musiclm pytorch
0.2.8
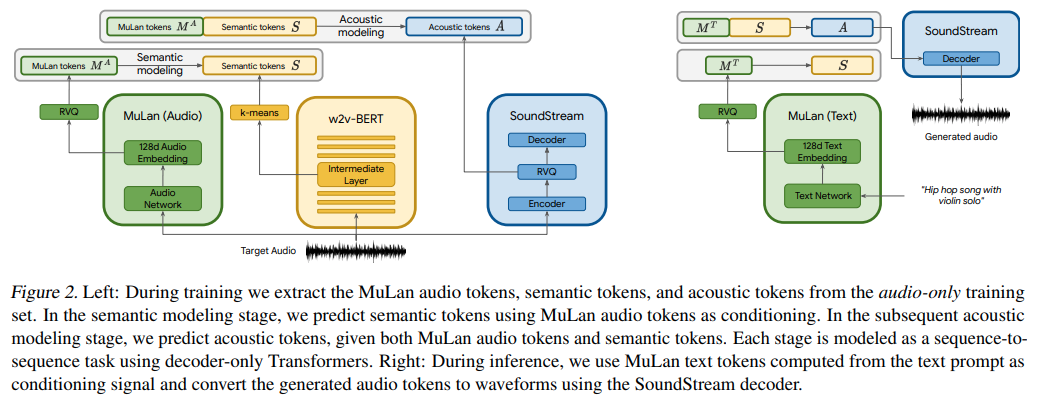
在 Pytorch 中实现 MusicLM,这是 Google 使用注意力网络生成音乐的新 SOTA 模型。
他们基本上使用文本条件的 AudioLM,但令人惊讶的是使用名为 MuLan 的文本音频对比学习模型的嵌入。 MuLan 是在此存储库中构建的内容,AudioLM 是从其他存储库修改而来的,以支持此处的音乐生成需求。
如果您有兴趣帮助 LAION 社区进行复制,请加入
路易斯·布沙尔 (Louis Bouchard) 的《什么是人工智能》
Stability.ai 慷慨赞助工作和开源尖端人工智能研究
? Huggingface 的加速训练库
$ pip install musiclm-pytorch
MuLaN首先需要训练
import torch
from musiclm_pytorch import MuLaN , AudioSpectrogramTransformer , TextTransformer
audio_transformer = AudioSpectrogramTransformer (
dim = 512 ,
depth = 6 ,
heads = 8 ,
dim_head = 64 ,
spec_n_fft = 128 ,
spec_win_length = 24 ,
spec_aug_stretch_factor = 0.8
)
text_transformer = TextTransformer (
dim = 512 ,
depth = 6 ,
heads = 8 ,
dim_head = 64
)
mulan = MuLaN (
audio_transformer = audio_transformer ,
text_transformer = text_transformer
)
# get a ton of <sound, text> pairs and train
wavs = torch . randn ( 2 , 1024 )
texts = torch . randint ( 0 , 20000 , ( 2 , 256 ))
loss = mulan ( wavs , texts )
loss . backward ()
# after much training, you can embed sounds and text into a joint embedding space
# for conditioning the audio LM
embeds = mulan . get_audio_latents ( wavs ) # during training
embeds = mulan . get_text_latents ( texts ) # during inference要获得作为AudioLM一部分的三个变压器的条件嵌入,您必须使用MuLaNEmbedQuantizer ,如下所示
from musiclm_pytorch import MuLaNEmbedQuantizer
# setup the quantizer with the namespaced conditioning embeddings, unique per quantizer as well as namespace (per transformer)
quantizer = MuLaNEmbedQuantizer (
mulan = mulan , # pass in trained mulan from above
conditioning_dims = ( 1024 , 1024 , 1024 ), # say all three transformers have model dimensions of 1024
namespaces = ( 'semantic' , 'coarse' , 'fine' )
)
# now say you want the conditioning embeddings for semantic transformer
wavs = torch . randn ( 2 , 1024 )
conds = quantizer ( wavs = wavs , namespace = 'semantic' ) # (2, 8, 1024) - 8 is number of quantizers要训练(或微调)作为AudioLM一部分的三个变压器,您只需按照audiolm-pytorch上的说明进行训练,但将MulanEmbedQuantizer实例传递到关键字audio_conditioner下的训练类
前任。 SemanticTransformerTrainer
import torch
from audiolm_pytorch import HubertWithKmeans , SemanticTransformer , SemanticTransformerTrainer
wav2vec = HubertWithKmeans (
checkpoint_path = './hubert/hubert_base_ls960.pt' ,
kmeans_path = './hubert/hubert_base_ls960_L9_km500.bin'
)
semantic_transformer = SemanticTransformer (
num_semantic_tokens = wav2vec . codebook_size ,
dim = 1024 ,
depth = 6 ,
audio_text_condition = True # this must be set to True (same for CoarseTransformer and FineTransformers)
). cuda ()
trainer = SemanticTransformerTrainer (
transformer = semantic_transformer ,
wav2vec = wav2vec ,
audio_conditioner = quantizer , # pass in the MulanEmbedQuantizer instance above
folder = '/path/to/audio/files' ,
batch_size = 1 ,
data_max_length = 320 * 32 ,
num_train_steps = 1
)
trainer . train ()在对所有三个变压器(语义、粗略、精细)进行大量训练后,您将把经过微调或从头开始训练的AudioLM和MuLaN传递给MuLaNEmbedQuantizer中的MusicLM
# you need the trained AudioLM (audio_lm) from above
# with the MulanEmbedQuantizer (mulan_embed_quantizer)
from musiclm_pytorch import MusicLM
musiclm = MusicLM (
audio_lm = audio_lm , # `AudioLM` from https://github.com/lucidrains/audiolm-pytorch
mulan_embed_quantizer = quantizer # the `MuLaNEmbedQuantizer` from above
)
music = musiclm ( 'the crystalline sounds of the piano in a ballroom' , num_samples = 4 ) # sample 4 and pick the top match with mulan 木兰似乎正在使用解耦对比学习,将其作为一种选择
用 mulan 包装器包装 mulan 并量化输出,投影到 audiolm 维度
修改audiolm以接受条件嵌入,可以选择通过单独的投影处理不同的维度
audiolm 和 mulan 进入 musiclm 并使用 mulan 生成、过滤
为 AST 中的自注意力提供动态位置偏差
实现 MusicLM 生成多个样本并选择与 MuLaN 的最佳匹配
支持可变长度音频,并在音频转换器中进行掩蔽
添加花木兰版本打开剪辑
设置所有正确的频谱图超参数
@inproceedings { Agostinelli2023MusicLMGM ,
title = { MusicLM: Generating Music From Text } ,
author = { Andrea Agostinelli and Timo I. Denk and Zal{'a}n Borsos and Jesse Engel and Mauro Verzetti and Antoine Caillon and Qingqing Huang and Aren Jansen and Adam Roberts and Marco Tagliasacchi and Matthew Sharifi and Neil Zeghidour and C. Frank } ,
year = { 2023 }
} @article { Huang2022MuLanAJ ,
title = { MuLan: A Joint Embedding of Music Audio and Natural Language } ,
author = { Qingqing Huang and Aren Jansen and Joonseok Lee and Ravi Ganti and Judith Yue Li and Daniel P. W. Ellis } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2208.12415 }
} @misc { https://doi.org/10.48550/arxiv.2302.01327 ,
doi = { 10.48550/ARXIV.2302.01327 } ,
url = { https://arxiv.org/abs/2302.01327 } ,
author = { Kumar, Manoj and Dehghani, Mostafa and Houlsby, Neil } ,
title = { Dual PatchNorm } ,
publisher = { arXiv } ,
year = { 2023 } ,
copyright = { Creative Commons Attribution 4.0 International }
} @article { Liu2022PatchDropoutEV ,
title = { PatchDropout: Economizing Vision Transformers Using Patch Dropout } ,
author = { Yue Liu and Christos Matsoukas and Fredrik Strand and Hossein Azizpour and Kevin Smith } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2208.07220 }
} @misc { liu2021swin ,
title = { Swin Transformer V2: Scaling Up Capacity and Resolution } ,
author = { Ze Liu and Han Hu and Yutong Lin and Zhuliang Yao and Zhenda Xie and Yixuan Wei and Jia Ning and Yue Cao and Zheng Zhang and Li Dong and Furu Wei and Baining Guo } ,
year = { 2021 } ,
eprint = { 2111.09883 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { gilmer2023intriguing
title = { Intriguing Properties of Transformer Training Instabilities } ,
author = { Justin Gilmer, Andrea Schioppa, and Jeremy Cohen } ,
year = { 2023 } ,
status = { to be published - one attention stabilization technique is circulating within Google Brain, being used by multiple teams }
} @inproceedings { Shukor2022EfficientVP ,
title = { Efficient Vision-Language Pretraining with Visual Concepts and Hierarchical Alignment } ,
author = { Mustafa Shukor and Guillaume Couairon and Matthieu Cord } ,
booktitle = { British Machine Vision Conference } ,
year = { 2022 }
} @inproceedings { Zhai2023SigmoidLF ,
title = { Sigmoid Loss for Language Image Pre-Training } ,
author = { Xiaohua Zhai and Basil Mustafa and Alexander Kolesnikov and Lucas Beyer } ,
year = { 2023 }
}唯一的真理就是音乐。 ——杰克·凯鲁亚克
音乐是人类的通用语言。 ——亨利·沃兹沃斯·朗费罗


