soundstorm pytorch
0.5.0
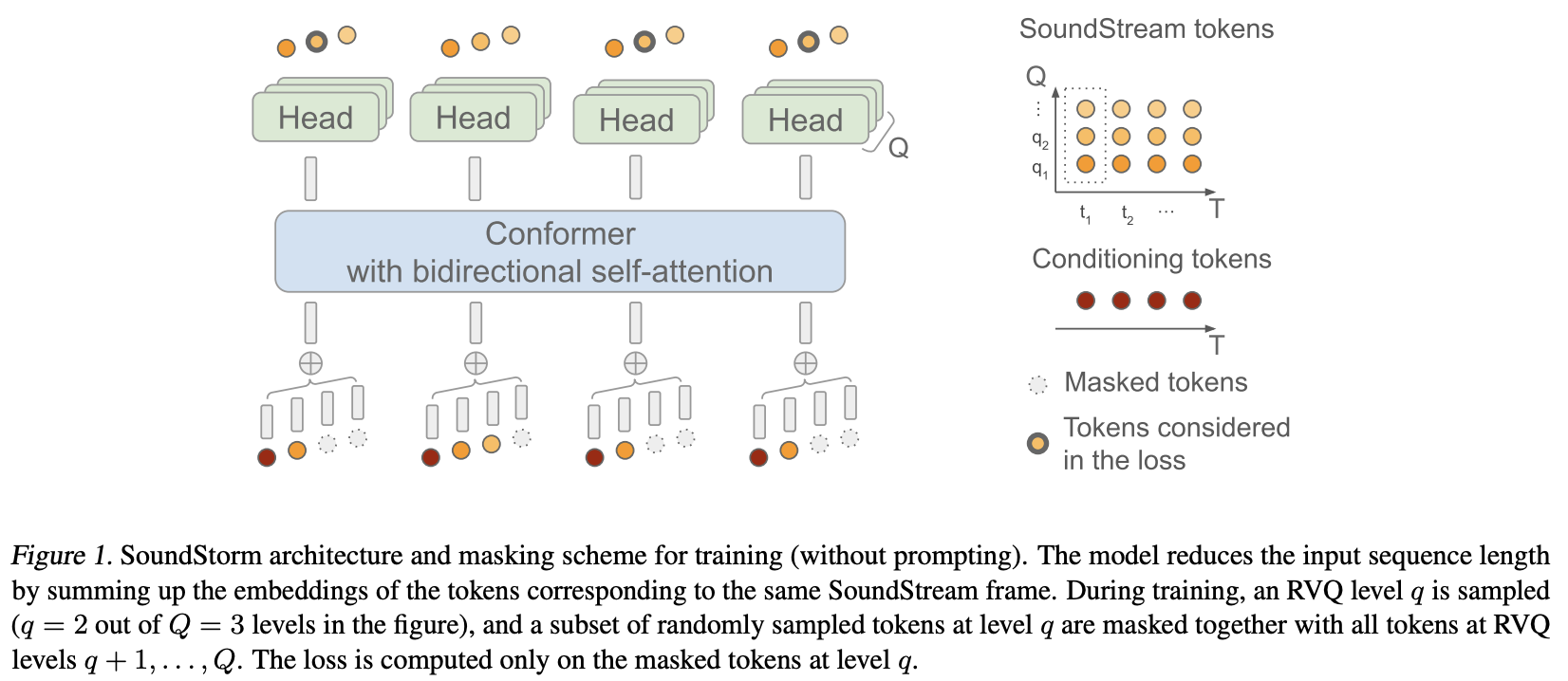
在 Pytorch 中实现 SoundStorm(来自 Google Deepmind 的高效并行音频生成)。
他们基本上将 MaskGiT 应用于来自 Soundstream 的残差矢量量化代码。他们选择使用的变压器架构非常适合音频领域,名为 Conformer
项目页面
稳定性和? Huggingface 慷慨赞助尖端人工智能研究并开源
Lucas Newman 做出了众多贡献,包括初始训练代码、声音提示逻辑、每级量化器解码!
?加速提供简单而强大的培训解决方案
Einops 提供不可或缺的抽象,使构建神经网络变得有趣、简单且令人振奋
Steven Hillis 提交了正确的屏蔽策略并验证了存储库是否有效!
Lucas Newman 使用跨多个存储库的模型对一个小型工作 Soundstorm 进行了基本训练,展示了它的端到端工作原理。模型包括 SoundStream、文本到语义 T5,最后是 SoundStorm 转换器。
@Jiang-Stan,发现了迭代解密中的一个关键错误!
$ pip install soundstorm-pytorch import torch
from soundstorm_pytorch import SoundStorm , ConformerWrapper
conformer = ConformerWrapper (
codebook_size = 1024 ,
num_quantizers = 12 ,
conformer = dict (
dim = 512 ,
depth = 2
),
)
model = SoundStorm (
conformer ,
steps = 18 , # 18 steps, as in original maskgit paper
schedule = 'cosine' # currently the best schedule is cosine
)
# get your pre-encoded codebook ids from the soundstream from a lot of raw audio
codes = torch . randint ( 0 , 1024 , ( 2 , 1024 , 12 )) # (batch, seq, num residual VQ)
# do the below in a loop for a ton of data
loss , _ = model ( codes )
loss . backward ()
# model can now generate in 18 steps. ~2 seconds sounds reasonable
generated = model . generate ( 1024 , batch_size = 2 ) # (2, 1024)要直接训练原始音频,您需要将预训练的SoundStream传递到SoundStorm中。您可以在 audiolm-pytorch 上训练您自己的SoundStream 。
import torch
from soundstorm_pytorch import SoundStorm , ConformerWrapper , Conformer , SoundStream
conformer = ConformerWrapper (
codebook_size = 1024 ,
num_quantizers = 12 ,
conformer = dict (
dim = 512 ,
depth = 2
),
)
soundstream = SoundStream (
codebook_size = 1024 ,
rq_num_quantizers = 12 ,
attn_window_size = 128 ,
attn_depth = 2
)
model = SoundStorm (
conformer ,
soundstream = soundstream # pass in the soundstream
)
# find as much audio you'd like the model to learn
audio = torch . randn ( 2 , 10080 )
# course it through the model and take a gazillion tiny steps
loss , _ = model ( audio )
loss . backward ()
# and now you can generate state-of-the-art speech
generated_audio = model . generate ( seconds = 30 , batch_size = 2 ) # generate 30 seconds of audio (it will calculate the length in seconds based off the sampling frequency and cumulative downsamples in the soundstream passed in above)完整的文本到语音将依赖于经过训练的TextToSemantic编码器/解码器转换器。然后,您将加载权重并将其作为spear_tts_text_to_semantic传递到SoundStorm
这是一项正在进行的工作,因为spear-tts-pytorch仅具有完整的模型架构,而不是预训练 + 伪标签 + 反向翻译逻辑。
from spear_tts_pytorch import TextToSemantic
text_to_semantic = TextToSemantic (
dim = 512 ,
source_depth = 12 ,
target_depth = 12 ,
num_text_token_ids = 50000 ,
num_semantic_token_ids = 20000 ,
use_openai_tokenizer = True
)
# load the trained text-to-semantic transformer
text_to_semantic . load ( '/path/to/trained/model.pt' )
# pass it into the soundstorm
model = SoundStorm (
conformer ,
soundstream = soundstream ,
spear_tts_text_to_semantic = text_to_semantic
). cuda ()
# and now you can generate state-of-the-art speech
generated_speech = model . generate (
texts = [
'the rain in spain stays mainly in the plain' ,
'the quick brown fox jumps over the lazy dog'
]
) # (2, n) - raw waveform decoded from soundstream 整合声流
生成时,长度可以以秒为单位定义(考虑采样频率等)
确保支持分组 rvq。连接嵌入而不是跨组维度求和
只需复制构象异构体并使用旋转嵌入重做肖氏的相对位置嵌入即可。没有人再用shaw了。
默认flash注意true
删除batchnorm,只使用layernorm,但是在swish之后(如normformer论文中所示)
带加速功能的训练器 - 感谢@lucasnewman
通过forward传递mask并generate ,允许可变长度序列训练和生成
生成时返回音频文件列表的选项
将其变成命令行工具
添加交叉注意和自适应层范数调节
@misc { borsos2023soundstorm ,
title = { SoundStorm: Efficient Parallel Audio Generation } ,
author = { Zalán Borsos and Matt Sharifi and Damien Vincent and Eugene Kharitonov and Neil Zeghidour and Marco Tagliasacchi } ,
year = { 2023 } ,
eprint = { 2305.09636 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.SD }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @article { Chang2022MaskGITMG ,
title = { MaskGIT: Masked Generative Image Transformer } ,
author = { Huiwen Chang and Han Zhang and Lu Jiang and Ce Liu and William T. Freeman } ,
journal = { 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2022 } ,
pages = { 11305-11315 }
} @article { Lezama2022ImprovedMI ,
title = { Improved Masked Image Generation with Token-Critic } ,
author = { Jos{'e} Lezama and Huiwen Chang and Lu Jiang and Irfan Essa } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2209.04439 }
} @inproceedings { Nijkamp2021SCRIPTSP ,
title = { SCRIPT: Self-Critic PreTraining of Transformers } ,
author = { Erik Nijkamp and Bo Pang and Ying Nian Wu and Caiming Xiong } ,
booktitle = { North American Chapter of the Association for Computational Linguistics } ,
year = { 2021 }
} @inproceedings { rogozhnikov2022einops ,
title = { Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation } ,
author = { Alex Rogozhnikov } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=oapKSVM2bcj }
} @misc { su2021roformer ,
title = { RoFormer: Enhanced Transformer with Rotary Position Embedding } ,
author = { Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu } ,
year = { 2021 } ,
eprint = { 2104.09864 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @inproceedings { Zhou2024ValueRL ,
title = { Value Residual Learning For Alleviating Attention Concentration In Transformers } ,
author = { Zhanchao Zhou and Tianyi Wu and Zhiyun Jiang and Zhenzhong Lan } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273532030 }
}

