rotary embedding torch
0.8.6
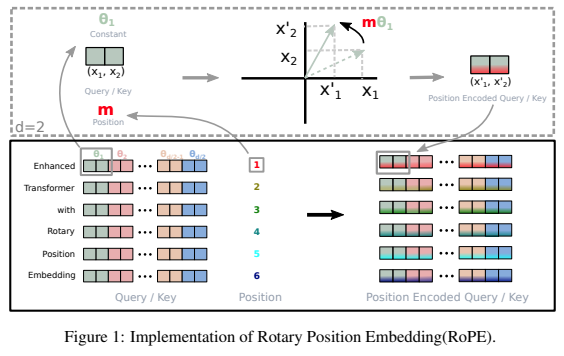
继相对位置编码的成功之后,一个独立的库,用于在 Pytorch 中向 Transformer 添加旋转嵌入。具体来说,它将使信息轻松高效地旋转到张量的任何轴,无论它们是固定位置的还是学习的。该库将以很少的成本为您提供最先进的位置嵌入结果。
我的直觉还告诉我,旋转还有更多可以在人工神经网络中利用的东西。
$ pip install rotary-embedding-torch import torch
from rotary_embedding_torch import RotaryEmbedding
# instantiate the positional embedding in your transformer and pass to all your attention layers
rotary_emb = RotaryEmbedding ( dim = 32 )
# mock queries and keys - dimensions should end with (seq_len, feature dimension), and any number of preceding dimensions (batch, heads, etc)
q = torch . randn ( 1 , 8 , 1024 , 64 ) # queries - (batch, heads, seq len, dimension of head)
k = torch . randn ( 1 , 8 , 1024 , 64 ) # keys
# apply the rotations to your queries and keys after the heads have been split out, but prior to the dot product and subsequent softmax (attention)
q = rotary_emb . rotate_queries_or_keys ( q )
k = rotary_emb . rotate_queries_or_keys ( k )
# then do your attention with your queries (q) and keys (k) as usual如果您正确执行上述所有步骤,您应该会在训练过程中看到显着的进步
在推理时处理键/值缓存时,查询位置需要偏移key_value_seq_length - query_seq_length
为了简化此操作,请使用rotate_queries_with_cached_keys方法
q = torch . randn ( 1 , 8 , 1 , 64 ) # only one query at a time
k = torch . randn ( 1 , 8 , 1024 , 64 ) # key / values with cache concatted
q , k = rotary_emb . rotate_queries_with_cached_keys ( q , k )您也可以像这样手动执行此操作
q = rotary_emb . rotate_queries_or_keys ( q , offset = k . shape [ - 2 ] - q . shape [ - 2 ])为了方便使用n维轴向相对位置嵌入,即。视频变压器
import torch
from rotary_embedding_torch import (
RotaryEmbedding ,
apply_rotary_emb
)
pos_emb = RotaryEmbedding (
dim = 16 ,
freqs_for = 'pixel' ,
max_freq = 256
)
# queries and keys for frequencies to be rotated into
# say for a video with 8 frames, and rectangular image (feature dimension comes last)
q = torch . randn ( 1 , 8 , 64 , 32 , 64 )
k = torch . randn ( 1 , 8 , 64 , 32 , 64 )
# get axial frequencies - (8, 64, 32, 16 * 3 = 48)
# will automatically do partial rotary
freqs = pos_emb . get_axial_freqs ( 8 , 64 , 32 )
# rotate in frequencies
q = apply_rotary_emb ( freqs , q )
k = apply_rotary_emb ( freqs , k )在本文中,他们通过提供类似于 ALiBi 的衰减来解决旋转嵌入的长度外推问题。他们将这种技术命名为 XPos,您可以通过在初始化时设置use_xpos = True来使用它。
这只能用于自回归变压器
import torch
from rotary_embedding_torch import RotaryEmbedding
# instantiate the positional embedding in your transformer and pass to all your attention layers
rotary_emb = RotaryEmbedding (
dim = 32 ,
use_xpos = True # set this to True to make rotary embeddings extrapolate better to sequence lengths greater than the one used at training time
)
# mock queries and keys - dimensions should end with (seq_len, feature dimension), and any number of preceding dimensions (batch, heads, etc)
q = torch . randn ( 1 , 8 , 1024 , 64 ) # queries - (batch, heads, seq len, dimension of head)
k = torch . randn ( 1 , 8 , 1024 , 64 ) # keys
# apply the rotations to your queries and keys after the heads have been split out, but prior to the dot product and subsequent softmax (attention)
# instead of using `rotate_queries_or_keys`, you will use `rotate_queries_and_keys`, the rest is taken care of
q , k = rotary_emb . rotate_queries_and_keys ( q , k )这篇 MetaAI 论文提出简单地对序列位置的插值进行微调,以将预训练模型扩展到更长的上下文长度。他们表明,这比简单地在相同序列位置上进行微调但进一步扩展的效果要好得多。
您可以通过将初始化时的interpolate_factor设置为大于1.值来使用此功能。(例如,如果预训练模型是在 2048 上训练的,则设置interpolate_factor = 2.将允许微调到2048 x 2. = 4096 )
更新:社区中有人报告说它效果不佳。如果您看到阳性或阴性结果,请给我发电子邮件
import torch
from rotary_embedding_torch import RotaryEmbedding
rotary_emb = RotaryEmbedding (
dim = 32 ,
interpolate_factor = 2. # add this line of code to pretrained model and fine-tune for ~1000 steps, as shown in paper
) @misc { su2021roformer ,
title = { RoFormer: Enhanced Transformer with Rotary Position Embedding } ,
author = { Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu } ,
year = { 2021 } ,
eprint = { 2104.09864 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @inproceedings { Sun2022ALT ,
title = { A Length-Extrapolatable Transformer } ,
author = { Yutao Sun and Li Dong and Barun Patra and Shuming Ma and Shaohan Huang and Alon Benhaim and Vishrav Chaudhary and Xia Song and Furu Wei } ,
year = { 2022 }
} @inproceedings { Chen2023ExtendingCW ,
title = { Extending Context Window of Large Language Models via Positional Interpolation } ,
author = { Shouyuan Chen and Sherman Wong and Liangjian Chen and Yuandong Tian } ,
year = { 2023 }
} @misc { bloc97-2023
title = { NTK-Aware Scaled RoPE allows LLaMA models to have extended (8k+) context size without any fine-tuning and minimal perplexity degradation. } ,
author = { /u/bloc97 } ,
url = { https://www.reddit.com/r/LocalLLaMA/comments/14lz7j5/ntkaware_scaled_rope_allows_llama_models_to_have/ }
}

