FLASH pytorch
0.1.9
线性时间内变压器质量论文中提出的变压器变体的实现
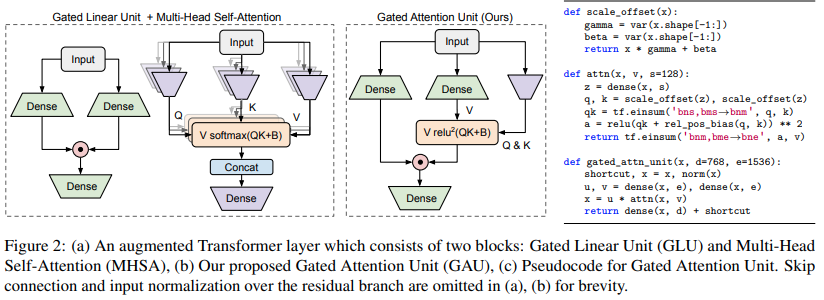
$ pip install FLASH-pytorch本文的主要新颖电路是“门控注意力单元”,他们声称它可以取代多头注意力,同时将其减少到只有一个头。
它使用 relu 平方激活代替了 softmax,其激活首次出现在 Primer 论文中,并且在 ReLA Transformer 中使用了 ReLU。门控风格似乎主要受到 gMLP 的启发。
import torch
from flash_pytorch import GAU
gau = GAU (
dim = 512 ,
query_key_dim = 128 , # query / key dimension
causal = True , # autoregressive or not
expansion_factor = 2 , # hidden dimension = dim * expansion_factor
laplace_attn_fn = True # new Mega paper claims this is more stable than relu squared as attention function
)
x = torch . randn ( 1 , 1024 , 512 )
out = gau ( x ) # (1, 1024, 512)然后,作者将GAU与 Katharopoulos 线性注意力相结合,使用序列分组来克服自回归线性注意力的已知问题。
这种二次门控注意力单元与分组线性注意力的组合被他们命名为 FLASH
你也可以很容易地使用它
import torch
from flash_pytorch import FLASH
flash = FLASH (
dim = 512 ,
group_size = 256 , # group size
causal = True , # autoregressive or not
query_key_dim = 128 , # query / key dimension
expansion_factor = 2. , # hidden dimension = dim * expansion_factor
laplace_attn_fn = True # new Mega paper claims this is more stable than relu squared as attention function
)
x = torch . randn ( 1 , 1111 , 512 ) # sequence will be auto-padded to nearest group size
out = flash ( x ) # (1, 1111, 512)最后,您可以使用本文中提到的完整 FLASH 变压器。这包含论文中提到的所有位置嵌入。绝对位置嵌入使用缩放正弦曲线。 GAU 二次注意力会得到单向 T5 相对位置偏差。最重要的是,GAU 注意力和线性注意力都将被旋转嵌入(RoPE)。
import torch
from flash_pytorch import FLASHTransformer
model = FLASHTransformer (
num_tokens = 20000 , # number of tokens
dim = 512 , # model dimension
depth = 12 , # depth
causal = True , # autoregressive or not
group_size = 256 , # size of the groups
query_key_dim = 128 , # dimension of queries / keys
expansion_factor = 2. , # hidden dimension = dim * expansion_factor
norm_type = 'scalenorm' , # in the paper, they claimed scalenorm led to faster training at no performance hit. the other option is 'layernorm' (also default)
shift_tokens = True # discovered by an independent researcher in Shenzhen @BlinkDL, this simply shifts half of the feature space forward one step along the sequence dimension - greatly improved convergence even more in my local experiments
)
x = torch . randint ( 0 , 20000 , ( 1 , 1024 ))
logits = model ( x ) # (1, 1024, 20000) $ python train.py @article { Hua2022TransformerQI ,
title = { Transformer Quality in Linear Time } ,
author = { Weizhe Hua and Zihang Dai and Hanxiao Liu and Quoc V. Le } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2202.10447 }
} @software { peng_bo_2021_5196578 ,
author = { PENG Bo } ,
title = { BlinkDL/RWKV-LM: 0.01 } ,
month = { aug } ,
year = { 2021 } ,
publisher = { Zenodo } ,
version = { 0.01 } ,
doi = { 10.5281/zenodo.5196578 } ,
url = { https://doi.org/10.5281/zenodo.5196578 }
} @inproceedings { Ma2022MegaMA ,
title = { Mega: Moving Average Equipped Gated Attention } ,
author = { Xuezhe Ma and Chunting Zhou and Xiang Kong and Junxian He and Liangke Gui and Graham Neubig and Jonathan May and Luke Zettlemoyer } ,
year = { 2022 }
}

