Always Learning
1.0.0
最近更新日期:2020/06/28
最近一周新增:
目录:
W(n, k) = 1 + min{max(W(n -1, x -1), W(n, k - x))}, x in {2, 3, ……,k}(n是杯子数,k是楼层数)character_set_client、character_set_connection、character_set_database、character_set_results、character_set_server、character_set_system)、数据库索引(主键索引、聚集索引和非聚集索引)等基础知识点。__iter__()函数,调用iter()之后,变成了一个list_iterator的对象,会发现增加了__next__()方法,所有实现了__iter__和__next__两个方法的对象,都是迭代器),迭代器是带状态的对象,它会记录当前迭代所处的位置,以方便下次迭代的时候获取正确的元素,__iter__返回迭代器自身,__next__返回容器的下一个值。生成器:使用了yield的函数被称为生成器,调用了一个生成器函数,返回的是一个迭代器对象,生成器可以看成是迭代器。\u72 产生的原因就是浏览器的html自解码)<a href=javascript:alert(1)>click</a>中alert(1)处在html->url->js环境中。
1、click 采用unicode编码e,html和url环境下都不能解码,只有在js环境下才能解码为字符e,所以不会弹窗
python requests库流程简析
python requests库实现:socket->httplib->urllib->urllib3->requests。requests.get的内部调用流程:requests.get->requests()->Session.request->Session.send->adapter.send->HTTPConnectionPool(urllib3)->HTTPConnection(httplib)。
1、socket:是TCP/IP最直接的实现,实现端到端的网络传输
2、httplib:基于socket库,是最基础最底层的http库,主要将数据按照http协议组织,然后创建socket连接,将封装的数据发往服务端
3、urllib:基于httplib库,主要对url的解析和编码做进一步处理
4、urllib3:基于httplib库,相较于urllib更高级的地方在于用PoolManager实现了socket连接复用和线程安全,提高了效率
5、requests:基于urllib3库,比urllib3更高级的是实现了Session对象,用Session对象保存一些数据状态,进一步提高了效率
XGBoost原理和底层实现剖析(学到了)
XGBoost:从树的分数(目标函数:损失函数(二阶展开)+正则项),树的结构(分裂决策(预排序))方面理解。
Lightgbm 直方图优化算法深入理解
Lightgbm:相较于预排序而言,lgb采用了直方图来处理节点分裂,寻找最优分割点。算法思想:在训练前预先把特征值转化为bin value,也就是对每个特征的取值做分段函数,将所有样本在该特征上的取值划分到某一段(bin)中,最终把特征取值从连续值转化为离散值。直方图也可以用来做差加速,计算直方图的复杂度是基于桶的个数的。
keras文本预处理源码分析
Keras-文本预处理: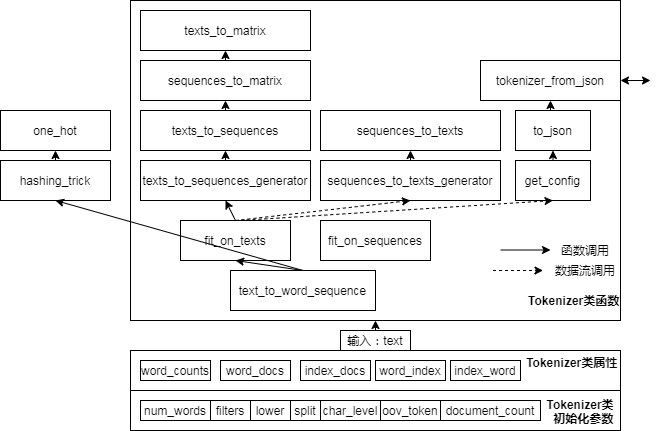
keras序列预处理源码分析
select id,ip from client_ip where 1>2 union select * from ( (select user())a JOIN (select version())b ); 使用select case when(条件) then 代码1 else 代码2 end绕过逗号过滤,insert into client_ip (ip) values ('ip'+(select case when (substring((select user()) from 1 for 1)='e') then sleep(3) else 0 end));http://[email protected]/;通过各种非HTTP协议0xA1-0xF7,低位0xA1-0xFE,而0x5c,不在低位范围中,所以0x5c不是gb2312中的编码,所以不会被吃掉。把这个思路拓宽到所有的多字节编码,只要低位的范围中含有0x5c的编码,就可以进行宽字节注入)。防御方案一:mysql_set_charset+mysql_real_escape_string,考虑到连接的当前字符集。防御方案二:将character_set_client设置为binary(二进制),SET character_set_connection=gbk, character_set_results=gbk,character_set_client=binary。当我们的mysql接受到客户端的数据后,会认为他的编码是character_set_client,然后会将之将换成character_set_connection的编码,然后进入具体表和字段后,再转换成字段对应的编码。然后,当查询结果产生后,会从表和字段的编码,转换成character_set_results编码,返回给客户端。所以,我们将character_set_client设置成binary,就不存在宽字节或多字节的问题了,所有数据以二进制的形式传递,就能有效避免宽字符注入。防御过后调用iconv时也可能出现问题。使用iconv对utf-8转gbk时,利用方式是錦',原因是它的utf-8编码是0xe98ca6,它的gbk编码是0xe55c,最后变成%e5%5c%5c%27,两个%5c就是'前面的字符是奇数的话,势必会吞掉'逃出限制。为什么不能用錦'这种方式呢,根据utf-8编码规则,(0x0000005c)不会出现在utf-8编码中,所以会报错。eval、preg_replace+/e、assert、call_user_func、call_user_func_array、create_function;命令执行函数:system、exec、shell_exec、passthru、pcntl_exec、popen、proc_open;img标签除了onerror属性外,还有其他获取管理员路径的方式吗?src指定一个远程的脚本文件,获取referer。这个可爱的 泰迪 舔了我的脸和这个可爱的 京巴 舔了我的脸,用输入单词 x 作为中心单词去预测其他单词 z 出现在其周边的可能性(至此我才明白为什么说词嵌入是神经网络训练语言模型的副产品这句话)。用输入单词作为中心单词去预测周边单词的方式叫skip-gram,用输入单词作为周边单词去预测中心单词的方式叫CBOW。至关重要:如何做好我们的职业规划(学到了)
数据科学家 (Data Scientist) 的核心技能是什么?


