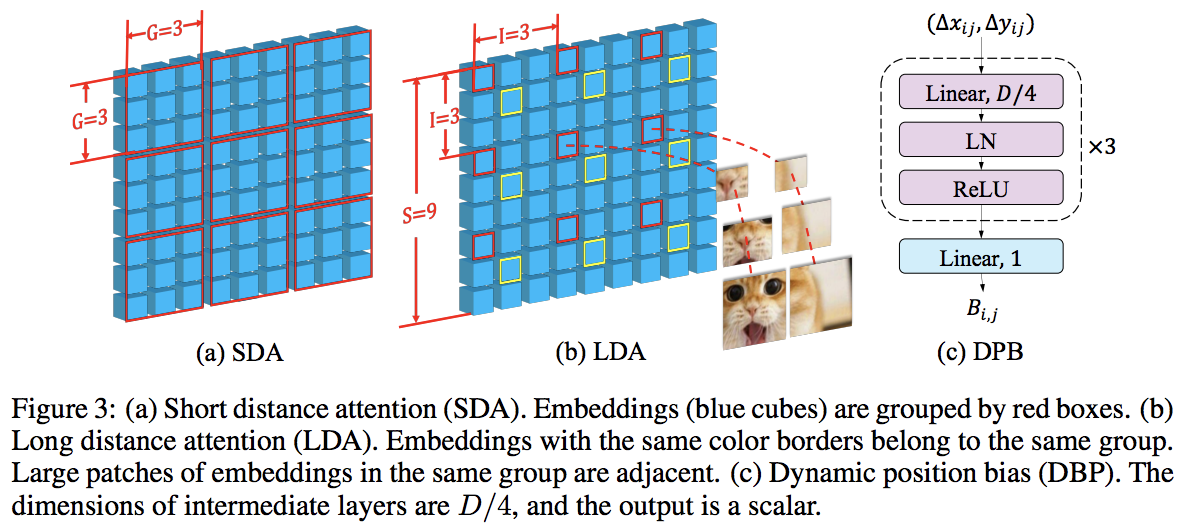
本文利用局部和全局交替注意力的方式击败了 PVT 和 Swin。全局注意力是在窗口维度上完成的,以降低复杂性,就像用于轴向注意力的方案一样。
他们还具有跨尺度嵌入层,他们证明这是一个可以改进所有视觉转换器的通用层。还制定了动态相对位置偏差,以使网络能够推广到更高分辨率的图像。
import torch
from vit_pytorch . crossformer import CrossFormer
model = CrossFormer (
num_classes = 1000 , # number of output classes
dim = ( 64 , 128 , 256 , 512 ), # dimension at each stage
depth = ( 2 , 2 , 8 , 2 ), # depth of transformer at each stage
global_window_size = ( 8 , 4 , 2 , 1 ), # global window sizes at each stage
local_window_size = 7 , # local window size (can be customized for each stage, but in paper, held constant at 7 for all stages)
)
img = torch . randn ( 1 , 3 , 224 , 224 )
pred = model ( img ) # (1, 1000) 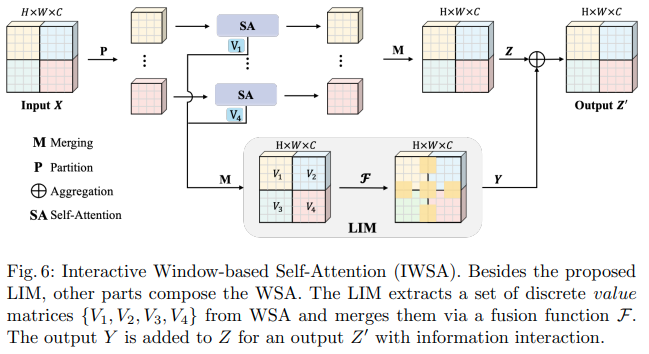
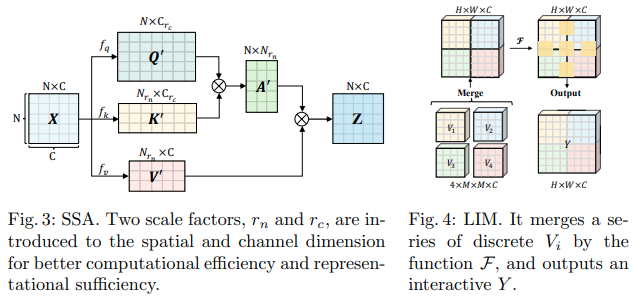
这篇字节跳动人工智能论文提出了可扩展自注意力(SSA)和交互式窗口自注意力(IWSA)模块。 SSA 通过按某个因子 ( reduction_factor ) 减少键/值特征图,同时调整查询和键的维度 ( ssa_dim_key ) 来减轻早期阶段所需的计算。 IWSA 在本地窗口内执行自注意力,类似于其他视觉转换器论文。然而,他们添加了通过内核大小 3 的卷积传递的残差值,他们将其命名为本地交互模块 (LIM)。
他们在本文中声称该方案优于 Swin Transformer,并且还展示了与 Crossformer 竞争的性能。
您可以按如下方式使用它(例如 ScalableViT-S)
import torch
from vit_pytorch . scalable_vit import ScalableViT
model = ScalableViT (
num_classes = 1000 ,
dim = 64 , # starting model dimension. at every stage, dimension is doubled
heads = ( 2 , 4 , 8 , 16 ), # number of attention heads at each stage
depth = ( 2 , 2 , 20 , 2 ), # number of transformer blocks at each stage
ssa_dim_key = ( 40 , 40 , 40 , 32 ), # the dimension of the attention keys (and queries) for SSA. in the paper, they represented this as a scale factor on the base dimension per key (ssa_dim_key / dim_key)
reduction_factor = ( 8 , 4 , 2 , 1 ), # downsampling of the key / values in SSA. in the paper, this was represented as (reduction_factor ** -2)
window_size = ( 64 , 32 , None , None ), # window size of the IWSA at each stage. None means no windowing needed
dropout = 0.1 , # attention and feedforward dropout
)
img = torch . randn ( 1 , 3 , 256 , 256 )
preds = model ( img ) # (1, 1000) 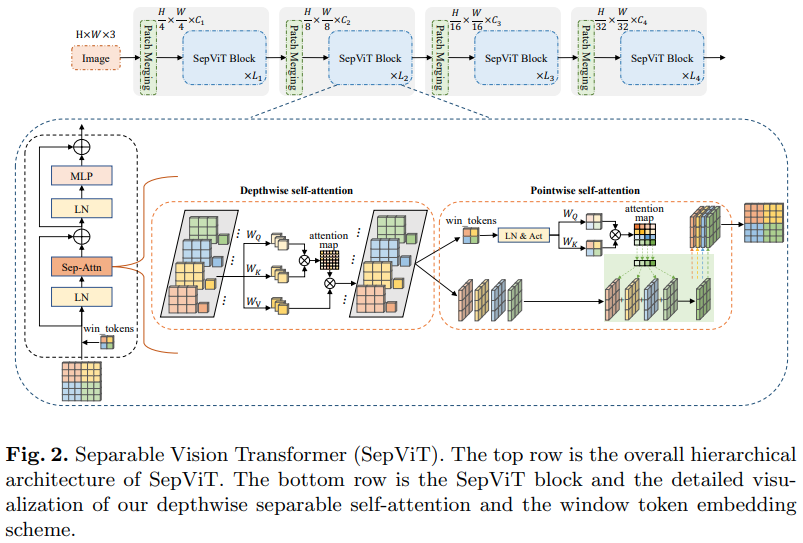
另一篇字节跳动人工智能论文,它提出了一个深度逐点自注意力层,该层似乎很大程度上受到 mobilenet 深度可分离卷积的启发。最有趣的方面是重用深度自注意力阶段的特征图作为逐点自注意力的值,如上图所示。
我决定仅包含具有此特定自注意力层的SepViT版本,因为分组注意力层既不显着也不新颖,并且作者不清楚如何处理组自注意力层的窗口标记。此外,似乎仅凭DSSA层,他们就能够击败 Swin。
前任。 SepViT-Lite
import torch
from vit_pytorch . sep_vit import SepViT
v = SepViT (
num_classes = 1000 ,
dim = 32 , # dimensions of first stage, which doubles every stage (32, 64, 128, 256) for SepViT-Lite
dim_head = 32 , # attention head dimension
heads = ( 1 , 2 , 4 , 8 ), # number of heads per stage
depth = ( 1 , 2 , 6 , 2 ), # number of transformer blocks per stage
window_size = 7 , # window size of DSS Attention block
dropout = 0.1 # dropout
)
img = torch . randn ( 1 , 3 , 224 , 224 )
preds = v ( img ) # (1, 1000) 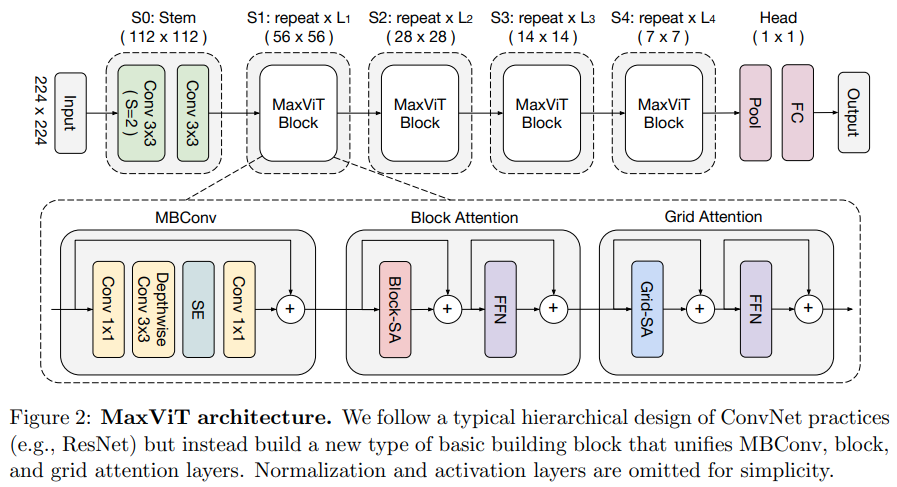
本文提出了一种混合卷积/注意力网络,从卷积侧使用MBConv,然后使用块/网格轴向稀疏注意力。
他们还声称这种特定的视觉转换器非常适合生成模型(GAN)。
前任。最大ViT-S
import torch
from vit_pytorch . max_vit import MaxViT
v = MaxViT (
num_classes = 1000 ,
dim_conv_stem = 64 , # dimension of the convolutional stem, would default to dimension of first layer if not specified
dim = 96 , # dimension of first layer, doubles every layer
dim_head = 32 , # dimension of attention heads, kept at 32 in paper
depth = ( 2 , 2 , 5 , 2 ), # number of MaxViT blocks per stage, which consists of MBConv, block-like attention, grid-like attention
window_size = 7 , # window size for block and grids
mbconv_expansion_rate = 4 , # expansion rate of MBConv
mbconv_shrinkage_rate = 0.25 , # shrinkage rate of squeeze-excitation in MBConv
dropout = 0.1 # dropout
)
img = torch . randn ( 2 , 3 , 224 , 224 )
preds = v ( img ) # (2, 1000) 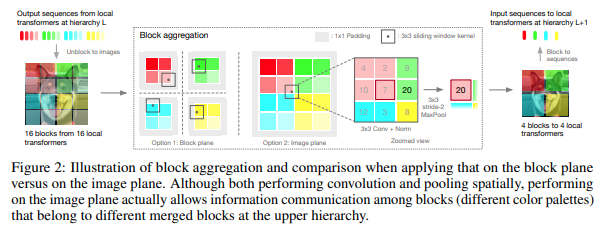
本文决定在分层阶段处理图像,仅关注本地块的标记,这些标记随着层次结构的向上移动而聚合。聚合在图像平面中完成,并包含卷积和后续的 maxpool,以允许其跨边界传递信息。
您可以通过以下代码使用它(例如 NesT-T)
import torch
from vit_pytorch . nest import NesT
nest = NesT (
image_size = 224 ,
patch_size = 4 ,
dim = 96 ,
heads = 3 ,
num_hierarchies = 3 , # number of hierarchies
block_repeats = ( 2 , 2 , 8 ), # the number of transformer blocks at each hierarchy, starting from the bottom
num_classes = 1000
)
img = torch . randn ( 1 , 3 , 224 , 224 )
pred = nest ( img ) # (1, 1000) 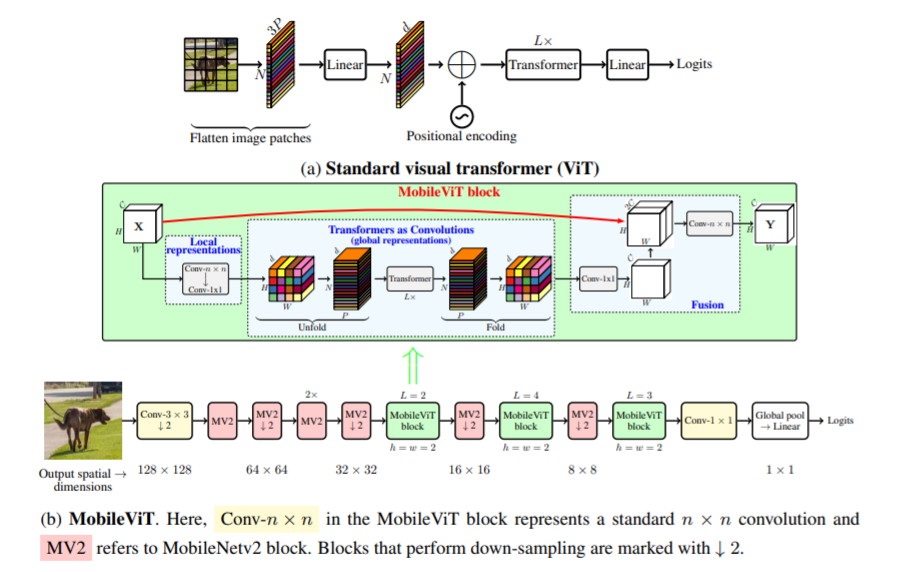
本文介绍了 MobileViT,一种用于移动设备的轻量级通用视觉转换器。 MobileViT 为使用 Transformer 进行全局信息处理提供了不同的视角。
您可以通过以下代码使用它(例如 mobilevit_xs)
import torch
from vit_pytorch . mobile_vit import MobileViT
mbvit_xs = MobileViT (
image_size = ( 256 , 256 ),
dims = [ 96 , 120 , 144 ],
channels = [ 16 , 32 , 48 , 48 , 64 , 64 , 80 , 80 , 96 , 96 , 384 ],
num_classes = 1000
)
img = torch . randn ( 1 , 3 , 256 , 256 )
pred = mbvit_xs ( img ) # (1, 1000) 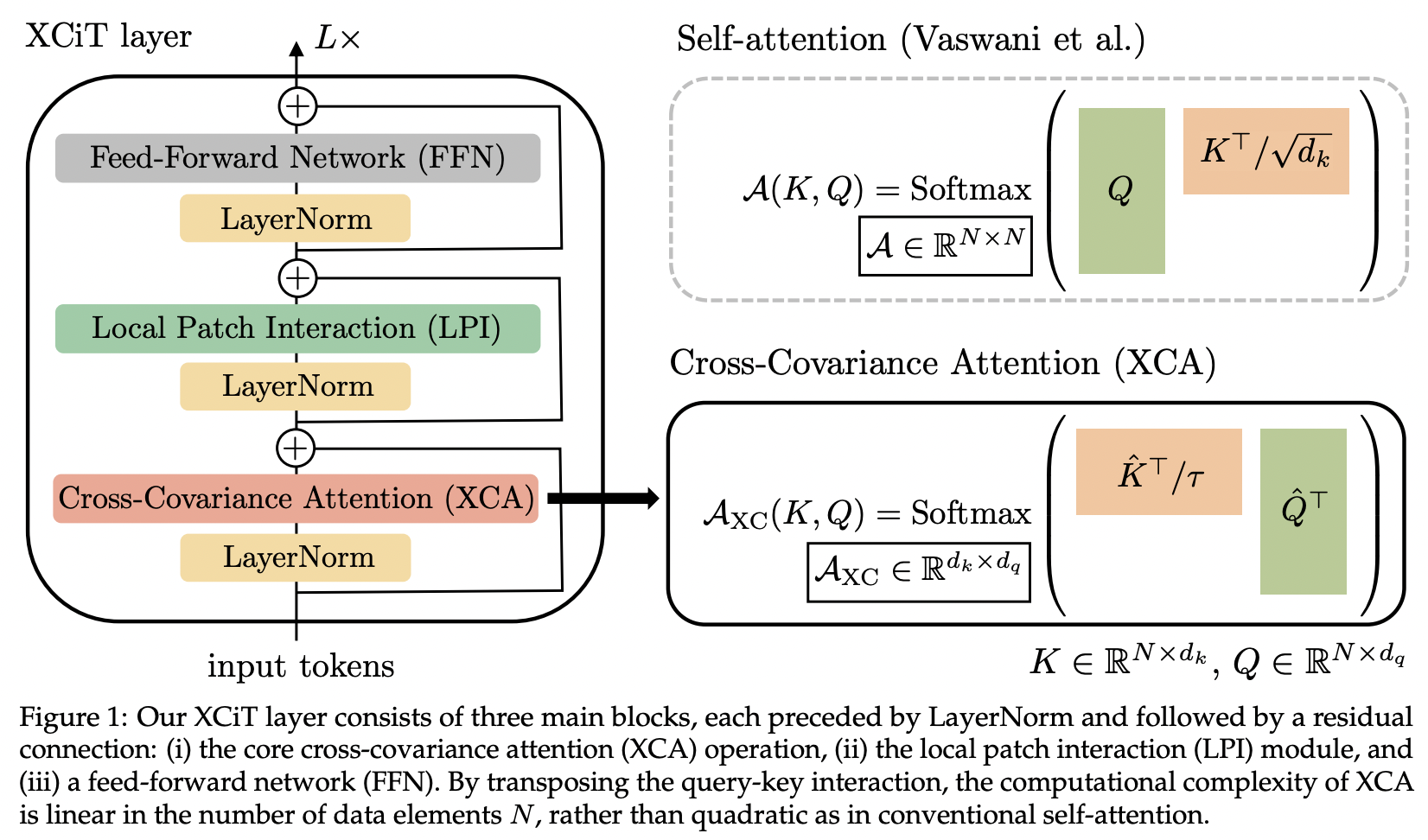
本文介绍了交叉协方差注意力(简称XCA)。人们可以将其视为跨特征维度而不是空间维度进行关注(另一种观点是动态 1x1 卷积,内核是由空间相关性定义的关注图)。
从技术上讲,这相当于在使用学习到的温度执行余弦相似度注意力之前简单地转置查询、键、值。
import torch
from vit_pytorch . xcit import XCiT
v = XCiT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 12 , # depth of xcit transformer
cls_depth = 2 , # depth of cross attention of CLS tokens to patch, attention pool at end
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1 ,
layer_dropout = 0.05 , # randomly dropout 5% of the layers
local_patch_kernel_size = 3 # kernel size of the local patch interaction module (depthwise convs)
)
img = torch . randn ( 1 , 3 , 256 , 256 )
preds = v ( img ) # (1, 1000) 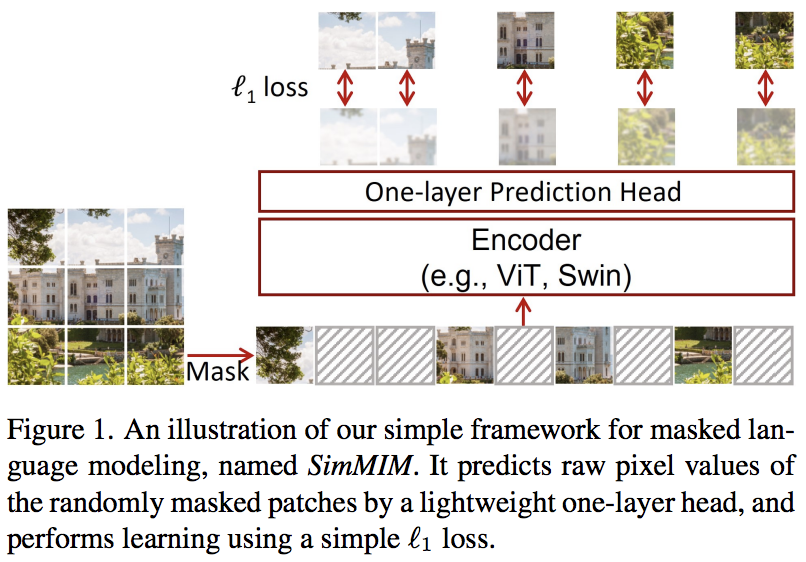
本文提出了一种简单的掩模图像建模(SimMIM)方案,仅使用掩模标记到像素空间的线性投影,然后使用掩模补丁的像素值进行 L1 损失。结果与其他更复杂的方法相比具有竞争力。
您可以按如下方式使用它
import torch
from vit_pytorch import ViT
from vit_pytorch . simmim import SimMIM
v = ViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048
)
mim = SimMIM (
encoder = v ,
masking_ratio = 0.5 # they found 50% to yield the best results
)
images = torch . randn ( 8 , 3 , 256 , 256 )
loss = mim ( images )
loss . backward ()
# that's all!
# do the above in a for loop many times with a lot of images and your vision transformer will learn
torch . save ( v . state_dict (), './trained-vit.pt' )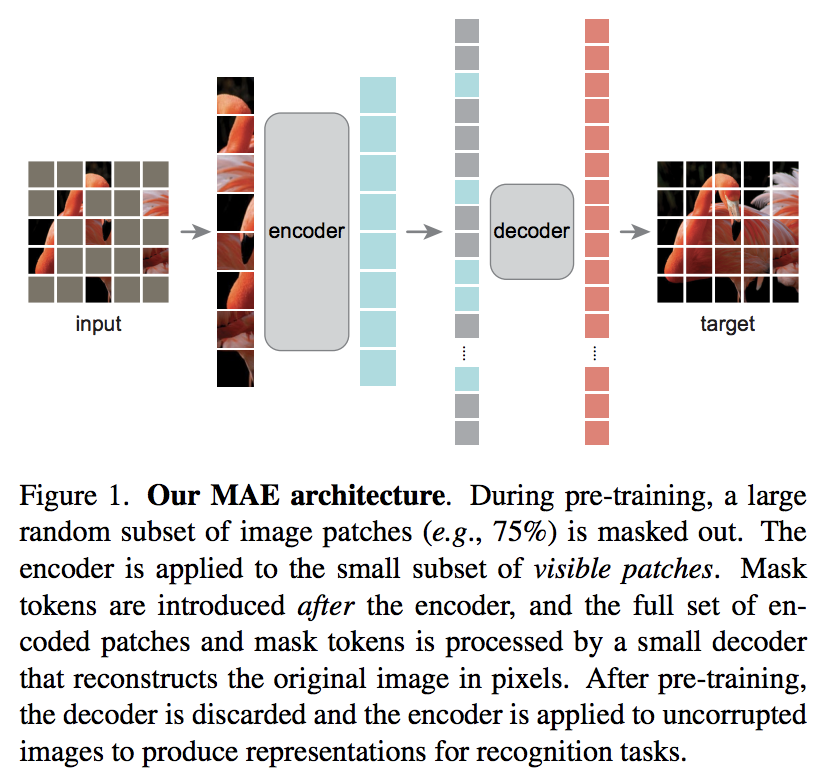
Kaiming He 的一篇新论文提出了一种简单的自动编码器方案,其中视觉变换器负责一组未屏蔽的补丁,而较小的解码器尝试重建屏蔽的像素值。
DeepReader快速论文审阅
AI 与 Letitia 喝咖啡
您可以通过以下代码使用它
import torch
from vit_pytorch import ViT , MAE
v = ViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048
)
mae = MAE (
encoder = v ,
masking_ratio = 0.75 , # the paper recommended 75% masked patches
decoder_dim = 512 , # paper showed good results with just 512
decoder_depth = 6 # anywhere from 1 to 8
)
images = torch . randn ( 8 , 3 , 256 , 256 )
loss = mae ( images )
loss . backward ()
# that's all!
# do the above in a for loop many times with a lot of images and your vision transformer will learn
# save your improved vision transformer
torch . save ( v . state_dict (), './trained-vit.pt' )感谢 Zach,您可以使用本文中提出的原始蒙版补丁预测任务进行训练,代码如下。
import torch
from vit_pytorch import ViT
from vit_pytorch . mpp import MPP
model = ViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
mpp_trainer = MPP (
transformer = model ,
patch_size = 32 ,
dim = 1024 ,
mask_prob = 0.15 , # probability of using token in masked prediction task
random_patch_prob = 0.30 , # probability of randomly replacing a token being used for mpp
replace_prob = 0.50 , # probability of replacing a token being used for mpp with the mask token
)
opt = torch . optim . Adam ( mpp_trainer . parameters (), lr = 3e-4 )
def sample_unlabelled_images ():
return torch . FloatTensor ( 20 , 3 , 256 , 256 ). uniform_ ( 0. , 1. )
for _ in range ( 100 ):
images = sample_unlabelled_images ()
loss = mpp_trainer ( images )
opt . zero_grad ()
loss . backward ()
opt . step ()
# save your improved network
torch . save ( model . state_dict (), './pretrained-net.pt' )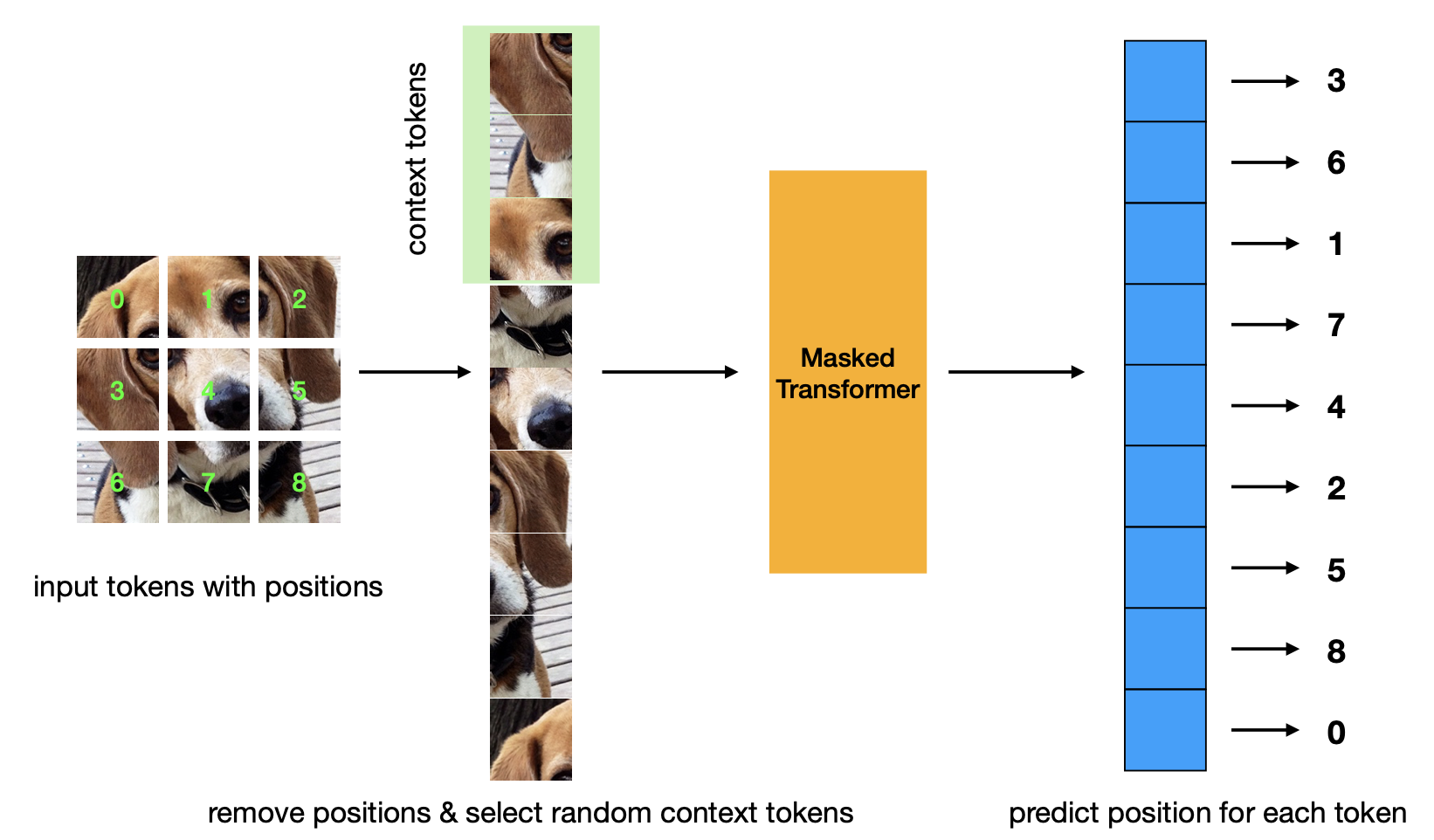
新论文介绍了蒙版位置预测预训练标准。该策略比 Masked Autoencoder 策略更高效,并且具有相当的性能。
import torch
from vit_pytorch . mp3 import ViT , MP3
v = ViT (
num_classes = 1000 ,
image_size = 256 ,
patch_size = 8 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
)
mp3 = MP3 (
vit = v ,
masking_ratio = 0.75
)
images = torch . randn ( 8 , 3 , 256 , 256 )
loss = mp3 ( images )
loss . backward ()
# that's all!
# do the above in a for loop many times with a lot of images and your vision transformer will learn
# save your improved vision transformer
torch . save ( v . state_dict (), './trained-vit.pt' )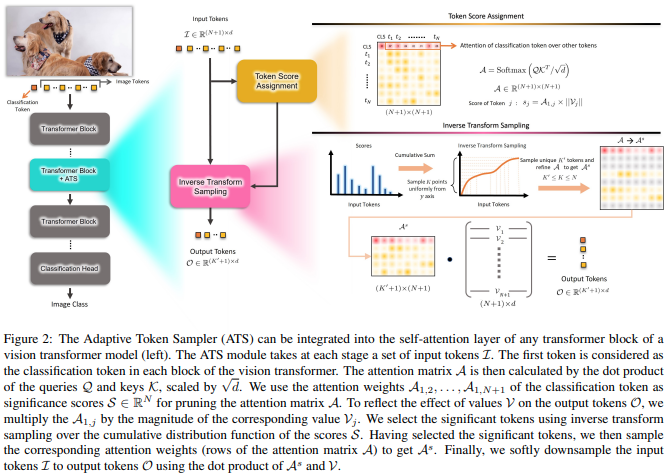
本文提出使用 CLS 注意力分数,通过值头的规范重新加权,作为丢弃不同层不重要标记的手段。
import torch
from vit_pytorch . ats_vit import ViT
v = ViT (
image_size = 256 ,
patch_size = 16 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
max_tokens_per_depth = ( 256 , 128 , 64 , 32 , 16 , 8 ), # a tuple that denotes the maximum number of tokens that any given layer should have. if the layer has greater than this amount, it will undergo adaptive token sampling
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 4 , 3 , 256 , 256 )
preds = v ( img ) # (4, 1000)
# you can also get a list of the final sampled patch ids
# a value of -1 denotes padding
preds , token_ids = v ( img , return_sampled_token_ids = True ) # (4, 1000), (4, <=8) 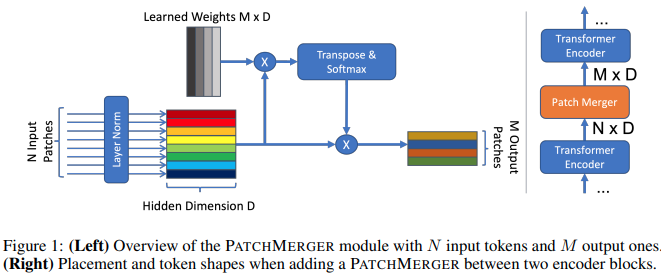
本文提出了一个简单的模块(补丁合并),用于在不牺牲性能的情况下减少视觉转换器任何层的令牌数量。
import torch
from vit_pytorch . vit_with_patch_merger import ViT
v = ViT (
image_size = 256 ,
patch_size = 16 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 12 ,
heads = 8 ,
patch_merge_layer = 6 , # at which transformer layer to do patch merging
patch_merge_num_tokens = 8 , # the output number of tokens from the patch merge
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 4 , 3 , 256 , 256 )
preds = v ( img ) # (4, 1000)也可以单独使用PatchMerger模块
import torch
from vit_pytorch . vit_with_patch_merger import PatchMerger
merger = PatchMerger (
dim = 1024 ,
num_tokens_out = 8 # output number of tokens
)
features = torch . randn ( 4 , 256 , 1024 ) # (batch, num tokens, dimension)
out = merger ( features ) # (4, 8, 1024) 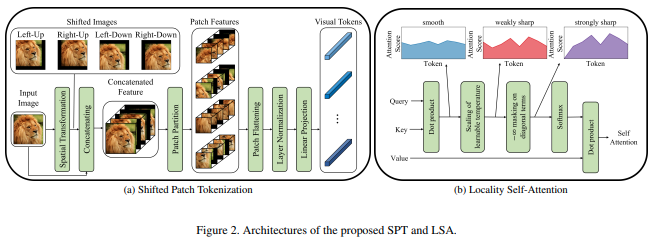
本文提出了一种新的图像修补功能,该功能在对图像进行归一化并将图像分割为修补程序之前结合了图像的移位。我发现转变对于其他一些变形金刚工作非常有帮助,因此决定将其包括在内以进行进一步的探索。它还包括具有学习温度的LSA ,并屏蔽令牌对其自身的关注。
您可以按如下方式使用:
import torch
from vit_pytorch . vit_for_small_dataset import ViT
v = ViT (
image_size = 256 ,
patch_size = 16 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 4 , 3 , 256 , 256 )
preds = v ( img ) # (1, 1000)您还可以使用本文中的SPT作为独立模块
import torch
from vit_pytorch . vit_for_small_dataset import SPT
spt = SPT (
dim = 1024 ,
patch_size = 16 ,
channels = 3
)
img = torch . randn ( 4 , 3 , 256 , 256 )
tokens = spt ( img ) # (4, 256, 1024) 应大众要求,我将开始将此存储库中的一些架构扩展到 3D ViT,以用于视频、医学成像等。
您将需要传递两个额外的超参数:(1) 帧数frames和(2) 沿帧维度的补丁大小frame_patch_size
首先,3D ViT
import torch
from vit_pytorch . vit_3d import ViT
v = ViT (
image_size = 128 , # image size
frames = 16 , # number of frames
image_patch_size = 16 , # image patch size
frame_patch_size = 2 , # frame patch size
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
video = torch . randn ( 4 , 3 , 16 , 128 , 128 ) # (batch, channels, frames, height, width)
preds = v ( video ) # (4, 1000)3D 简单 ViT
import torch
from vit_pytorch . simple_vit_3d import SimpleViT
v = SimpleViT (
image_size = 128 , # image size
frames = 16 , # number of frames
image_patch_size = 16 , # image patch size
frame_patch_size = 2 , # frame patch size
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048
)
video = torch . randn ( 4 , 3 , 16 , 128 , 128 ) # (batch, channels, frames, height, width)
preds = v ( video ) # (4, 1000)3D 版 CCT
import torch
from vit_pytorch . cct_3d import CCT
cct = CCT (
img_size = 224 ,
num_frames = 8 ,
embedding_dim = 384 ,
n_conv_layers = 2 ,
frame_kernel_size = 3 ,
kernel_size = 7 ,
stride = 2 ,
padding = 3 ,
pooling_kernel_size = 3 ,
pooling_stride = 2 ,
pooling_padding = 1 ,
num_layers = 14 ,
num_heads = 6 ,
mlp_ratio = 3. ,
num_classes = 1000 ,
positional_embedding = 'learnable'
)
video = torch . randn ( 1 , 3 , 8 , 224 , 224 ) # (batch, channels, frames, height, width)
pred = cct ( video )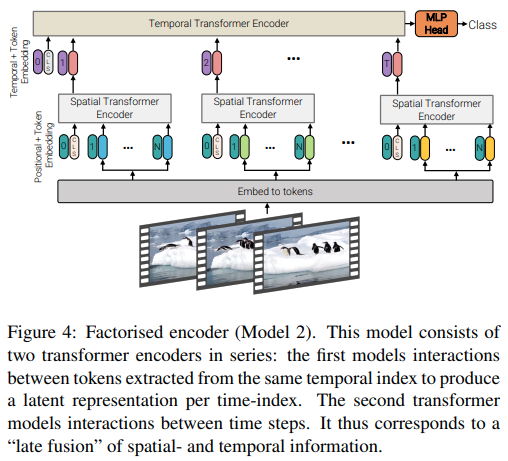
本文提供了 3 种不同类型的视频高效注意力架构,主题是跨空间和时间分解注意力。该存储库包括因式分解编码器和因式分解自注意力变体。分解编码器变体是一个空间变换器,后面跟着一个时间变换器。因子化自注意力变体是一个时空转换器,具有交替的空间和时间自注意力层。
import torch
from vit_pytorch . vivit import ViT
v = ViT (
image_size = 128 , # image size
frames = 16 , # number of frames
image_patch_size = 16 , # image patch size
frame_patch_size = 2 , # frame patch size
num_classes = 1000 ,
dim = 1024 ,
spatial_depth = 6 , # depth of the spatial transformer
temporal_depth = 6 , # depth of the temporal transformer
heads = 8 ,
mlp_dim = 2048 ,
variant = 'factorized_encoder' , # or 'factorized_self_attention'
)
video = torch . randn ( 4 , 3 , 16 , 128 , 128 ) # (batch, channels, frames, height, width)
preds = v ( video ) # (4, 1000) 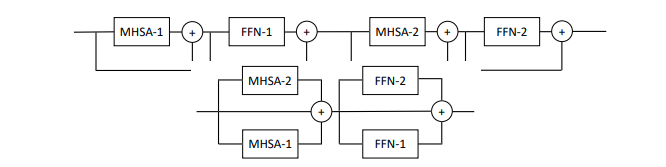
本文提出每层并行多个注意力和前馈块(2 个块),声称这样更容易训练而不损失性能。
您可以按如下方式尝试此变体
import torch
from vit_pytorch . parallel_vit import ViT
v = ViT (
image_size = 256 ,
patch_size = 16 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048 ,
num_parallel_branches = 2 , # in paper, they claimed 2 was optimal
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 4 , 3 , 256 , 256 )
preds = v ( img ) # (4, 1000) 
本文表明,在视觉转换器的每一层添加可学习的记忆令牌可以极大地增强微调结果(除了可学习的任务特定的 CLS 令牌和适配器头之外)。
您可以将其与经过特殊修改的ViT一起使用,如下所示
import torch
from vit_pytorch . learnable_memory_vit import ViT , Adapter
# normal base ViT
v = ViT (
image_size = 256 ,
patch_size = 16 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 4 , 3 , 256 , 256 )
logits = v ( img ) # (4, 1000)
# do your usual training with ViT
# ...
# then, to finetune, just pass the ViT into the Adapter class
# you can do this for multiple Adapters, as shown below
adapter1 = Adapter (
vit = v ,
num_classes = 2 , # number of output classes for this specific task
num_memories_per_layer = 5 # number of learnable memories per layer, 10 was sufficient in paper
)
logits1 = adapter1 ( img ) # (4, 2) - predict 2 classes off frozen ViT backbone with learnable memories and task specific head
# yet another task to finetune on, this time with 4 classes
adapter2 = Adapter (
vit = v ,
num_classes = 4 ,
num_memories_per_layer = 10
)
logits2 = adapter2 ( img ) # (4, 4) - predict 4 classes off frozen ViT backbone with learnable memories and task specific head 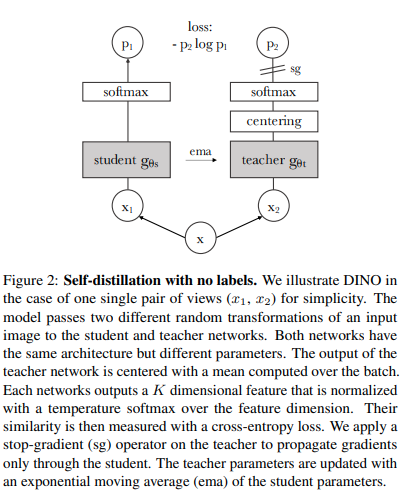
您可以使用最近的 SOTA 自监督学习技术 Dino 来训练ViT ,代码如下。
雅尼克·基尔彻视频
import torch
from vit_pytorch import ViT , Dino
model = ViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048
)
learner = Dino (
model ,
image_size = 256 ,
hidden_layer = 'to_latent' , # hidden layer name or index, from which to extract the embedding
projection_hidden_size = 256 , # projector network hidden dimension
projection_layers = 4 , # number of layers in projection network
num_classes_K = 65336 , # output logits dimensions (referenced as K in paper)
student_temp = 0.9 , # student temperature
teacher_temp = 0.04 , # teacher temperature, needs to be annealed from 0.04 to 0.07 over 30 epochs
local_upper_crop_scale = 0.4 , # upper bound for local crop - 0.4 was recommended in the paper
global_lower_crop_scale = 0.5 , # lower bound for global crop - 0.5 was recommended in the paper
moving_average_decay = 0.9 , # moving average of encoder - paper showed anywhere from 0.9 to 0.999 was ok
center_moving_average_decay = 0.9 , # moving average of teacher centers - paper showed anywhere from 0.9 to 0.999 was ok
)
opt = torch . optim . Adam ( learner . parameters (), lr = 3e-4 )
def sample_unlabelled_images ():
return torch . randn ( 20 , 3 , 256 , 256 )
for _ in range ( 100 ):
images = sample_unlabelled_images ()
loss = learner ( images )
opt . zero_grad ()
loss . backward ()
opt . step ()
learner . update_moving_average () # update moving average of teacher encoder and teacher centers
# save your improved network
torch . save ( model . state_dict (), './pretrained-net.pt' )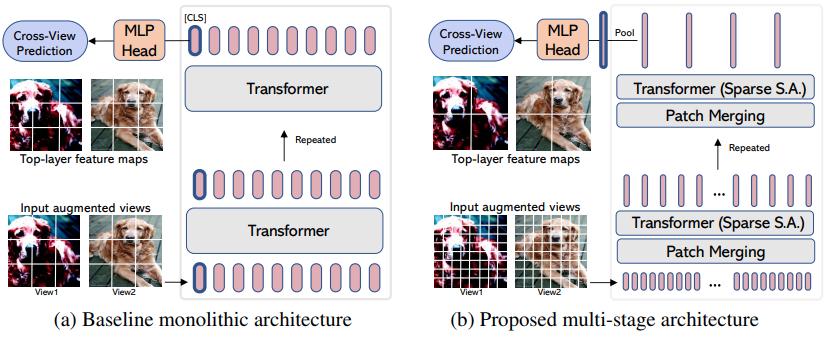
EsViT是 Dino(从上面)的变体,经过重新设计,通过考虑增强视图之间的额外区域损失,通过补丁合并/下采样来支持高效的ViT 。引用摘要,它outperforms its supervised counterpart on 17 out of 18 datasets吞吐量高出 3 倍。
尽管它被命名为新的ViT变体,但实际上它只是一种训练任何多阶段ViT的策略(在论文中,他们专注于 Swin)。下面的示例将展示如何将其与CvT一起使用。您需要将hidden_layer layer设置为高效ViT中输出非平均池化视觉表示的层的名称,就在全局池化和投影到logits之前。
import torch
from vit_pytorch . cvt import CvT
from vit_pytorch . es_vit import EsViTTrainer
cvt = CvT (
num_classes = 1000 ,
s1_emb_dim = 64 ,
s1_emb_kernel = 7 ,
s1_emb_stride = 4 ,
s1_proj_kernel = 3 ,
s1_kv_proj_stride = 2 ,
s1_heads = 1 ,
s1_depth = 1 ,
s1_mlp_mult = 4 ,
s2_emb_dim = 192 ,
s2_emb_kernel = 3 ,
s2_emb_stride = 2 ,
s2_proj_kernel = 3 ,
s2_kv_proj_stride = 2 ,
s2_heads = 3 ,
s2_depth = 2 ,
s2_mlp_mult = 4 ,
s3_emb_dim = 384 ,
s3_emb_kernel = 3 ,
s3_emb_stride = 2 ,
s3_proj_kernel = 3 ,
s3_kv_proj_stride = 2 ,
s3_heads = 4 ,
s3_depth = 10 ,
s3_mlp_mult = 4 ,
dropout = 0.
)
learner = EsViTTrainer (
cvt ,
image_size = 256 ,
hidden_layer = 'layers' , # hidden layer name or index, from which to extract the embedding
projection_hidden_size = 256 , # projector network hidden dimension
projection_layers = 4 , # number of layers in projection network
num_classes_K = 65336 , # output logits dimensions (referenced as K in paper)
student_temp = 0.9 , # student temperature
teacher_temp = 0.04 , # teacher temperature, needs to be annealed from 0.04 to 0.07 over 30 epochs
local_upper_crop_scale = 0.4 , # upper bound for local crop - 0.4 was recommended in the paper
global_lower_crop_scale = 0.5 , # lower bound for global crop - 0.5 was recommended in the paper
moving_average_decay = 0.9 , # moving average of encoder - paper showed anywhere from 0.9 to 0.999 was ok
center_moving_average_decay = 0.9 , # moving average of teacher centers - paper showed anywhere from 0.9 to 0.999 was ok
)
opt = torch . optim . AdamW ( learner . parameters (), lr = 3e-4 )
def sample_unlabelled_images ():
return torch . randn ( 8 , 3 , 256 , 256 )
for _ in range ( 1000 ):
images = sample_unlabelled_images ()
loss = learner ( images )
opt . zero_grad ()
loss . backward ()
opt . step ()
learner . update_moving_average () # update moving average of teacher encoder and teacher centers
# save your improved network
torch . save ( cvt . state_dict (), './pretrained-net.pt' )如果您想可视化研究的注意力权重(softmax 后),只需按照以下步骤操作
import torch
from vit_pytorch . vit import ViT
v = ViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
# import Recorder and wrap the ViT
from vit_pytorch . recorder import Recorder
v = Recorder ( v )
# forward pass now returns predictions and the attention maps
img = torch . randn ( 1 , 3 , 256 , 256 )
preds , attns = v ( img )
# there is one extra patch due to the CLS token
attns # (1, 6, 16, 65, 65) - (batch x layers x heads x patch x patch)收集足够的数据后清理类和挂钩
v = v . eject () # wrapper is discarded and original ViT instance is returned 您可以使用Extractor包装器类似地访问嵌入
import torch
from vit_pytorch . vit import ViT
v = ViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
# import Recorder and wrap the ViT
from vit_pytorch . extractor import Extractor
v = Extractor ( v )
# forward pass now returns predictions and the attention maps
img = torch . randn ( 1 , 3 , 256 , 256 )
logits , embeddings = v ( img )
# there is one extra token due to the CLS token
embeddings # (1, 65, 1024) - (batch x patches x model dim)或者说CrossViT ,它有一个多尺度编码器,可以输出“大”和“小”尺度的两组嵌入
import torch
from vit_pytorch . cross_vit import CrossViT
v = CrossViT (
image_size = 256 ,
num_classes = 1000 ,
depth = 4 ,
sm_dim = 192 ,
sm_patch_size = 16 ,
sm_enc_depth = 2 ,
sm_enc_heads = 8 ,
sm_enc_mlp_dim = 2048 ,
lg_dim = 384 ,
lg_patch_size = 64 ,
lg_enc_depth = 3 ,
lg_enc_heads = 8 ,
lg_enc_mlp_dim = 2048 ,
cross_attn_depth = 2 ,
cross_attn_heads = 8 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
# wrap the CrossViT
from vit_pytorch . extractor import Extractor
v = Extractor ( v , layer_name = 'multi_scale_encoder' ) # take embedding coming from the output of multi-scale-encoder
# forward pass now returns predictions and the attention maps
img = torch . randn ( 1 , 3 , 256 , 256 )
logits , embeddings = v ( img )
# there is one extra token due to the CLS token
embeddings # ((1, 257, 192), (1, 17, 384)) - (batch x patches x dimension) <- large and small scales respectively 可能有些来自计算机视觉的人认为注意力仍然受到二次成本的影响。幸运的是,我们有很多可能有帮助的新技术。该存储库为您提供了一种插入自己的稀疏注意力转换器的方法。
Nystromformer 的示例
$ pip install nystrom-attention import torch
from vit_pytorch . efficient import ViT
from nystrom_attention import Nystromformer
efficient_transformer = Nystromformer (
dim = 512 ,
depth = 12 ,
heads = 8 ,
num_landmarks = 256
)
v = ViT (
dim = 512 ,
image_size = 2048 ,
patch_size = 32 ,
num_classes = 1000 ,
transformer = efficient_transformer
)
img = torch . randn ( 1 , 3 , 2048 , 2048 ) # your high resolution picture
v ( img ) # (1, 1000)我强烈推荐的其他稀疏注意力框架是 Routing Transformer 或 Sinkhorn Transformer
本文特意使用了最普通的注意力网络来发表声明。如果您想使用注意力网络的一些最新改进,请使用此存储库中的Encoder 。
前任。
$ pip install x-transformers import torch
from vit_pytorch . efficient import ViT
from x_transformers import Encoder
v = ViT (
dim = 512 ,
image_size = 224 ,
patch_size = 16 ,
num_classes = 1000 ,
transformer = Encoder (
dim = 512 , # set to be the same as the wrapper
depth = 12 ,
heads = 8 ,
ff_glu = True , # ex. feed forward GLU variant https://arxiv.org/abs/2002.05202
residual_attn = True # ex. residual attention https://arxiv.org/abs/2012.11747
)
)
img = torch . randn ( 1 , 3 , 224 , 224 )
v ( img ) # (1, 1000) 您已经可以传递非方形图像 - 您只需确保您的高度和宽度小于或等于image_size ,并且都可以被patch_size整除
前任。
import torch
from vit_pytorch import ViT
v = ViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 1 , 3 , 256 , 128 ) # <-- not a square
preds = v ( img ) # (1, 1000) import torch
from vit_pytorch import ViT
v = ViT (
num_classes = 1000 ,
image_size = ( 256 , 128 ), # image size is a tuple of (height, width)
patch_size = ( 32 , 16 ), # patch size is a tuple of (height, width)
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 1 , 3 , 256 , 128 )
preds = v ( img )来自计算机视觉并且是变形金刚的新手?这里有一些资源极大地加快了我的学习速度。
变压器插图 - Jay Alammar
从零开始的变形金刚 - 彼得·布洛姆
带注释的 Transformer - 哈佛 NLP
@article { hassani2021escaping ,
title = { Escaping the Big Data Paradigm with Compact Transformers } ,
author = { Ali Hassani and Steven Walton and Nikhil Shah and Abulikemu Abuduweili and Jiachen Li and Humphrey Shi } ,
year = 2021 ,
url = { https://arxiv.org/abs/2104.05704 } ,
eprint = { 2104.05704 } ,
archiveprefix = { arXiv } ,
primaryclass = { cs.CV }
} @misc { dosovitskiy2020image ,
title = { An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale } ,
author = { Alexey Dosovitskiy and Lucas Beyer and Alexander Kolesnikov and Dirk Weissenborn and Xiaohua Zhai and Thomas Unterthiner and Mostafa Dehghani and Matthias Minderer and Georg Heigold and Sylvain Gelly and Jakob Uszkoreit and Neil Houlsby } ,
year = { 2020 } ,
eprint = { 2010.11929 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { touvron2020training ,
title = { Training data-efficient image transformers & distillation through attention } ,
author = { Hugo Touvron and Matthieu Cord and Matthijs Douze and Francisco Massa and Alexandre Sablayrolles and Hervé Jégou } ,
year = { 2020 } ,
eprint = { 2012.12877 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { yuan2021tokenstotoken ,
title = { Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet } ,
author = { Li Yuan and Yunpeng Chen and Tao Wang and Weihao Yu and Yujun Shi and Francis EH Tay and Jiashi Feng and Shuicheng Yan } ,
year = { 2021 } ,
eprint = { 2101.11986 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { zhou2021deepvit ,
title = { DeepViT: Towards Deeper Vision Transformer } ,
author = { Daquan Zhou and Bingyi Kang and Xiaojie Jin and Linjie Yang and Xiaochen Lian and Qibin Hou and Jiashi Feng } ,
year = { 2021 } ,
eprint = { 2103.11886 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { touvron2021going ,
title = { Going deeper with Image Transformers } ,
author = { Hugo Touvron and Matthieu Cord and Alexandre Sablayrolles and Gabriel Synnaeve and Hervé Jégou } ,
year = { 2021 } ,
eprint = { 2103.17239 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { chen2021crossvit ,
title = { CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification } ,
author = { Chun-Fu Chen and Quanfu Fan and Rameswar Panda } ,
year = { 2021 } ,
eprint = { 2103.14899 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { wu2021cvt ,
title = { CvT: Introducing Convolutions to Vision Transformers } ,
author = { Haiping Wu and Bin Xiao and Noel Codella and Mengchen Liu and Xiyang Dai and Lu Yuan and Lei Zhang } ,
year = { 2021 } ,
eprint = { 2103.15808 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { heo2021rethinking ,
title = { Rethinking Spatial Dimensions of Vision Transformers } ,
author = { Byeongho Heo and Sangdoo Yun and Dongyoon Han and Sanghyuk Chun and Junsuk Choe and Seong Joon Oh } ,
year = { 2021 } ,
eprint = { 2103.16302 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { graham2021levit ,
title = { LeViT: a Vision Transformer in ConvNet's Clothing for Faster Inference } ,
author = { Ben Graham and Alaaeldin El-Nouby and Hugo Touvron and Pierre Stock and Armand Joulin and Hervé Jégou and Matthijs Douze } ,
year = { 2021 } ,
eprint = { 2104.01136 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { li2021localvit ,
title = { LocalViT: Bringing Locality to Vision Transformers } ,
author = { Yawei Li and Kai Zhang and Jiezhang Cao and Radu Timofte and Luc Van Gool } ,
year = { 2021 } ,
eprint = { 2104.05707 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { chu2021twins ,
title = { Twins: Revisiting Spatial Attention Design in Vision Transformers } ,
author = { Xiangxiang Chu and Zhi Tian and Yuqing Wang and Bo Zhang and Haibing Ren and Xiaolin Wei and Huaxia Xia and Chunhua Shen } ,
year = { 2021 } ,
eprint = { 2104.13840 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { su2021roformer ,
title = { RoFormer: Enhanced Transformer with Rotary Position Embedding } ,
author = { Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu } ,
year = { 2021 } ,
eprint = { 2104.09864 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @misc { zhang2021aggregating ,
title = { Aggregating Nested Transformers } ,
author = { Zizhao Zhang and Han Zhang and Long Zhao and Ting Chen and Tomas Pfister } ,
year = { 2021 } ,
eprint = { 2105.12723 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { chen2021regionvit ,
title = { RegionViT: Regional-to-Local Attention for Vision Transformers } ,
author = { Chun-Fu Chen and Rameswar Panda and Quanfu Fan } ,
year = { 2021 } ,
eprint = { 2106.02689 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { wang2021crossformer ,
title = { CrossFormer: A Versatile Vision Transformer Hinging on Cross-scale Attention } ,
author = { Wenxiao Wang and Lu Yao and Long Chen and Binbin Lin and Deng Cai and Xiaofei He and Wei Liu } ,
year = { 2021 } ,
eprint = { 2108.00154 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { caron2021emerging ,
title = { Emerging Properties in Self-Supervised Vision Transformers } ,
author = { Mathilde Caron and Hugo Touvron and Ishan Misra and Hervé Jégou and Julien Mairal and Piotr Bojanowski and Armand Joulin } ,
year = { 2021 } ,
eprint = { 2104.14294 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { he2021masked ,
title = { Masked Autoencoders Are Scalable Vision Learners } ,
author = { Kaiming He and Xinlei Chen and Saining Xie and Yanghao Li and Piotr Dollár and Ross Girshick } ,
year = { 2021 } ,
eprint = { 2111.06377 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { xie2021simmim ,
title = { SimMIM: A Simple Framework for Masked Image Modeling } ,
author = { Zhenda Xie and Zheng Zhang and Yue Cao and Yutong Lin and Jianmin Bao and Zhuliang Yao and Qi Dai and Han Hu } ,
year = { 2021 } ,
eprint = { 2111.09886 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { fayyaz2021ats ,
title = { ATS: Adaptive Token Sampling For Efficient Vision Transformers } ,
author = { Mohsen Fayyaz and Soroush Abbasi Kouhpayegani and Farnoush Rezaei Jafari and Eric Sommerlade and Hamid Reza Vaezi Joze and Hamed Pirsiavash and Juergen Gall } ,
year = { 2021 } ,
eprint = { 2111.15667 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { mehta2021mobilevit ,
title = { MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer } ,
author = { Sachin Mehta and Mohammad Rastegari } ,
year = { 2021 } ,
eprint = { 2110.02178 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { lee2021vision ,
title = { Vision Transformer for Small-Size Datasets } ,
author = { Seung Hoon Lee and Seunghyun Lee and Byung Cheol Song } ,
year = { 2021 } ,
eprint = { 2112.13492 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { renggli2022learning ,
title = { Learning to Merge Tokens in Vision Transformers } ,
author = { Cedric Renggli and André Susano Pinto and Neil Houlsby and Basil Mustafa and Joan Puigcerver and Carlos Riquelme } ,
year = { 2022 } ,
eprint = { 2202.12015 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { yang2022scalablevit ,
title = { ScalableViT: Rethinking the Context-oriented Generalization of Vision Transformer } ,
author = { Rui Yang and Hailong Ma and Jie Wu and Yansong Tang and Xuefeng Xiao and Min Zheng and Xiu Li } ,
year = { 2022 } ,
eprint = { 2203.10790 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @inproceedings { Touvron2022ThreeTE ,
title = { Three things everyone should know about Vision Transformers } ,
author = { Hugo Touvron and Matthieu Cord and Alaaeldin El-Nouby and Jakob Verbeek and Herv'e J'egou } ,
year = { 2022 }
} @inproceedings { Sandler2022FinetuningIT ,
title = { Fine-tuning Image Transformers using Learnable Memory } ,
author = { Mark Sandler and Andrey Zhmoginov and Max Vladymyrov and Andrew Jackson } ,
year = { 2022 }
} @inproceedings { Li2022SepViTSV ,
title = { SepViT: Separable Vision Transformer } ,
author = { Wei Li and Xing Wang and Xin Xia and Jie Wu and Xuefeng Xiao and Minghang Zheng and Shiping Wen } ,
year = { 2022 }
} @inproceedings { Tu2022MaxViTMV ,
title = { MaxViT: Multi-Axis Vision Transformer } ,
author = { Zhengzhong Tu and Hossein Talebi and Han Zhang and Feng Yang and Peyman Milanfar and Alan Conrad Bovik and Yinxiao Li } ,
year = { 2022 }
} @article { Li2021EfficientSV ,
title = { Efficient Self-supervised Vision Transformers for Representation Learning } ,
author = { Chunyuan Li and Jianwei Yang and Pengchuan Zhang and Mei Gao and Bin Xiao and Xiyang Dai and Lu Yuan and Jianfeng Gao } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2106.09785 }
} @misc { Beyer2022BetterPlainViT
title = { Better plain ViT baselines for ImageNet-1k } ,
author = { Beyer, Lucas and Zhai, Xiaohua and Kolesnikov, Alexander } ,
publisher = { arXiv } ,
year = { 2022 }
}
@article { Arnab2021ViViTAV ,
title = { ViViT: A Video Vision Transformer } ,
author = { Anurag Arnab and Mostafa Dehghani and Georg Heigold and Chen Sun and Mario Lucic and Cordelia Schmid } ,
journal = { 2021 IEEE/CVF International Conference on Computer Vision (ICCV) } ,
year = { 2021 } ,
pages = { 6816-6826 }
} @article { Liu2022PatchDropoutEV ,
title = { PatchDropout: Economizing Vision Transformers Using Patch Dropout } ,
author = { Yue Liu and Christos Matsoukas and Fredrik Strand and Hossein Azizpour and Kevin Smith } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2208.07220 }
} @misc { https://doi.org/10.48550/arxiv.2302.01327 ,
doi = { 10.48550/ARXIV.2302.01327 } ,
url = { https://arxiv.org/abs/2302.01327 } ,
author = { Kumar, Manoj and Dehghani, Mostafa and Houlsby, Neil } ,
title = { Dual PatchNorm } ,
publisher = { arXiv } ,
year = { 2023 } ,
copyright = { Creative Commons Attribution 4.0 International }
} @inproceedings { Dehghani2023PatchNP ,
title = { Patch n' Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution } ,
author = { Mostafa Dehghani and Basil Mustafa and Josip Djolonga and Jonathan Heek and Matthias Minderer and Mathilde Caron and Andreas Steiner and Joan Puigcerver and Robert Geirhos and Ibrahim M. Alabdulmohsin and Avital Oliver and Piotr Padlewski and Alexey A. Gritsenko and Mario Luvci'c and Neil Houlsby } ,
year = { 2023 }
} @misc { vaswani2017attention ,
title = { Attention Is All You Need } ,
author = { Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin } ,
year = { 2017 } ,
eprint = { 1706.03762 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Darcet2023VisionTN ,
title = { Vision Transformers Need Registers } ,
author = { Timoth'ee Darcet and Maxime Oquab and Julien Mairal and Piotr Bojanowski } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:263134283 }
} @inproceedings { ElNouby2021XCiTCI ,
title = { XCiT: Cross-Covariance Image Transformers } ,
author = { Alaaeldin El-Nouby and Hugo Touvron and Mathilde Caron and Piotr Bojanowski and Matthijs Douze and Armand Joulin and Ivan Laptev and Natalia Neverova and Gabriel Synnaeve and Jakob Verbeek and Herv{'e} J{'e}gou } ,
booktitle = { Neural Information Processing Systems } ,
year = { 2021 } ,
url = { https://api.semanticscholar.org/CorpusID:235458262 }
} @inproceedings { Koner2024LookupViTCV ,
title = { LookupViT: Compressing visual information to a limited number of tokens } ,
author = { Rajat Koner and Gagan Jain and Prateek Jain and Volker Tresp and Sujoy Paul } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:271244592 }
} @article { Bao2022AllAW ,
title = { All are Worth Words: A ViT Backbone for Diffusion Models } ,
author = { Fan Bao and Shen Nie and Kaiwen Xue and Yue Cao and Chongxuan Li and Hang Su and Jun Zhu } ,
journal = { 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2022 } ,
pages = { 22669-22679 } ,
url = { https://api.semanticscholar.org/CorpusID:253581703 }
} @misc { Rubin2024 ,
author = { Ohad Rubin } ,
url = { https://medium.com/ @ ohadrubin/exploring-weight-decay-in-layer-normalization-challenges-and-a-reparameterization-solution-ad4d12c24950 }
} @inproceedings { Loshchilov2024nGPTNT ,
title = { nGPT: Normalized Transformer with Representation Learning on the Hypersphere } ,
author = { Ilya Loshchilov and Cheng-Ping Hsieh and Simeng Sun and Boris Ginsburg } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273026160 }
} @inproceedings { Liu2017DeepHL ,
title = { Deep Hyperspherical Learning } ,
author = { Weiyang Liu and Yanming Zhang and Xingguo Li and Zhen Liu and Bo Dai and Tuo Zhao and Le Song } ,
booktitle = { Neural Information Processing Systems } ,
year = { 2017 } ,
url = { https://api.semanticscholar.org/CorpusID:5104558 }
} @inproceedings { Zhou2024ValueRL ,
title = { Value Residual Learning For Alleviating Attention Concentration In Transformers } ,
author = { Zhanchao Zhou and Tianyi Wu and Zhiyun Jiang and Zhenzhong Lan } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273532030 }
} @article { Zhu2024HyperConnections ,
title = { Hyper-Connections } ,
author = { Defa Zhu and Hongzhi Huang and Zihao Huang and Yutao Zeng and Yunyao Mao and Banggu Wu and Qiyang Min and Xun Zhou } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2409.19606 } ,
url = { https://api.semanticscholar.org/CorpusID:272987528 }
}我想象有一天我们对于机器人就像狗对于人类一样,我支持机器。 — 克劳德·香农


