yoloface
1.0.0
YOLOv3(You Only Look Once)是一种最先进的实时目标检测算法。发布的模型可识别图像和视频中的 80 种不同物体。欲了解更多详细信息,您可以参考这篇论文。
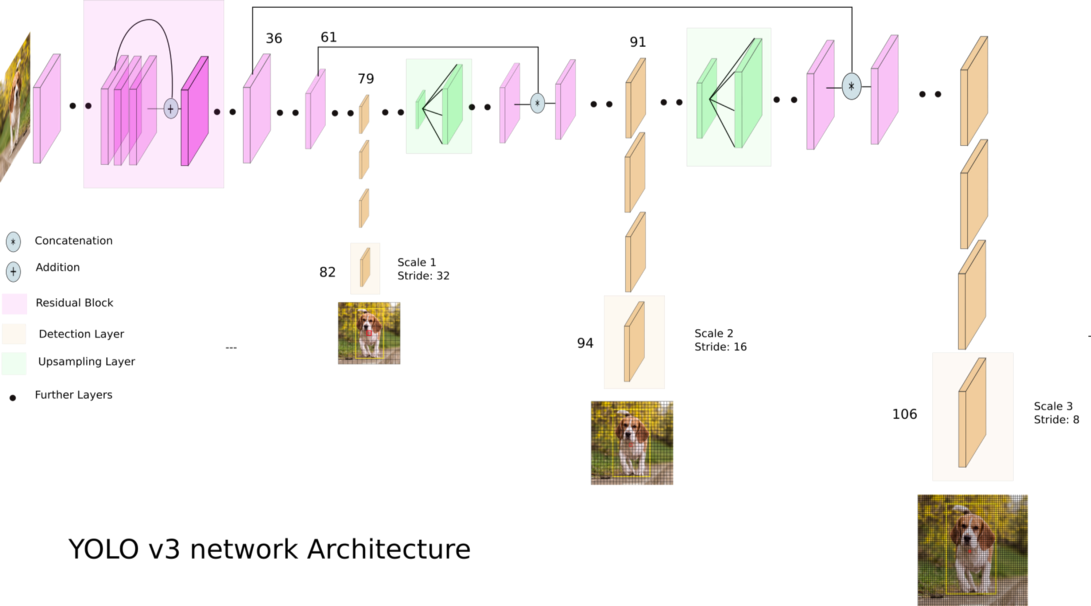
图片来源:Ayoosh Kathuria
OpenCV dnn模块支持对来自 TensorFlow、Torch、Darknet 和 Caffe 等流行框架的预训练深度学习模型运行推理。
该项目的开发将在Python虚拟环境中隔离。这使我们能够尝试不同版本的依赖项。
安装virtual environment (virtualenv)的方法有很多种,请参阅 Python 虚拟环境:适用于不同平台的入门指南,但这里有几种:
$ pip install virtualenv$ pip install --upgrade virtualenv为此项目创建Python 3.6虚拟环境并激活virtualenv:
$ virtualenv -p python3.6 yoloface
$ source ./yoloface/bin/activate接下来,安装该项目的依赖项:
$ pip install -r requirements.txt$ git clone https://github.com/sthanhng/yoloface对于人脸检测,您应该从此链接下载在 WIDER FACE:人脸检测基准数据集上训练的预训练 YOLOv3 权重文件,并将其放置在model-weights/目录中。
运行以下命令:
图像输入
$ python yoloface.py --image samples/outside_000001.jpg --output-dir outputs/视频输入
$ python yoloface.py --video samples/subway.mp4 --output-dir outputs/摄像头
$ python yoloface.py --src 1 --output-dir outputs/
该项目已获得 MIT 许可证 - 请参阅 LICENSE.md 文件以了解更多详细信息。


