atari
1.0.0

研究游乐场建立在 OpenAI 的 Atari Gym 之上,为实施各种强化学习算法做好了准备。
它可以模拟以下任何游戏:
['Asterix'、'Asteroids'、'MsPacman'、'Kaboom'、'BankHeist'、'Kangaroo'、'Skiing'、'FishingDerby'、'Krull'、'Berzerk'、'Tutankham'、'Zaxxon'、'冒险”、“河滩”、“蜈蚣”、 《冒险》、《BeamRider》、《CrazyClimber》、《TimePilot》、《嘉年华》、《网球》、《Seaquest》、《保龄球》、《太空入侵者》、《高速公路》、《YarsRevenge》、《RoadRunner》、《JourneyEscape》 ', 'WizardOfWor', '地鼠', 《Breakout》、《StarGunner》、《Atlantis》、《DoubleDunk》、《Hero》、《BattleZone》、《Solaris》、《UpNDown》、《Frostbite》、《KungFuMaster》、《Pooyan》、《Pitfall》、《MontezumaRevenge》 '、'PrivateEye'、'空袭'、 “Amidar”、“Robotank”、“DemonAttack”、“Defender”、“NameThisGame”、“Phoenix”、“Gravitar”、“ElevatorAction”、“Pong”、“VideoPinball”、“IceHockey”、“Boxing”、“Assault” '、'外星人'、'Qbert'、'Enduro'、 “斩波指挥”、“詹姆斯邦德”]
查看相应的 Medium 文章:Atari - 深度强化学习? (第 1 部分:DDQN)
该项目的最终目标是实施和比较各种 RL 方法,并以 Atari 游戏作为共同点。
pip install -r requirements.txt 。python atari.py --help 。 * GAMMA = 0.99
* MEMORY_SIZE = 900000
* BATCH_SIZE = 32
* TRAINING_FREQUENCY = 4
* TARGET_NETWORK_UPDATE_FREQUENCY = 40000
* MODEL_PERSISTENCE_UPDATE_FREQUENCY = 10000
* REPLAY_START_SIZE = 50000
* EXPLORATION_MAX = 1.0
* EXPLORATION_MIN = 0.1
* EXPLORATION_TEST = 0.02
* EXPLORATION_STEPS = 850000
DeepMind 的深度卷积神经网络
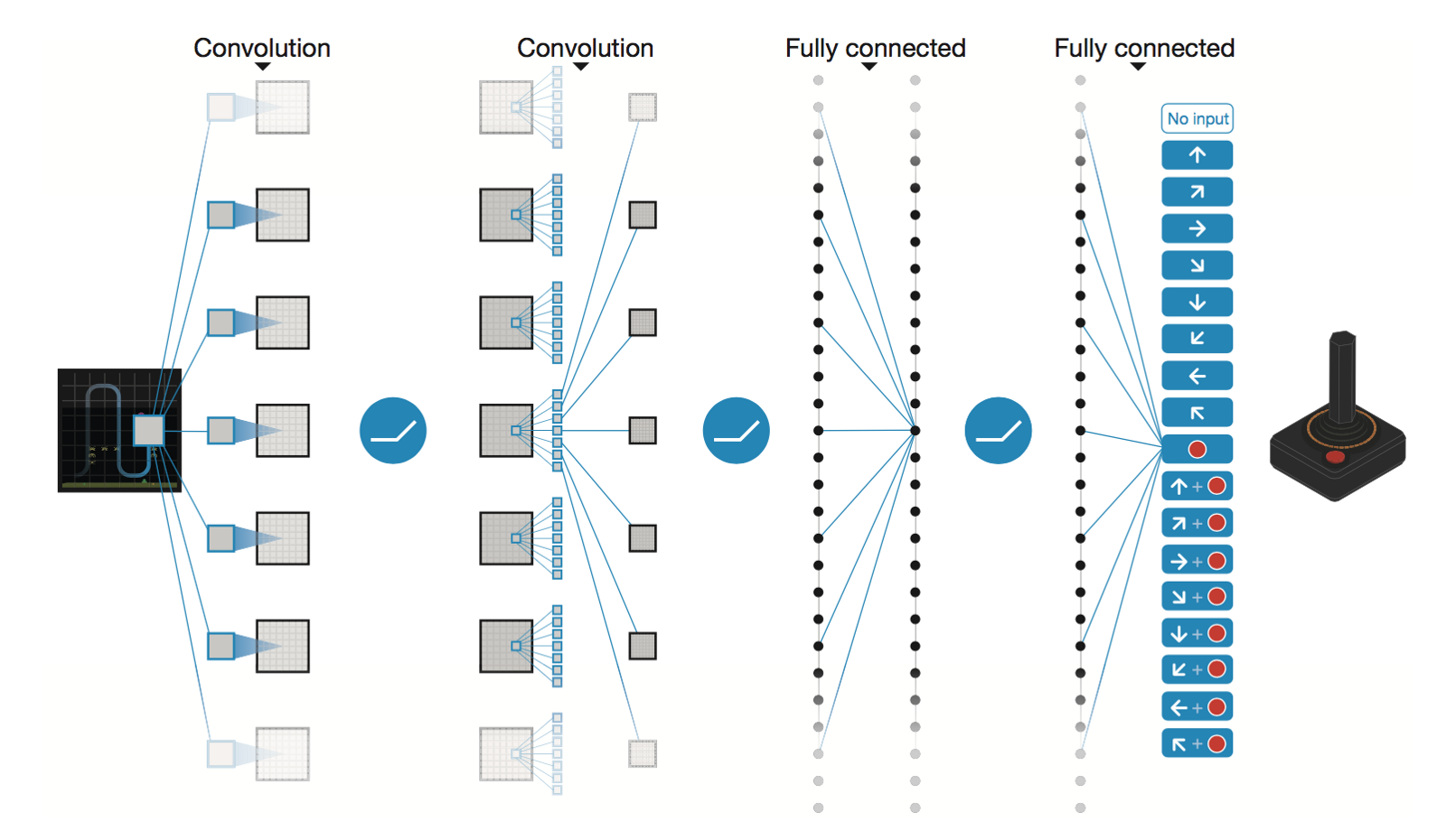
* Conv2D (None, 32, 20, 20)
* Conv2D (None, 64, 9, 9)
* Conv2D (None, 64, 7, 7)
* Flatten (None, 3136)
* Dense (None, 512)
* Dense (None, 4)
Trainable params: 1,686,180
5M 步后(Tesla K80 GPU 上约为 40 小时,2.9 GHz Intel i7 四核 CPU 上约为 90 小时):
训练:
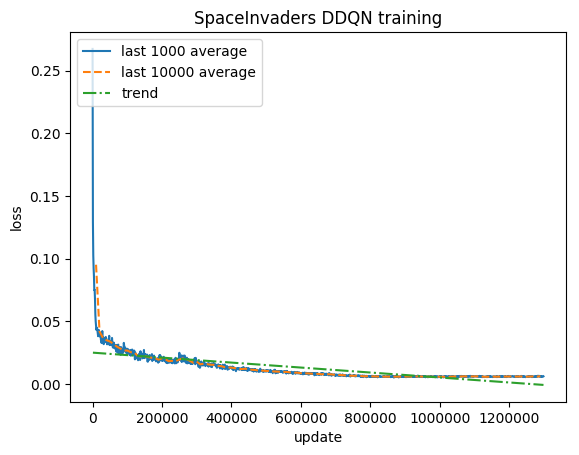
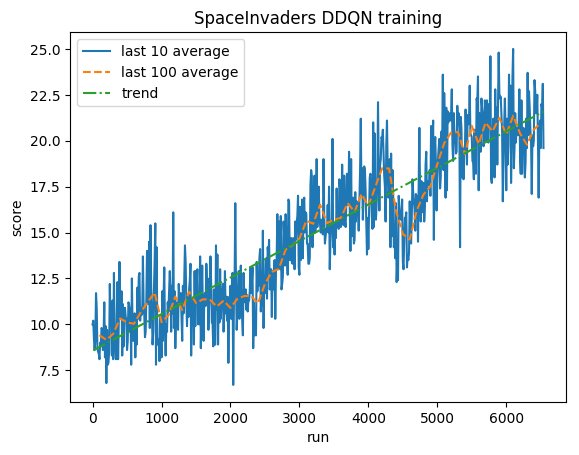
标准化分数 - 每个奖励被剪裁为 (-1, 1)
测试:
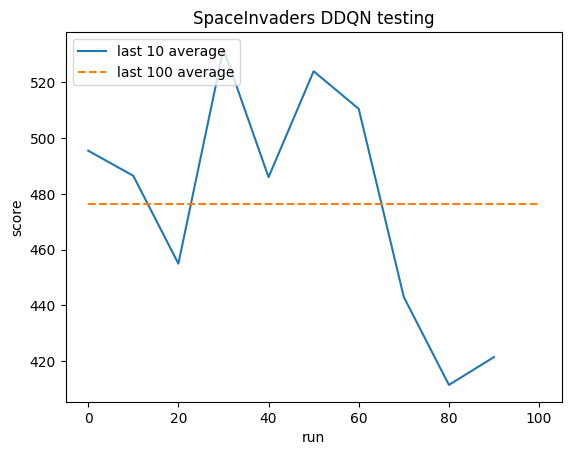
人类平均水平: ~372
DDQN 平均值: ~479 (128%)
训练:
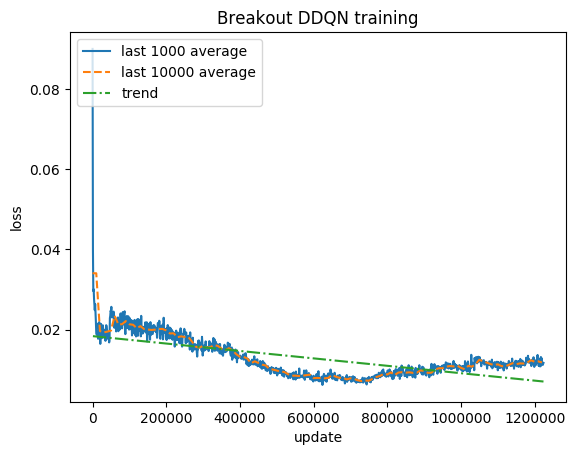
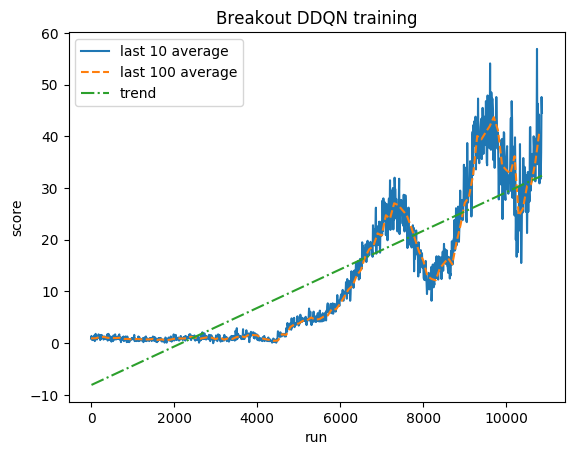
标准化分数 - 每个奖励被剪裁为 (-1, 1)
测试:
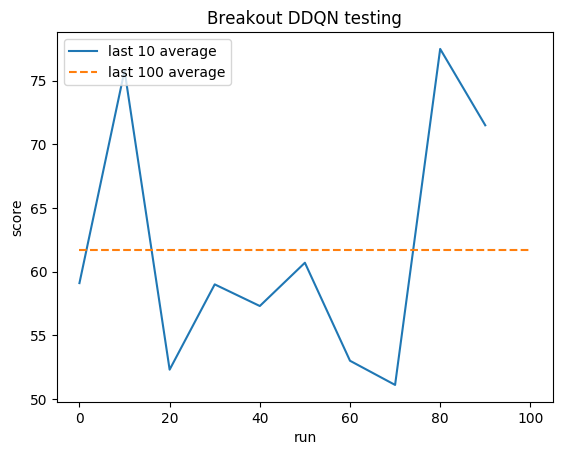
人类平均水平: ~28
DDQN 平均值: ~62 (221%)
训练:
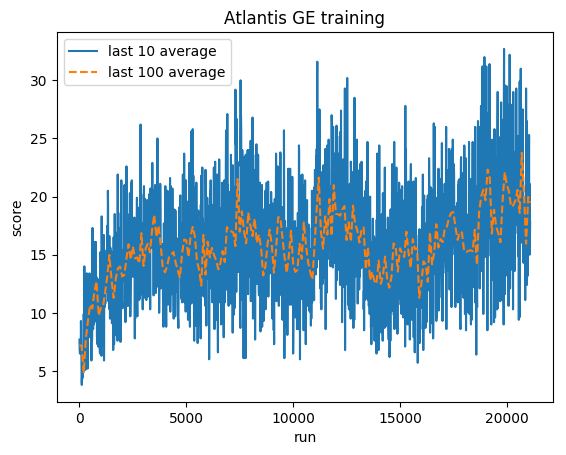
标准化分数 - 每个奖励被剪裁为 (-1, 1)
测试:

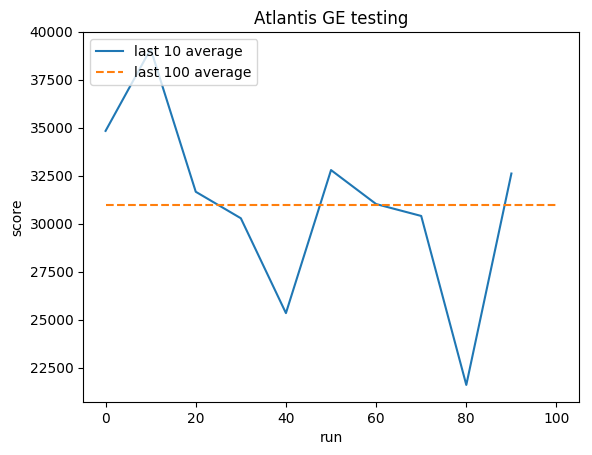
人类平均: ~29,000
GE 平均值: 31,000 (106%)
格雷格·苏尔马
文件夹
吉特布
博客


