LaMDA rlhf pytorch
v0.0.2
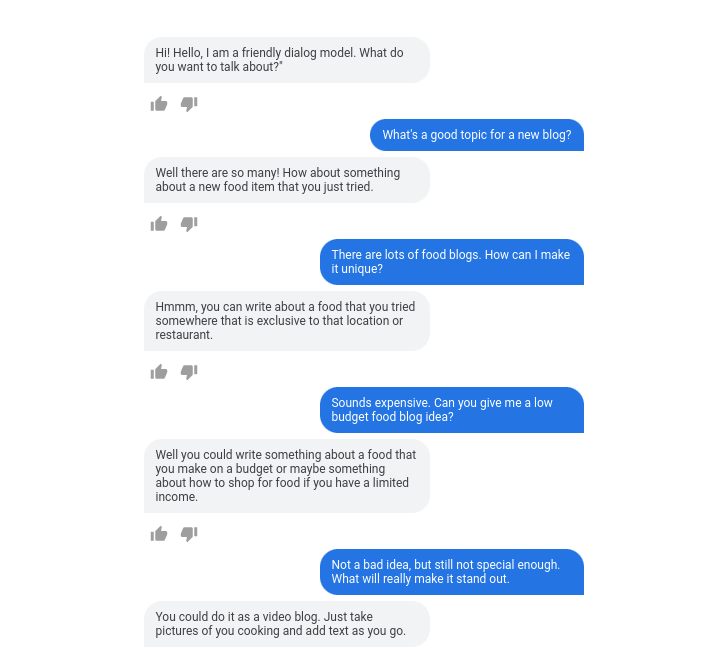
Google LaMDA 研究论文在 PyTorch 中的开源预训练实现。完全没有知觉的人工智能。该存储库将涵盖预训练架构的 2B 参数实现,因为这可能是大多数人能够负担得起的训练费用。您可以在此处查看 Google 2022 年的最新博文,其中详细介绍了 LaMDA。您还可以在此处查看他们 2021 年之前关于该模型的博客文章。
Phil 'Lucid' Wang 博士的工作给我很大的启发。请查看他对多种不同 Transformer 架构的开源实现并支持他的工作。
开发者更新可以在以下位置找到:
lamda_base = LaMDA (
num_tokens = 20000 ,
dim = 512 ,
dim_head = 64 ,
depth = 12 ,
heads = 8
)
lamda = AutoregressiveWrapper ( lamda_base , max_seq_len = 512 )
tokens = torch . randint ( 0 , 20000 , ( 1 , 512 )) # mock token data
logits = lamda ( tokens )
print ( logits ) @article { DBLP:journals/corr/abs-2201-08239 ,
author = { Romal Thoppilan and
Daniel De Freitas and
Jamie Hall and
Noam Shazeer and
Apoorv Kulshreshtha and
Heng{-}Tze Cheng and
Alicia Jin and
Taylor Bos and
Leslie Baker and
Yu Du and
YaGuang Li and
Hongrae Lee and
Huaixiu Steven Zheng and
Amin Ghafouri and
Marcelo Menegali and
Yanping Huang and
Maxim Krikun and
Dmitry Lepikhin and
James Qin and
Dehao Chen and
Yuanzhong Xu and
Zhifeng Chen and
Adam Roberts and
Maarten Bosma and
Yanqi Zhou and
Chung{-}Ching Chang and
Igor Krivokon and
Will Rusch and
Marc Pickett and
Kathleen S. Meier{-}Hellstern and
Meredith Ringel Morris and
Tulsee Doshi and
Renelito Delos Santos and
Toju Duke and
Johnny Soraker and
Ben Zevenbergen and
Vinodkumar Prabhakaran and
Mark Diaz and
Ben Hutchinson and
Kristen Olson and
Alejandra Molina and
Erin Hoffman{-}John and
Josh Lee and
Lora Aroyo and
Ravi Rajakumar and
Alena Butryna and
Matthew Lamm and
Viktoriya Kuzmina and
Joe Fenton and
Aaron Cohen and
Rachel Bernstein and
Ray Kurzweil and
Blaise Aguera{-}Arcas and
Claire Cui and
Marian Croak and
Ed H. Chi and
Quoc Le } ,
title = { LaMDA: Language Models for Dialog Applications } ,
journal = { CoRR } ,
volume = { abs/2201.08239 } ,
year = { 2022 } ,
url = { https://arxiv.org/abs/2201.08239 } ,
eprinttype = { arXiv } ,
eprint = { 2201.08239 } ,
timestamp = { Fri, 22 Apr 2022 16:06:31 +0200 } ,
biburl = { https://dblp.org/rec/journals/corr/abs-2201-08239.bib } ,
bibsource = { dblp computer science bibliography, https://dblp.org }
} @misc { https://doi.org/10.48550/arxiv.1706.03762 ,
doi = { 10.48550/ARXIV.1706.03762 } ,
url = { https://arxiv.org/abs/1706.03762 } ,
author = { Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N. and Kaiser, Lukasz and Polosukhin, Illia } ,
keywords = { Computation and Language (cs.CL), Machine Learning (cs.LG), FOS: Computer and information sciences, FOS: Computer and information sciences } ,
title = { Attention Is All You Need } ,
publisher = { arXiv } ,
year = { 2017 } ,
copyright = { arXiv.org perpetual, non-exclusive license }
} @misc { https://doi.org/10.48550/arxiv.1910.10683 ,
doi = { 10.48550/ARXIV.1910.10683 } ,
url = { https://arxiv.org/abs/1910.10683 } ,
author = { Raffel, Colin and Shazeer, Noam and Roberts, Adam and Lee, Katherine and Narang, Sharan and Matena, Michael and Zhou, Yanqi and Li, Wei and Liu, Peter J. } ,
keywords = { Machine Learning (cs.LG), Computation and Language (cs.CL), Machine Learning (stat.ML), FOS: Computer and information sciences, FOS: Computer and information sciences } ,
title = { Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer } ,
publisher = { arXiv } ,
year = { 2019 } ,
copyright = { arXiv.org perpetual, non-exclusive license }
} @misc { https://doi.org/10.48550/arxiv.2002.05202 ,
doi = { 10.48550/ARXIV.2002.05202 } ,
url = { https://arxiv.org/abs/2002.05202 } ,
author = { Shazeer, Noam } ,
keywords = { Machine Learning (cs.LG), Neural and Evolutionary Computing (cs.NE), Machine Learning (stat.ML), FOS: Computer and information sciences, FOS: Computer and information sciences } ,
title = { GLU Variants Improve Transformer } ,
publisher = { arXiv } ,
year = { 2020 } ,
copyright = { arXiv.org perpetual, non-exclusive license }
} @article { DBLP:journals/corr/abs-2101-00027 ,
author = { Leo Gao and
Stella Biderman and
Sid Black and
Laurence Golding and
Travis Hoppe and
Charles Foster and
Jason Phang and
Horace He and
Anish Thite and
Noa Nabeshima and
Shawn Presser and
Connor Leahy } ,
title = { The Pile: An 800GB Dataset of Diverse Text for Language Modeling } ,
journal = { CoRR } ,
volume = { abs/2101.00027 } ,
year = { 2021 } ,
url = { https://arxiv.org/abs/2101.00027 } ,
eprinttype = { arXiv } ,
eprint = { 2101.00027 } ,
timestamp = { Thu, 14 Oct 2021 09:16:12 +0200 } ,
biburl = { https://dblp.org/rec/journals/corr/abs-2101-00027.bib } ,
bibsource = { dblp computer science bibliography, https://dblp.org }
} @article { DBLP:journals/corr/abs-1808-06226 ,
author = { Taku Kudo and
John Richardson } ,
title = { SentencePiece: {A} simple and language independent subword tokenizer
and detokenizer for Neural Text Processing } ,
journal = { CoRR } ,
volume = { abs/1808.06226 } ,
year = { 2018 } ,
url = { http://arxiv.org/abs/1808.06226 } ,
eprinttype = { arXiv } ,
eprint = { 1808.06226 } ,
timestamp = { Sun, 02 Sep 2018 15:01:56 +0200 } ,
biburl = { https://dblp.org/rec/journals/corr/abs-1808-06226.bib } ,
bibsource = { dblp computer science bibliography, https://dblp.org }
} @inproceedings { sennrich-etal-2016-neural ,
title = " Neural Machine Translation of Rare Words with Subword Units " ,
author = " Sennrich, Rico and
Haddow, Barry and
Birch, Alexandra " ,
booktitle = " Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) " ,
month = aug,
year = " 2016 " ,
address = " Berlin, Germany " ,
publisher = " Association for Computational Linguistics " ,
url = " https://aclanthology.org/P16-1162 " ,
doi = " 10.18653/v1/P16-1162 " ,
pages = " 1715--1725 " ,
}

