Mega pytorch
0.1.0
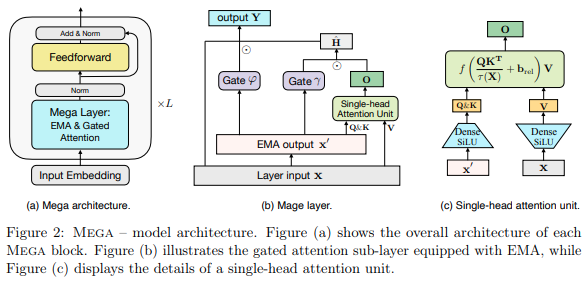
Mega 层的实现,单头注意力和多头 EMA 层存在于目前在 Long Range Arena 上保持 SOTA 的架构中,在 Pathfinder-X 上击败 S4 以及除音频之外的所有其他任务。
$ pip install mega-pytorchMega Layer 结合了注意力和学习的 EMA
import torch
from mega_pytorch import MegaLayer
layer = MegaLayer (
dim = 128 , # model dimensions
ema_heads = 16 , # number of EMA heads
attn_dim_qk = 64 , # dimension of queries / keys in attention
attn_dim_value = 256 , # dimension of values in attention
laplacian_attn_fn = False , # whether to use softmax (false) or laplacian attention activation fn (true)
)
x = torch . randn ( 1 , 1024 , 128 ) # (batch, seq, dim)
out = layer ( x ) # (1, 1024, 128)Full Mega(目前具有层规范)
import torch
from mega_pytorch import Mega
mega = Mega (
num_tokens = 256 , # number of tokens
dim = 128 , # model dimensions
depth = 6 , # depth
ema_heads = 16 , # number of EMA heads
attn_dim_qk = 64 , # dimension of queries / keys in attention
attn_dim_value = 256 , # dimensino of values in attention
laplacian_attn_fn = True , # whether to use softmax (false) or laplacian attention activation fn (true)
)
x = torch . randint ( 0 , 256 , ( 1 , 1024 ))
logits = mega ( x ) # (1, 1024, 256) @inproceedings { Ma2022MegaMA ,
title = { Mega: Moving Average Equipped Gated Attention } ,
author = { Xuezhe Ma and Chunting Zhou and Xiang Kong and Junxian He and Liangke Gui and Graham Neubig and Jonathan May and Luke Zettlemoyer } ,
year = { 2022 }
}

