pi zero pytorch
0.1.5
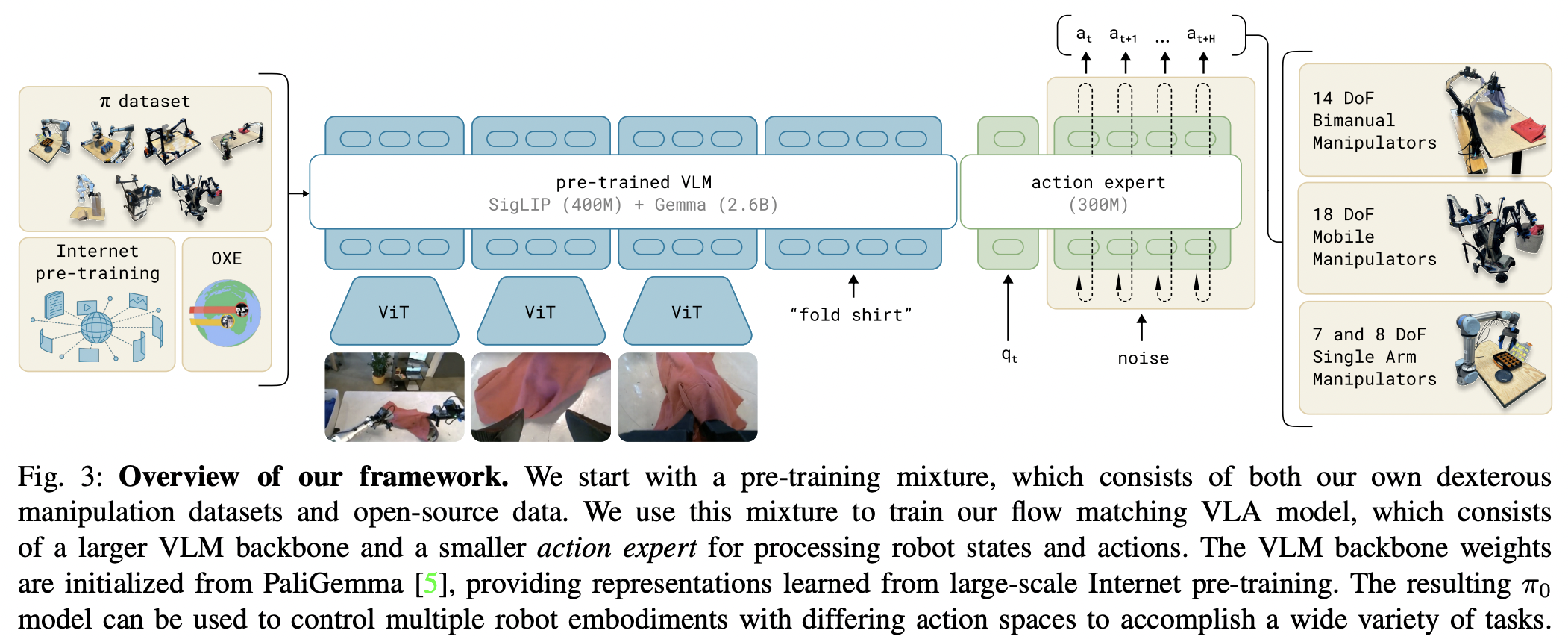
物理智能提出的机器人基础模型架构π₀的实现
这项工作的总结是,它是一个简化的 Transfusion(Zhou 等人),受到 Stable Diffusion 3(Esser 等人)的影响,主要是采用流匹配而不是扩散来生成策略,以及分离参数(来自 mmDIT 的联合注意力)。它们建立在预训练的视觉语言模型 PaliGemma 2B 之上。
Einops 用于令人惊叹的打包和解包,在这里广泛用于管理各种令牌集
Flex Attention 可轻松混合自回归和双向注意力
@Wonder1905 用于代码审查和识别问题
你?也许是一名博士生想要为行为克隆的最新 SOTA 架构做出贡献?
$ pip install pi-zero-pytorch import torch
from pi_zero_pytorch import π0
model = π0 (
dim = 512 ,
dim_action_input = 6 ,
dim_joint_state = 12 ,
num_tokens = 20_000
)
vision = torch . randn ( 1 , 1024 , 512 )
commands = torch . randint ( 0 , 20_000 , ( 1 , 1024 ))
joint_state = torch . randn ( 1 , 12 )
actions = torch . randn ( 1 , 32 , 6 )
loss , _ = model ( vision , commands , joint_state , actions )
loss . backward ()
# after much training
sampled_actions = model ( vision , commands , joint_state , trajectory_length = 32 ) # (1, 32, 6)在项目根目录下,运行
$ pip install ' .[test] ' # or `uv pip install '.[test]'`然后将测试添加到tests/test_pi_zero.py并运行
$ pytest tests/就是这样
@misc { Black2024 ,
author = { Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, Ury Zhilinsky } ,
url = { https://www.physicalintelligence.company/download/pi0.pdf }
} @inproceedings { Zhou2024ValueRL ,
title = { Value Residual Learning For Alleviating Attention Concentration In Transformers } ,
author = { Zhanchao Zhou and Tianyi Wu and Zhiyun Jiang and Zhenzhong Lan } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273532030 }
} @inproceedings { Darcet2023VisionTN ,
title = { Vision Transformers Need Registers } ,
author = { Timoth'ee Darcet and Maxime Oquab and Julien Mairal and Piotr Bojanowski } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:263134283 }
} @article { Li2024ImmiscibleDA ,
title = { Immiscible Diffusion: Accelerating Diffusion Training with Noise Assignment } ,
author = { Yiheng Li and Heyang Jiang and Akio Kodaira and Masayoshi Tomizuka and Kurt Keutzer and Chenfeng Xu } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2406.12303 } ,
url = { https://api.semanticscholar.org/CorpusID:270562607 }
} @inproceedings { Sadat2024EliminatingOA ,
title = { Eliminating Oversaturation and Artifacts of High Guidance Scales in Diffusion Models } ,
author = { Seyedmorteza Sadat and Otmar Hilliges and Romann M. Weber } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273098845 }
} @article { Bulatov2022RecurrentMT ,
title = { Recurrent Memory Transformer } ,
author = { Aydar Bulatov and Yuri Kuratov and Mikhail S. Burtsev } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2207.06881 } ,
url = { https://api.semanticscholar.org/CorpusID:250526424 }
} @inproceedings { Bessonov2023RecurrentAT ,
title = { Recurrent Action Transformer with Memory } ,
author = { A. B. Bessonov and Alexey Staroverov and Huzhenyu Zhang and Alexey K. Kovalev and D. Yudin and Aleksandr I. Panov } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:259188030 }
} @article { Zhu2024HyperConnections ,
title = { Hyper-Connections } ,
author = { Defa Zhu and Hongzhi Huang and Zihao Huang and Yutao Zeng and Yunyao Mao and Banggu Wu and Qiyang Min and Xun Zhou } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2409.19606 } ,
url = { https://api.semanticscholar.org/CorpusID:272987528 }
}亲爱的爱丽丝


