electra pytorch
0.1.2
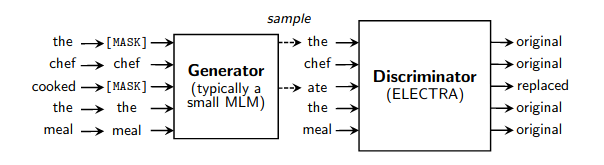
一个简单的工作包装器,用于快速预训练语言模型,如本文所述。它可以将训练速度提高 4 倍(与正常的掩码语言建模相比),如果训练时间更长,最终会达到更好的性能。特别感谢 Erik Nijkamp 花时间复制 GLUE 的结果。
$ pip install electra-pytorch以下示例使用reformer-pytorch ,可以通过 pip 安装。
import torch
from torch import nn
from reformer_pytorch import ReformerLM
from electra_pytorch import Electra
# (1) instantiate the generator and discriminator, making sure that the generator is roughly a quarter to a half of the size of the discriminator
generator = ReformerLM (
num_tokens = 20000 ,
emb_dim = 128 ,
dim = 256 , # smaller hidden dimension
heads = 4 , # less heads
ff_mult = 2 , # smaller feed forward intermediate dimension
dim_head = 64 ,
depth = 12 ,
max_seq_len = 1024
)
discriminator = ReformerLM (
num_tokens = 20000 ,
emb_dim = 128 ,
dim = 1024 ,
dim_head = 64 ,
heads = 16 ,
depth = 12 ,
ff_mult = 4 ,
max_seq_len = 1024
)
# (2) weight tie the token and positional embeddings of generator and discriminator
generator . token_emb = discriminator . token_emb
generator . pos_emb = discriminator . pos_emb
# weight tie any other embeddings if available, token type embeddings, etc.
# (3) instantiate electra
trainer = Electra (
generator ,
discriminator ,
discr_dim = 1024 , # the embedding dimension of the discriminator
discr_layer = 'reformer' , # the layer name in the discriminator, whose output would be used for predicting token is still the same or replaced
mask_token_id = 2 , # the token id reserved for masking
pad_token_id = 0 , # the token id for padding
mask_prob = 0.15 , # masking probability for masked language modeling
mask_ignore_token_ids = [] # ids of tokens to ignore for mask modeling ex. (cls, sep)
)
# (4) train
data = torch . randint ( 0 , 20000 , ( 1 , 1024 ))
results = trainer ( data )
results . loss . backward ()
# after much training, the discriminator should have improved
torch . save ( discriminator , f'./pretrained-model.pt' )如果您不想让框架自动神奇地拦截鉴别器的隐藏输出,您可以通过以下方式自行传入鉴别器(带有额外的线性 [dim x 1])。
import torch
from torch import nn
from reformer_pytorch import ReformerLM
from electra_pytorch import Electra
# (1) instantiate the generator and discriminator, making sure that the generator is roughly a quarter to a half of the size of the discriminator
generator = ReformerLM (
num_tokens = 20000 ,
emb_dim = 128 ,
dim = 256 , # smaller hidden dimension
heads = 4 , # less heads
ff_mult = 2 , # smaller feed forward intermediate dimension
dim_head = 64 ,
depth = 12 ,
max_seq_len = 1024
)
discriminator = ReformerLM (
num_tokens = 20000 ,
emb_dim = 128 ,
dim = 1024 ,
dim_head = 64 ,
heads = 16 ,
depth = 12 ,
ff_mult = 4 ,
max_seq_len = 1024 ,
return_embeddings = True
)
# (2) weight tie the token and positional embeddings of generator and discriminator
generator . token_emb = discriminator . token_emb
generator . pos_emb = discriminator . pos_emb
# weight tie any other embeddings if available, token type embeddings, etc.
# (3) instantiate electra
discriminator_with_adapter = nn . Sequential ( discriminator , nn . Linear ( 1024 , 1 ))
trainer = Electra (
generator ,
discriminator_with_adapter ,
mask_token_id = 2 , # the token id reserved for masking
pad_token_id = 0 , # the token id for padding
mask_prob = 0.15 , # masking probability for masked language modeling
mask_ignore_token_ids = [] # ids of tokens to ignore for mask modeling ex. (cls, sep)
)
# (4) train
data = torch . randint ( 0 , 20000 , ( 1 , 1024 ))
results = trainer ( data )
results . loss . backward ()
# after much training, the discriminator should have improved
torch . save ( discriminator , f'./pretrained-model.pt' )为了有效训练,生成器的大小应约为鉴别器大小的四分之一到最多一半。任何更大的生成器都会变得太好,对抗性游戏就会崩溃。这是通过减少隐藏维度、前馈隐藏维度和论文中注意力头的数量来完成的。
$ python setup.py test $ mkdir data
$ cd data
$ pip3 install gdown
$ gdown --id 1EA5V0oetDCOke7afsktL_JDQ-ETtNOvx
$ tar -xf openwebtext.tar.xz
$ wget https://storage.googleapis.com/electra-data/vocab.txt
$ cd ..$ python pretraining/openwebtext/preprocess.py$ python pretraining/openwebtext/pretrain.py$ python examples/glue/download.py $ python examples/glue/run.py --model_name_or_path output/yyyy-mm-dd-hh-mm-ss/ckpt/200000 @misc { clark2020electra ,
title = { ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators } ,
author = { Kevin Clark and Minh-Thang Luong and Quoc V. Le and Christopher D. Manning } ,
year = { 2020 } ,
eprint = { 2003.10555 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
}

