parti pytorch
0.2.0
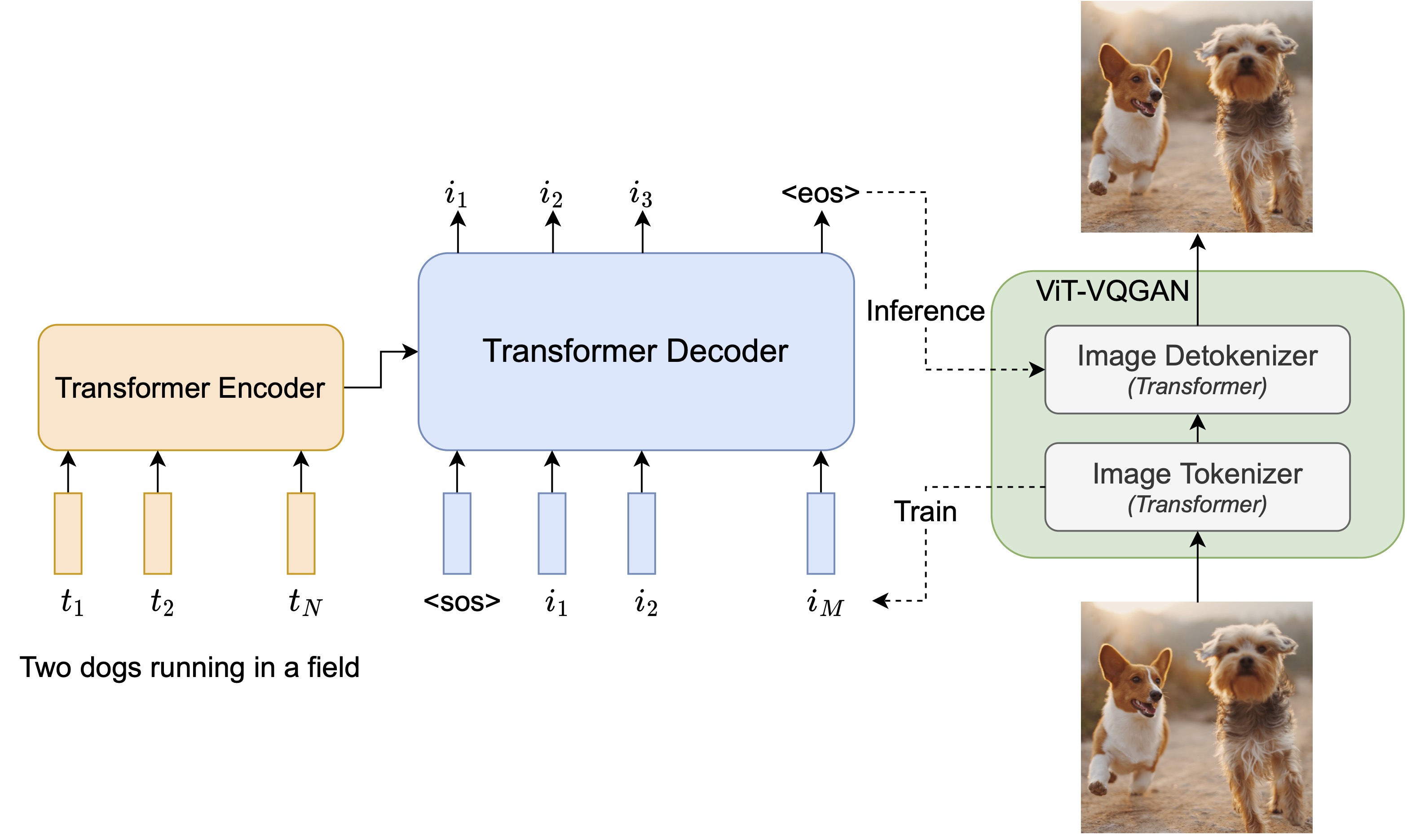
在 Pytorch 中实现 Parti,这是 Google 纯基于注意力的文本到图像神经网络。项目页面
该存储库还包含 ViT VQGan VAE 的工作训练代码。它还包含一些额外的修改,以便根据视觉转换器文献进行更快的训练。
雅尼克·基尔彻
如果您有兴趣帮助 LAION 社区进行复制,请加入
$ pip install parti-pytorch首先,您需要训练您的 Transformer VQ-GAN VAE
from parti_pytorch import VitVQGanVAE , VQGanVAETrainer
vit_vae = VitVQGanVAE (
dim = 256 , # dimensions
image_size = 256 , # target image size
patch_size = 16 , # size of the patches in the image attending to each other
num_layers = 3 # number of layers
). cuda ()
trainer = VQGanVAETrainer (
vit_vae ,
folder = '/path/to/your/images' ,
num_train_steps = 100000 ,
lr = 3e-4 ,
batch_size = 4 ,
grad_accum_every = 8 ,
amp = True
)
trainer . train ()然后
import torch
from parti_pytorch import Parti , VitVQGanVAE
# first instantiate your ViT VQGan VAE
# a VQGan VAE made of transformers
vit_vae = VitVQGanVAE (
dim = 256 , # dimensions
image_size = 256 , # target image size
patch_size = 16 , # size of the patches in the image attending to each other
num_layers = 3 # number of layers
). cuda ()
vit_vae . load_state_dict ( torch . load ( f'/path/to/vae.pt' )) # you will want to load the exponentially moving averaged VAE
# then you plugin the ViT VqGan VAE into your Parti as so
parti = Parti (
vae = vit_vae , # vit vqgan vae
dim = 512 , # model dimension
depth = 8 , # depth
dim_head = 64 , # attention head dimension
heads = 8 , # attention heads
dropout = 0. , # dropout
cond_drop_prob = 0.25 , # conditional dropout, for classifier free guidance
ff_mult = 4 , # feedforward expansion factor
t5_name = 't5-large' , # name of your T5
)
# ready your training text and images
texts = [
'a child screaming at finding a worm within a half-eaten apple' ,
'lizard running across the desert on two feet' ,
'waking up to a psychedelic landscape' ,
'seashells sparkling in the shallow waters'
]
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed it into your parti instance, with return_loss set to True
loss = parti (
texts = texts ,
images = images ,
return_loss = True
)
loss . backward ()
# do this for a long time on much data
# then...
images = parti . generate ( texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
], cond_scale = 3. , return_pil_images = True ) # conditioning scale for classifier free guidance
# List[PILImages] (256 x 256 RGB)实际上,在扩展时,您需要将文本预先编码为标记及其各自的掩码
from parti_pytorch . t5 import t5_encode_text
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
text_token_embeds , text_mask = t5_encode_text ([
'a child screaming at finding a worm within a half-eaten apple' ,
'lizard running across the desert on two feet' ,
'waking up to a psychedelic landscape' ,
'seashells sparkling in the shallow waters'
], name = 't5-large' , output_device = images . device )
# store somewhere, then load with the dataloader
loss = parti (
text_token_embeds = text_token_embeds ,
text_mask = text_mask ,
images = images ,
return_loss = True
)
loss . backward ()StabilityAI 以及我的其他赞助商为我提供了开源人工智能的独立性。
? Huggingface 的 Transformer 库以及使用 T5 语言模型轻松编码文本
@inproceedings { Yu2022Pathways
title = { Pathways Autoregressive Text-to-Image Model } ,
author = { Jiahui Yu*, Yuanzhong Xu†, Jing Yu Koh†, Thang Luong†, Gunjan Baid†, Zirui Wang†, Vijay Vasudevan†, Alexander Ku†, Yinfei Yang, Burcu Karagol Ayan, Ben Hutchinson, Wei Han, Zarana Parekh, Xin Li, Han Zhang, Jason Baldridge†, Yonghui Wu* } ,
year = { 2022 }
} @article { Shleifer2021NormFormerIT ,
title = { NormFormer: Improved Transformer Pretraining with Extra Normalization } ,
author = { Sam Shleifer and Jason Weston and Myle Ott } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2110.09456 }
} @article { Sankararaman2022BayesFormerTW ,
title = { BayesFormer: Transformer with Uncertainty Estimation } ,
author = { Karthik Abinav Sankararaman and Sinong Wang and Han Fang } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2206.00826 }
} @article { Lee2021VisionTF ,
title = { Vision Transformer for Small-Size Datasets } ,
author = { Seung Hoon Lee and Seunghyun Lee and Byung Cheol Song } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2112.13492 }
} @article { Chu2021DoWR ,
title = { Do We Really Need Explicit Position Encodings for Vision Transformers? } ,
author = { Xiangxiang Chu and Bo Zhang and Zhi Tian and Xiaolin Wei and Huaxia Xia } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2102.10882 }
} @article { So2021PrimerSF ,
title = { Primer: Searching for Efficient Transformers for Language Modeling } ,
author = { David R. So and Wojciech Ma'nke and Hanxiao Liu and Zihang Dai and Noam M. Shazeer and Quoc V. Le } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2109.08668 }
} @inproceedings { Wang2021CrossFormerAV ,
title = { CrossFormer: A Versatile Vision Transformer Hinging on Cross-scale Attention } ,
author = { Wenxiao Wang and Lulian Yao and Long Chen and Binbin Lin and Deng Cai and Xiaofei He and Wei Liu } ,
year = { 2021 }
} @misc { mentzer2023finite ,
title = { Finite Scalar Quantization: VQ-VAE Made Simple } ,
author = { Fabian Mentzer and David Minnen and Eirikur Agustsson and Michael Tschannen } ,
year = { 2023 } ,
eprint = { 2309.15505 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { yu2023language ,
title = { Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation } ,
author = { Lijun Yu and José Lezama and Nitesh B. Gundavarapu and Luca Versari and Kihyuk Sohn and David Minnen and Yong Cheng and Agrim Gupta and Xiuye Gu and Alexander G. Hauptmann and Boqing Gong and Ming-Hsuan Yang and Irfan Essa and David A. Ross and Lu Jiang } ,
year = { 2023 } ,
eprint = { 2310.05737 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

