se3 transformer pytorch
0.9.0
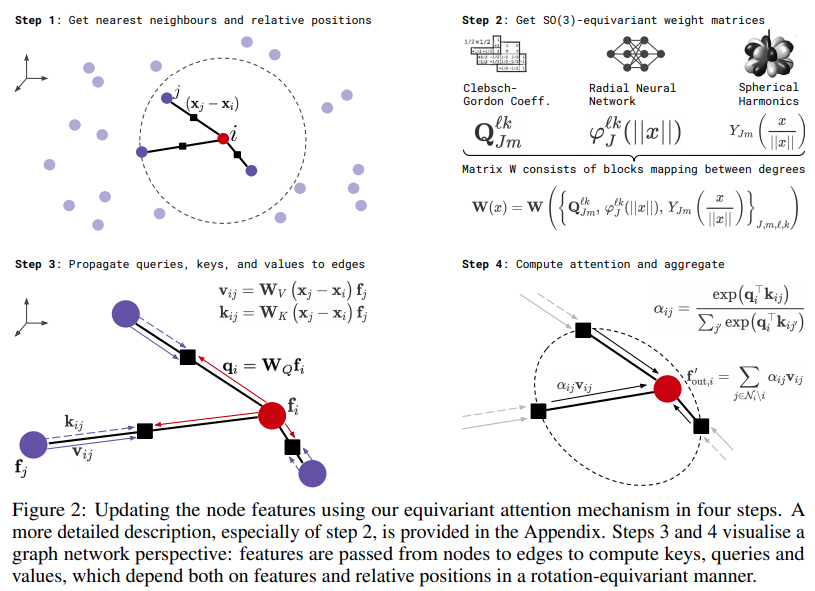
在 Pytorch 中实现用于等变自注意力的 SE3-Transformers。可能需要复制 Alphafold2 结果和其他药物发现应用。
等方差示例
如果您使用过 0.6.0 版本之前的任何版本的 SE3 Transformers,请更新。如果您没有使用邻接稀疏邻居设置并依赖最近邻居功能,@MattMcPartlon 发现了一个巨大的错误
更新:建议您使用 Equiformer 代替
$ pip install se3-transformer-pytorch import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 512 ,
heads = 8 ,
depth = 6 ,
dim_head = 64 ,
num_degrees = 4 ,
valid_radius = 10
)
feats = torch . randn ( 1 , 1024 , 512 )
coors = torch . randn ( 1 , 1024 , 3 )
mask = torch . ones ( 1 , 1024 ). bool ()
out = model ( feats , coors , mask ) # (1, 1024, 512)Alphafold2 中的潜在示例用法,如下所述
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 64 ,
depth = 2 ,
input_degrees = 1 ,
num_degrees = 2 ,
output_degrees = 2 ,
reduce_dim_out = True ,
differentiable_coors = True
)
atom_feats = torch . randn ( 2 , 32 , 64 )
coors = torch . randn ( 2 , 32 , 3 )
mask = torch . ones ( 2 , 32 ). bool ()
refined_coors = coors + model ( atom_feats , coors , mask , return_type = 1 ) # (2, 32, 3)您还可以让基础转换器类负责嵌入传入的 0 型特征。假设它们是原子
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
num_tokens = 28 , # 28 unique atoms
dim = 64 ,
depth = 2 ,
input_degrees = 1 ,
num_degrees = 2 ,
output_degrees = 2 ,
reduce_dim_out = True
)
atoms = torch . randint ( 0 , 28 , ( 2 , 32 ))
coors = torch . randn ( 2 , 32 , 3 )
mask = torch . ones ( 2 , 32 ). bool ()
refined_coors = coors + model ( atoms , coors , mask , return_type = 1 ) # (2, 32, 3)如果您认为网络可以进一步受益于位置编码,您可以特征化您在空间中的位置并将其传递如下。
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 64 ,
depth = 2 ,
input_degrees = 2 ,
num_degrees = 2 ,
output_degrees = 2 ,
reduce_dim_out = True # reduce out the final dimension
)
atom_feats = torch . randn ( 2 , 32 , 64 , 1 ) # b x n x d x type0
coors_feats = torch . randn ( 2 , 32 , 64 , 3 ) # b x n x d x type1
# atom features are type 0, predicted coordinates are type 1
features = { '0' : atom_feats , '1' : coors_feats }
coors = torch . randn ( 2 , 32 , 3 )
mask = torch . ones ( 2 , 32 ). bool ()
refined_coors = coors + model ( features , coors , mask , return_type = 1 ) # (2, 32, 3) - equivariant to input type 1 features and coordinates 要向 SE3 Transformers 提供边缘信息(例如原子之间的键类型),您只需在初始化时再传入两个关键字参数即可。
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
num_tokens = 28 ,
dim = 64 ,
num_edge_tokens = 4 , # number of edge type, say 4 bond types
edge_dim = 16 , # dimension of edge embedding
depth = 2 ,
input_degrees = 1 ,
num_degrees = 3 ,
output_degrees = 1 ,
reduce_dim_out = True
)
atoms = torch . randint ( 0 , 28 , ( 2 , 32 ))
bonds = torch . randint ( 0 , 4 , ( 2 , 32 , 32 ))
coors = torch . randn ( 2 , 32 , 3 )
mask = torch . ones ( 2 , 32 ). bool ()
pred = model ( atoms , coors , mask , edges = bonds , return_type = 0 ) # (2, 32, 1)如果您想传递边缘的连续值,您可以选择不设置num_edge_tokens ,对离散键类型进行编码,然后将其连接到这些连续值的傅里叶特征
import torch
from se3_transformer_pytorch import SE3Transformer
from se3_transformer_pytorch . utils import fourier_encode
model = SE3Transformer (
dim = 64 ,
depth = 1 ,
attend_self = True ,
num_degrees = 2 ,
output_degrees = 2 ,
edge_dim = 34 # edge dimension must match the final dimension of the edges being passed in
)
feats = torch . randn ( 1 , 32 , 64 )
coors = torch . randn ( 1 , 32 , 3 )
mask = torch . ones ( 1 , 32 ). bool ()
pairwise_continuous_values = torch . randint ( 0 , 4 , ( 1 , 32 , 32 , 2 )) # say there are 2
edges = fourier_encode (
pairwise_continuous_values ,
num_encodings = 8 ,
include_self = True
) # (1, 32, 32, 34) - {2 * (2 * 8 + 1)}
out = model ( feats , coors , mask , edges = edges , return_type = 1 )如果您知道点的连通性(假设您正在处理分子),则可以以布尔掩码的形式传入邻接矩阵(其中True表示连通性)。
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 32 ,
heads = 8 ,
depth = 1 ,
dim_head = 64 ,
num_degrees = 2 ,
valid_radius = 10 ,
attend_sparse_neighbors = True , # this must be set to true, in which case it will assert that you pass in the adjacency matrix
num_neighbors = 0 , # if you set this to 0, it will only consider the connected neighbors as defined by the adjacency matrix. but if you set a value greater than 0, it will continue to fetch the closest points up to this many, excluding the ones already specified by the adjacency matrix
max_sparse_neighbors = 8 # you can cap the number of neighbors, sampled from within your sparse set of neighbors as defined by the adjacency matrix, if specified
)
feats = torch . randn ( 1 , 128 , 32 )
coors = torch . randn ( 1 , 128 , 3 )
mask = torch . ones ( 1 , 128 ). bool ()
# placeholder adjacency matrix
# naively assuming the sequence is one long chain (128, 128)
i = torch . arange ( 128 )
adj_mat = ( i [:, None ] <= ( i [ None , :] + 1 )) & ( i [:, None ] >= ( i [ None , :] - 1 ))
out = model ( feats , coors , mask , adj_mat = adj_mat ) # (1, 128, 512)您还可以使用一个额外的关键字num_adj_degrees让网络自动为您导出 N 度邻居。如果您希望系统区分邻居的度数作为边缘信息,请进一步传入非零adj_dim 。
import torch
from se3_transformer_pytorch . se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 64 ,
depth = 1 ,
attend_self = True ,
num_degrees = 2 ,
output_degrees = 2 ,
num_neighbors = 0 ,
attend_sparse_neighbors = True ,
num_adj_degrees = 2 , # automatically derive 2nd degree neighbors
adj_dim = 4 # embed 1st and 2nd degree neighbors (as well as null neighbors) with edge embeddings of this dimension
)
feats = torch . randn ( 1 , 32 , 64 )
coors = torch . randn ( 1 , 32 , 3 )
mask = torch . ones ( 1 , 32 ). bool ()
# placeholder adjacency matrix
# naively assuming the sequence is one long chain (128, 128)
i = torch . arange ( 128 )
adj_mat = ( i [:, None ] <= ( i [ None , :] + 1 )) & ( i [:, None ] >= ( i [ None , :] - 1 ))
out = model ( feats , coors , mask , adj_mat = adj_mat , return_type = 1 )要精细控制每种类型的维度,您可以使用hidden_fiber_dict和out_fiber_dict关键字传入一个字典,其中维度值的程度作为键/值。
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
num_tokens = 28 ,
dim = 64 ,
num_edge_tokens = 4 ,
edge_dim = 16 ,
depth = 2 ,
input_degrees = 1 ,
num_degrees = 3 ,
output_degrees = 1 ,
hidden_fiber_dict = { 0 : 16 , 1 : 8 , 2 : 4 },
out_fiber_dict = { 0 : 16 , 1 : 1 },
reduce_dim_out = False
)
atoms = torch . randint ( 0 , 28 , ( 2 , 32 ))
bonds = torch . randint ( 0 , 4 , ( 2 , 32 , 32 ))
coors = torch . randn ( 2 , 32 , 3 )
mask = torch . ones ( 2 , 32 ). bool ()
pred = model ( atoms , coors , mask , edges = bonds )
pred [ '0' ] # (2, 32, 16)
pred [ '1' ] # (2, 32, 1, 3) 您可以通过传入邻居掩码来进一步控制可以考虑哪些节点。所有False值都将被屏蔽而不予考虑。
import torch
from se3_transformer_pytorch . se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 16 ,
dim_head = 16 ,
attend_self = True ,
num_degrees = 4 ,
output_degrees = 2 ,
num_edge_tokens = 4 ,
num_neighbors = 8 , # make sure you set this value as the maximum number of neighbors set by your neighbor_mask, or it will throw a warning
edge_dim = 2 ,
depth = 3
)
feats = torch . randn ( 1 , 32 , 16 )
coors = torch . randn ( 1 , 32 , 3 )
mask = torch . ones ( 1 , 32 ). bool ()
bonds = torch . randint ( 0 , 4 , ( 1 , 32 , 32 ))
neighbor_mask = torch . ones ( 1 , 32 , 32 ). bool () # set the nodes you wish to be masked out as False
out = model (
feats ,
coors ,
mask ,
edges = bonds ,
neighbor_mask = neighbor_mask ,
return_type = 1
)此功能允许您传入可被视为被所有其他节点看到的全局节点的向量。这个想法是将你的图汇集到几个特征向量中,这些特征向量将被投影到网络中所有注意力层的键/值。所有节点都将完全访问全局节点信息,无论最近邻居或邻接计算如何。
import torch
from torch import nn
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 64 ,
depth = 1 ,
num_degrees = 2 ,
num_neighbors = 4 ,
valid_radius = 10 ,
global_feats_dim = 32 # this must be set to the dimension of the global features, in this example, 32
)
feats = torch . randn ( 1 , 32 , 64 )
coors = torch . randn ( 1 , 32 , 3 )
mask = torch . ones ( 1 , 32 ). bool ()
# naively derive global features
# by pooling features and projecting
global_feats = nn . Linear ( 64 , 32 )( feats . mean ( dim = 1 , keepdim = True )) # (1, 1, 32)
out = model ( feats , coors , mask , return_type = 0 , global_feats = global_feats )待办事项:
您可以使用 SE3 Transformers 自回归,只需一个额外的标志
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 512 ,
heads = 8 ,
depth = 6 ,
dim_head = 64 ,
num_degrees = 4 ,
valid_radius = 10 ,
causal = True # set this to True
)
feats = torch . randn ( 1 , 1024 , 512 )
coors = torch . randn ( 1 , 1024 , 3 )
mask = torch . ones ( 1 , 1024 ). bool ()
out = model ( feats , coors , mask ) # (1, 1024, 512) 我发现使用线性投影键(而不是成对卷积)似乎在玩具去噪任务中表现不错。这可节省 25% 的内存。您可以通过设置linear_proj_keys = True来尝试此功能
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 64 ,
depth = 1 ,
num_degrees = 4 ,
num_neighbors = 8 ,
valid_radius = 10 ,
splits = 4 ,
linear_proj_keys = True # set this to True
). cuda ()
feats = torch . randn ( 1 , 32 , 64 ). cuda ()
coors = torch . randn ( 1 , 32 , 3 ). cuda ()
mask = torch . ones ( 1 , 32 ). bool (). cuda ()
out = model ( feats , coors , mask , return_type = 0 )对于变压器来说,有一种相对未知的技术,可以在所有查询头之间共享一个键/值头。根据我在 NLP 方面的经验,这通常会导致性能更差,但如果您确实需要牺牲内存来换取更多深度或更高的度数,这可能是一个不错的选择。
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 64 ,
depth = 8 ,
num_degrees = 4 ,
num_neighbors = 8 ,
valid_radius = 10 ,
splits = 4 ,
one_headed_key_values = True # one head of key / values shared across all heads of the queries
). cuda ()
feats = torch . randn ( 1 , 32 , 64 ). cuda ()
coors = torch . randn ( 1 , 32 , 3 ). cuda ()
mask = torch . ones ( 1 , 32 ). bool (). cuda ()
out = model ( feats , coors , mask , return_type = 0 )您还可以绑定键/值(让它们相同),以节省一半的内存
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 64 ,
depth = 8 ,
num_degrees = 4 ,
num_neighbors = 8 ,
valid_radius = 10 ,
splits = 4 ,
tie_key_values = True # set this to True
). cuda ()
feats = torch . randn ( 1 , 32 , 64 ). cuda ()
coors = torch . randn ( 1 , 32 , 3 ). cuda ()
mask = torch . ones ( 1 , 32 ). bool (). cuda ()
out = model ( feats , coors , mask , return_type = 0 )这是 EGNN 的实验版本,适用于更高的类型和比 1(对于坐标)更大的维度。类名仍然是SE3Transformer因为它重用了一些预先存在的逻辑,所以暂时忽略它,直到我稍后清理它。
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 32 ,
num_neighbors = 8 ,
num_edge_tokens = 4 ,
edge_dim = 4 ,
num_degrees = 4 , # number of higher order types - will use basis on a TCN to project to these dimensions
use_egnn = True , # set this to true to use EGNN instead of equivariant attention layers
egnn_hidden_dim = 64 , # egnn hidden dimension
depth = 4 , # depth of EGNN
reduce_dim_out = True # will project the dimension of the higher types to 1
). cuda ()
feats = torch . randn ( 2 , 32 , 32 ). cuda ()
coors = torch . randn ( 2 , 32 , 3 ). cuda ()
bonds = torch . randint ( 0 , 4 , ( 2 , 32 , 32 )). cuda ()
mask = torch . ones ( 2 , 32 ). bool (). cuda ()
refinement = model ( feats , coors , mask , edges = bonds , return_type = 1 ) # (2, 32, 3)
coors = coors + refinement # update coors with refinement如果您想为每种较高类型指定单独的维度,只需传入hidden_fiber_dict ,其中字典的格式为{<level>:<dim>},而不是num_degrees
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 32 ,
num_neighbors = 8 ,
hidden_fiber_dict = { 0 : 32 , 1 : 16 , 2 : 8 , 3 : 4 },
use_egnn = True ,
depth = 4 ,
egnn_hidden_dim = 64 ,
egnn_weights_clamp_value = 2 ,
reduce_dim_out = True
). cuda ()
feats = torch . randn ( 2 , 32 , 32 ). cuda ()
coors = torch . randn ( 2 , 32 , 3 ). cuda ()
mask = torch . ones ( 2 , 32 ). bool (). cuda ()
refinement = model ( feats , coors , mask , return_type = 1 ) # (2, 32, 3)
coors = coors + refinement # update coors with refinement 本节将列出为使 SE3 Transformer 的可扩展性更好一些所做的持续努力。
首先,我添加了可逆网络。这使我能够在遇到通常的内存障碍之前增加一点深度。测试证明了等方差保持。
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
num_tokens = 20 ,
dim = 32 ,
dim_head = 32 ,
heads = 4 ,
depth = 12 , # 12 layers
input_degrees = 1 ,
num_degrees = 3 ,
output_degrees = 1 ,
reduce_dim_out = True ,
reversible = True # set reversible to True
). cuda ()
atoms = torch . randint ( 0 , 4 , ( 2 , 32 )). cuda ()
coors = torch . randn ( 2 , 32 , 3 ). cuda ()
mask = torch . ones ( 2 , 32 ). bool (). cuda ()
pred = model ( atoms , coors , mask = mask , return_type = 0 )
loss = pred . sum ()
loss . backward ()首先安装sidechainnet
$ pip install sidechainnet然后运行蛋白质主干去噪任务
$ python denoise.py默认情况下,基向量被缓存。但是,如果需要清除缓存,您只需在启动脚本时将环境标志CLEAR_CACHE设置为某个值即可
$ CLEAR_CACHE=1 python train.py或者您可以尝试删除缓存目录,该目录应该存在于
$ rm -rf ~ /.cache.equivariant_attention您还可以指定自己想要存储缓存的目录,以防默认目录可能存在权限问题
CACHE_PATH=./path/to/my/cache python train.py$ python setup.py pytest该库主要是 Fabian 官方存储库的移植,但没有 DGL 库。
@misc { fuchs2020se3transformers ,
title = { SE(3)-Transformers: 3D Roto-Translation Equivariant Attention Networks } ,
author = { Fabian B. Fuchs and Daniel E. Worrall and Volker Fischer and Max Welling } ,
year = { 2020 } ,
eprint = { 2006.10503 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @misc { satorras2021en ,
title = { E(n) Equivariant Graph Neural Networks } ,
author = { Victor Garcia Satorras and Emiel Hoogeboom and Max Welling } ,
year = { 2021 } ,
eprint = { 2102.09844 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @misc { gomez2017reversible ,
title = { The Reversible Residual Network: Backpropagation Without Storing Activations } ,
author = { Aidan N. Gomez and Mengye Ren and Raquel Urtasun and Roger B. Grosse } ,
year = { 2017 } ,
eprint = { 1707.04585 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { shazeer2019fast ,
title = { Fast Transformer Decoding: One Write-Head is All You Need } ,
author = { Noam Shazeer } ,
year = { 2019 } ,
eprint = { 1911.02150 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.NE }
}

