RoboFlamingo
1.0.0
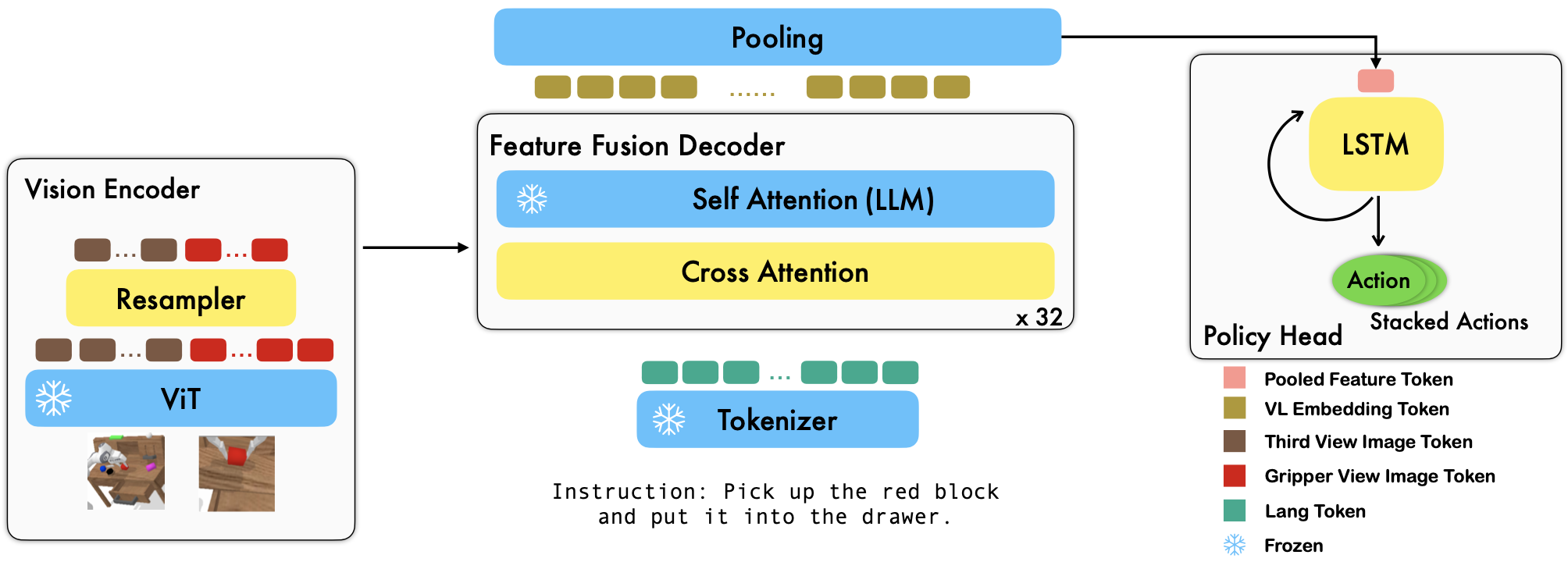
RoboFlamingo是一个基于 VLM 的预训练机器人学习框架,通过对离线自由形式模仿数据集进行微调来学习各种语言调节的机器人技能。通过在 CALVIN 基准上大幅超越最先进的性能,我们表明 RoboFlamingo 可以成为使 VLM 适应机器人控制的有效且有竞争力的替代方案。我们广泛的实验结果还揭示了关于不同预训练 VLM 在操作任务上的行为的几个有趣的结论。 RoboFlamingo 可以在单个 GPU 服务器上进行训练或评估(GPU 内存要求取决于模型大小),我们相信 RoboFlamingo 有潜力成为一种经济高效且易于使用的机器人操作解决方案,让每个人都能获得微调自己的机器人政策的能力。
这也是论文《视觉语言基础模型作为有效机器人模仿者》的官方代码库。
我们所有的实验都是在具有 8 个 Nvidia A100 GPU (80G) 的单个 GPU 服务器上进行的。
Hugging Face 上提供了预训练模型。
我们支持 OpenCLIP 包中的预训练视觉编码器,其中包括 OpenAI 的预训练模型。我们还支持transformers包中的预训练语言模型,例如 MPT、RedPajama、LLaMA、OPT、GPT-Neo、GPT-J 和 Pythia 模型。
from robot_flamingo . factor import create_model_and_transforms
model , image_processor , tokenizer = create_model_and_transforms (
clip_vision_encoder_path = "ViT-L-14" ,
clip_vision_encoder_pretrained = "openai" ,
lang_encoder_path = "PATH/TO/LLM/DIR" ,
tokenizer_path = "PATH/TO/LLM/DIR" ,
cross_attn_every_n_layers = 1 ,
decoder_type = 'lstm' ,
) cross_attn_every_n_layers参数控制交叉注意力层的应用频率,并且应该与 VLM 一致。 decoder_type参数控制解码器的类型,目前,我们支持lstm 、 fc 、 diffusion (数据加载器存在错误)和GPT 。
我们报告 CALVIN 基准测试的结果。
| 方法 | 训练数据 | 测试拆分 | 1 | 2 | 3 | 4 | 5 | 平均长度 |
|---|---|---|---|---|---|---|---|---|
| MCIL | ABCD(完整) | D | 0.373 | 0.027 | 0.002 | 0.000 | 0.000 | 0.40 |
| HULC | ABCD(完整) | D | 0.889 | 0.733 | 0.587 | 0.475 | 0.383 | 3.06 |
| HULC(重新训练) | ABCD(郎) | D | 0.892 | 0.701 | 0.548 | 0.420 | 0.335 | 2.90 |
| RT-1(重新训练) | ABCD(郎) | D | 0.844 | 0.617 | 0.438 | 0.323 | 0.227 | 2.45 |
| 我们的 | ABCD(郎) | D | 0.964 | 0.896 | 0.824 | 0.740 | 0.66 | 4.09 |
| MCIL | ABC(完整) | D | 0.304 | 0.013 | 0.002 | 0.000 | 0.000 | 0.31 |
| HULC | ABC(完整) | D | 0.418 | 0.165 | 0.057 | 0.019 | 0.011 | 0.67 |
| RT-1(重新训练) | ABC(郎) | D | 0.533 | 0.222 | 0.094 | 0.038 | 0.013 | 0.90 |
| 我们的 | ABC(郎) | D | 0.824 | 0.619 | 0.466 | 0.331 | 0.235 | 2.48 |
| HULC | ABCD(完整) | D(丰富) | 0.715 | 0.470 | 0.308 | 0.199 | 0.130 | 1.82 |
| RT-1(重新训练) | ABCD(郎) | D(丰富) | 0.494 | 0.222 | 0.086 | 0.036 | 0.017 | 0.86 |
| 我们的 | ABCD(郎) | D(丰富) | 0.720 | 0.480 | 0.299 | 0.211 | 0.144 | 1.85 |
| 我们的(冷冻嵌入) | ABCD(郎) | D(丰富) | 0.737 | 0.530 | 0.385 | 0.275 | 0.192 | 2.12 |
按照 OpenFlamingo 和 CALVIN 中的说明下载必要的数据集和 VLM 预训练模型。
下载 CALVIN 数据集,选择一个分割:
cd $HULC_ROOT /dataset
sh download_data.sh D | ABC | ABCD | debug下载已发布的 OpenFlamingo 模型:
| # 参数 | 语言模型 | 视觉编码器 | Xattn 间隔* | COCO 4 瓶苹果酒 | VQAv2 4 次精度 | 平均长度 | 重量 |
|---|---|---|---|---|---|---|---|
| 3B | 阿纳斯-阿瓦达拉/mpt-1b-redpajama-200b | openai CLIP ViT-L/14 | 1 | 77.3 | 45.8 | 3.94 | 关联 |
| 3B | 阿纳斯-阿瓦达拉/mpt-1b-redpajama-200b-dolly | openai CLIP ViT-L/14 | 1 | 82.7 | 45.7 | 4.09 | 关联 |
| 4B | 一起电脑/RedPajama-INCITE-Base-3B-v1 | openai CLIP ViT-L/14 | 2 | 81.8 | 49.0 | 3.67 | 关联 |
| 4B | Togethercomputer/RedPajama-INCITE-Instruct-3B-v1 | openai CLIP ViT-L/14 | 2 | 85.8 | 49.0 | 3.79 | 关联 |
| 9B | 阿纳斯-阿瓦达拉/mpt-7b | openai CLIP ViT-L/14 | 4 | 89.0 | 54.8 | 3.97 | 关联 |
将robot_flamingo/models/factory.py中每个预训练 VLM 的路径字典(例如mpt_dict )的${lang_encoder_path}和${tokenizer_path}替换为您自己的路径。
克隆这个仓库
git clone https://github.com/RoboFlamingo/RoboFlamingo.git
安装所需的软件包:
cd RoboFlamingo
conda create -n RoboFlamingo python=3.8
source activate RoboFlamingo
pip install -r requirements.txt
torchrun --nnodes=1 --nproc_per_node=8 --master_port=6042 robot_flamingo/train/train_calvin.py
--report_to_wandb
--llm_name mpt_dolly_3b
--traj_cons
--use_gripper
--fusion_mode post
--rgb_pad 10
--gripper_pad 4
--precision fp32
--num_epochs 5
--gradient_accumulation_steps 1
--batch_size_calvin 6
--run_name RobotFlamingoDBG
--calvin_dataset ${calvin_dataset_path}
--lm_path ${lm_path}
--tokenizer_path ${tokenizer_path}
--openflamingo_checkpoint ${openflamingo_checkpoint}
--cross_attn_every_n_layers 4
--dataset_resampled
--loss_multiplier_calvin 1.0
--workers 1
--lr_scheduler constant
--warmup_steps 5000
--learning_rate 1e-4
--save_every_iter 10000
--from_scratch
--window_size 12 > ${log_file} 2>&1
${calvin_dataset_path}是CALVIN数据集的路径;
${lm_path}是预训练的LLM的路径;
${tokenizer_path}是VLM分词器的路径;
${openflamingo_checkpoint}是OpenFlamingo预训练模型的路径;
${log_file}是日志文件的路径。
我们还提供了robot_flamingo/pt_run_gripper_post_ws_12_traj_aug_mpt_dolly_3b.bash来启动训练。这个bash对OpenFlamingo模型的MPT-3B-IFT版本进行了微调,其中包含训练模型的默认超参数,并且对应于论文中的最佳结果。
python eval_ckpts.py
通过将检查点名称和目录添加到eval_ckpts.py中,脚本将自动加载模型并对其进行评估。例如,如果要评估路径“your-checkpoint-path”处的检查点,可以修改 eval_ckpts.py 中的ckpt_dir和ckpt_names变量,评估结果将保存为“logs/your-checkpoint-prefix”。日志'。
下面显示的结果表明,协同训练可以保留 VLM 主干在 VL 任务上的大部分能力,同时在机器人任务上损失一些性能。
使用
bash robot_flamingo/pt_run_gripper_post_ws_12_traj_aug_mpt_dolly_3b_co_train.bash
与 CoCO、VQAV2 和 CALVIN 联合训练 RoboFlamingo。您应该更新robot_flamingo/data/data.py中get_coco_dataset和get_vqa_dataset中的 CoCO 和 VQA 路径。
| 分裂 | SR 1 | SR 2 | SR 3 | SR 4 | SR 5 | 平均长度 |
|---|---|---|---|---|---|---|
| 协同训练 | ABC->D | 82.9% | 63.6% | 45.3% | 32.1% | 23.4% |
| 微调 | ABC->D | 82.4% | 61.9% | 46.6% | 33.1% | 23.5% |
| 协同训练 | ABCD->D | 95.7% | 85.8% | 73.7% | 64.5% | 56.1% |
| 微调 | ABCD->D | 96.4% | 89.6% | 82.4% | 74.0% | 66.2% |
| 协同训练 | ABCD->D(丰富) | 67.8% | 45.2% | 29.4% | 18.9% | 11.7% |
| 微调 | ABCD->D(丰富) | 72.0% | 48.0% | 29.9% | 21.1% | 14.4% |
| 可可 | 质量保证 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| BLEU-1 | 蓝二号 | BLEU-3 | BLEU-4 | 流星 | 胭脂_L | 苹果酒 | 香料 | 加速器 | |
| 微调(3B,零样本) | 0.156 | 0.051 | 0.018 | 0.007 | 0.038 | 0.148 | 0.004 | 0.006 | 4.09 |
| 微调(3B、4 镜头) | 0.166 | 0.056 | 0.020 | 0.008 | 0.042 | 0.158 | 0.004 | 0.008 | 3.87 |
| 协同训练(3B,零样本) | 0.225 | 0.158 | 0.107 | 0.072 | 0.124 | 0.334 | 0.345 | 0.085 | 36.37 |
| 原始火烈鸟(80B,微调) | - | - | - | - | - | - | 1.381 | - | 82.0 |
该徽标是使用 MidJourney 生成的
这项工作使用以下开源项目和数据集的代码:
原文:https://github.com/mees/calvin 许可:MIT
原文:https://github.com/openai/CLIP 许可:MIT
原文:https://github.com/mlfoundations/open_flamingo 许可证:MIT
@article{li2023vision,
title = {Vision-Language Foundation Models as Effective Robot Imitators},
author = {Li, Xinghang and Liu, Minghuan and Zhang, Hanbo and Yu, Cunjun and Xu, Jie and Wu, Hongtao and Cheang, Chilam and Jing, Ya and Zhang, Weinan and Liu, Huaping and Li, Hang and Kong, Tao},
journal={arXiv preprint arXiv:2311.01378},
year={2023}


