nuwa pytorch
0.7.8
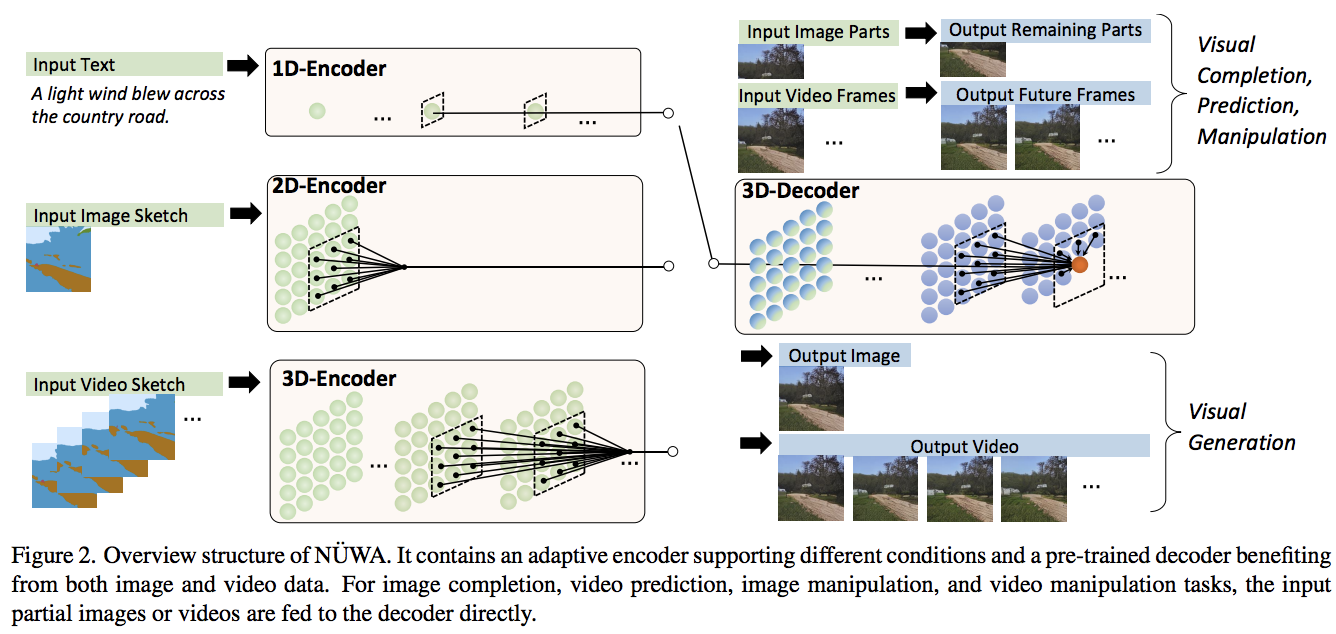
在 Pytorch 中实现 NÜWA,这是用于文本到视频合成的最先进的注意力网络。它还包含使用双解码器方法的视频和音频生成的扩展。
雅尼克·基尔彻
深度阅读器
2022 年 3 月 - 通过难度版本的移动 mnist 看到生命的迹象
2022 年 4 月 - 似乎基于扩散的方法已经占据了 SOTA 的新王座。不过,我将继续使用 NUWA,将其扩展为使用多头代码 + 分层因果变换器。我认为这个方向尚未开发用于改进这方面的工作。
$ pip install nuwa-pytorch首先训练 VAE
import torch
from nuwa_pytorch import VQGanVAE
vae = VQGanVAE (
dim = 512 ,
channels = 3 , # default is 3, but can be changed to any value for the training of the segmentation masks (sketches)
image_size = 256 , # image size
num_layers = 4 , # number of downsampling layers
num_resnet_blocks = 2 , # number of resnet blocks
vq_codebook_size = 8192 , # codebook size
vq_decay = 0.8 # codebook exponential decay
)
imgs = torch . randn ( 10 , 3 , 256 , 256 )
# alternate learning for autoencoder ...
loss = vae ( imgs , return_loss = True )
loss . backward ()
# and the discriminator ...
discr_loss = vae ( imgs , return_discr_loss = True )
discr_loss . backward ()
# do above for many steps
# return reconstructed images and make sure they look ok
recon_imgs = vae ( imgs )然后,用你学到的 VAE
import torch
from nuwa_pytorch import NUWA , VQGanVAE
# autoencoder
vae = VQGanVAE (
dim = 64 ,
num_layers = 4 ,
image_size = 256 ,
num_conv_blocks = 2 ,
vq_codebook_size = 8192
)
# NUWA transformer
nuwa = NUWA (
vae = vae ,
dim = 512 ,
text_num_tokens = 20000 , # number of text tokens
text_enc_depth = 12 , # text encoder depth
text_enc_heads = 8 , # number of attention heads for encoder
text_max_seq_len = 256 , # max sequence length of text conditioning tokens (keep at 256 as in paper, or shorter, if your text is not that long)
max_video_frames = 10 , # number of video frames
image_size = 256 , # size of each frame of video
dec_depth = 64 , # video decoder depth
dec_heads = 8 , # number of attention heads in decoder
dec_reversible = True , # reversible networks - from reformer, decoupling memory usage from depth
enc_reversible = True , # reversible encoders, if you need it
attn_dropout = 0.05 , # dropout for attention
ff_dropout = 0.05 , # dropout for feedforward
sparse_3dna_kernel_size = ( 5 , 3 , 3 ), # kernel size of the sparse 3dna attention. can be a single value for frame, height, width, or different values (to simulate axial attention, etc)
sparse_3dna_dilation = ( 1 , 2 , 4 ), # cycle dilation of 3d conv attention in decoder, for more range
shift_video_tokens = True # cheap relative positions for sparse 3dna transformer, by shifting along spatial dimensions by one
). cuda ()
# data
text = torch . randint ( 0 , 20000 , ( 1 , 256 )). cuda ()
video = torch . randn ( 1 , 10 , 3 , 256 , 256 ). cuda () # (batch, frames, channels, height, width)
loss = nuwa (
text = text ,
video = video ,
return_loss = True # set this to True, only for training, to return cross entropy loss
)
loss . backward ()
# do above with as much data as possible
# then you can generate a video from text
video = nuwa . generate ( text = text , num_frames = 5 ) # (1, 5, 3, 256, 256) 在论文中,他们还提出了一种基于分割掩模来调节视频生成的方法。如果您事先在草图上训练了VQGanVAE ,您也可以轻松做到这一点。
然后,您将使用NUWASketch而不是NUWA ,它可以接受草图 VAE 作为参考
前任。
import torch
from nuwa_pytorch import NUWASketch , VQGanVAE
# autoencoder, one for main video, the other for the sketch
vae = VQGanVAE (
dim = 64 ,
num_layers = 4 ,
image_size = 256 ,
num_conv_blocks = 2 ,
vq_codebook_size = 8192
)
sketch_vae = VQGanVAE (
dim = 512 ,
channels = 5 , # say the sketch has 5 classes
num_layers = 4 ,
image_size = 256 ,
num_conv_blocks = 2 ,
vq_codebook_size = 8192
)
# NUWA transformer for conditioning with sketches
nuwa = NUWASketch (
vae = vae ,
sketch_vae = sketch_vae ,
dim = 512 , # model dimensions
sketch_enc_depth = 12 , # sketch encoder depth
sketch_enc_heads = 8 , # number of attention heads for sketch encoder
sketch_max_video_frames = 3 , # max number of frames for sketches
sketch_enc_use_sparse_3dna = True , # whether to use 3d-nearby attention (of full attention if False) for sketch encoding transformer
max_video_frames = 10 , # number of video frames
image_size = 256 , # size of each frame of video
dec_depth = 64 , # video decoder depth
dec_heads = 8 , # number of attention heads in decoder
dec_reversible = True , # reversible networks - from reformer, decoupling memory usage from depth
enc_reversible = True , # reversible encoders, if you need it
attn_dropout = 0.05 , # dropout for attention
ff_dropout = 0.05 , # dropout for feedforward
sparse_3dna_kernel_size = ( 5 , 3 , 3 ), # kernel size of the sparse 3dna attention. can be a single value for frame, height, width, or different values (to simulate axial attention, etc)
sparse_3dna_dilation = ( 1 , 2 , 4 ), # cycle dilation of 3d conv attention in decoder, for more range
cross_2dna_kernel_size = 5 , # 2d kernel size of spatial grouping of attention from video frames to sketches
cross_2dna_dilation = 1 , # 2d dilation of spatial attention from video frames to sketches
shift_video_tokens = True # cheap relative positions for sparse 3dna transformer, by shifting along spatial dimensions by one
). cuda ()
# data
sketch = torch . randn ( 2 , 2 , 5 , 256 , 256 ). cuda () # (batch, frames, segmentation classes, height, width)
sketch_mask = torch . ones ( 2 , 2 ). bool (). cuda () # (batch, frames) [Optional]
video = torch . randn ( 2 , 10 , 3 , 256 , 256 ). cuda () # (batch, frames, channels, height, width)
loss = nuwa (
sketch = sketch ,
sketch_mask = sketch_mask ,
video = video ,
return_loss = True # set this to True, only for training, to return cross entropy loss
)
loss . backward ()
# do above with as much data as possible
# then you can generate a video from sketch(es)
video = nuwa . generate ( sketch = sketch , num_frames = 5 ) # (1, 5, 3, 256, 256) 该存储库还将提供可以生成视频和音频的 NUWA 变体。目前,音频需要手动编码。
import torch
from nuwa_pytorch import NUWAVideoAudio , VQGanVAE
# autoencoder
vae = VQGanVAE (
dim = 64 ,
num_layers = 4 ,
image_size = 256 ,
num_conv_blocks = 2 ,
vq_codebook_size = 100
)
# NUWA transformer
nuwa = NUWAVideoAudio (
vae = vae ,
dim = 512 ,
num_audio_tokens = 2048 , # codebook size for audio tokens
num_audio_tokens_per_video_frame = 32 , # number of audio tokens per video frame
cross_modality_attn_every = 3 , # cross modality attention every N layers
text_num_tokens = 20000 , # number of text tokens
text_enc_depth = 1 , # text encoder depth
text_enc_heads = 8 , # number of attention heads for encoder
text_max_seq_len = 256 , # max sequence length of text conditioning tokens (keep at 256 as in paper, or shorter, if your text is not that long)
max_video_frames = 10 , # number of video frames
image_size = 256 , # size of each frame of video
dec_depth = 4 , # video decoder depth
dec_heads = 8 , # number of attention heads in decoder
enc_reversible = True , # reversible encoders, if you need it
dec_reversible = True , # quad-branched reversible network, for making depth of twin video / audio decoder independent of network depth. recommended to be turned on unless you have a ton of memory at your disposal
attn_dropout = 0.05 , # dropout for attention
ff_dropout = 0.05 , # dropout for feedforward
sparse_3dna_kernel_size = ( 5 , 3 , 3 ), # kernel size of the sparse 3dna attention. can be a single value for frame, height, width, or different values (to simulate axial attention, etc)
sparse_3dna_dilation = ( 1 , 2 , 4 ), # cycle dilation of 3d conv attention in decoder, for more range
shift_video_tokens = True # cheap relative positions for sparse 3dna transformer, by shifting along spatial dimensions by one
). cuda ()
# data
text = torch . randint ( 0 , 20000 , ( 1 , 256 )). cuda ()
audio = torch . randint ( 0 , 2048 , ( 1 , 32 * 10 )). cuda () # (batch, audio tokens per frame * max video frames)
video = torch . randn ( 1 , 10 , 3 , 256 , 256 ). cuda () # (batch, frames, channels, height, width)
loss = nuwa (
text = text ,
video = video ,
audio = audio ,
return_loss = True # set this to True, only for training, to return cross entropy loss
)
loss . backward ()
# do above with as much data as possible
# then you can generate a video from text
video , audio = nuwa . generate ( text = text , num_frames = 5 ) # (1, 5, 3, 256, 256), (1, 32 * 5 == 160) 该库将提供一些实用程序以使培训变得更容易。对于初学者,您可以使用VQGanVAETrainer类来训练VQGanVAE 。只需包装模型并传入图像文件夹路径以及各种训练超参数即可。
import torch
from nuwa_pytorch import VQGanVAE , VQGanVAETrainer
vae = VQGanVAE (
dim = 64 ,
image_size = 256 ,
num_layers = 5 ,
vq_codebook_size = 1024 ,
vq_use_cosine_sim = True ,
vq_codebook_dim = 32 ,
vq_orthogonal_reg_weight = 10 ,
vq_orthogonal_reg_max_codes = 128 ,
). cuda ()
trainer = VQGanVAETrainer (
vae , # VAE defined above
folder = '/path/to/images' , # path to images
lr = 3e-4 , # learning rate
num_train_steps = 100000 , # number of training steps
batch_size = 8 , # batch size
grad_accum_every = 4 # gradient accumulation (effective batch size is (batch_size x grad_accum_every))
)
trainer . train ()
# results and model checkpoints will be saved periodically to ./results要训练 NUWA,首先您需要组织一个.gif文件文件夹以及包含其标题的相应.txt文件。它应该这样组织。
前任。
video-and-text-data
┣ cat.gif
┣ cat.txt
┣ dog.gif
┣ dog.txt
┣ turtle.gif
┗ turtle.txt
然后,您将加载之前训练的 VQGan-VAE 并使用GifVideoDataset和NUWATrainer类训练 NUWA。
import torch
from nuwa_pytorch import NUWA , VQGanVAE
from nuwa_pytorch . train_nuwa import GifVideoDataset , NUWATrainer
# dataset
ds = GifVideoDataset (
folder = './path/to/videos/' ,
channels = 1
)
# autoencoder
vae = VQGanVAE (
dim = 64 ,
image_size = 256 ,
num_layers = 5 ,
num_resnet_blocks = 2 ,
vq_codebook_size = 512 ,
attn_dropout = 0.1
)
vae . load_state_dict ( torch . load ( './path/to/trained/vae.pt' ))
# NUWA transformer
nuwa = NUWA (
vae = vae ,
dim = 512 ,
text_enc_depth = 6 ,
text_max_seq_len = 256 ,
max_video_frames = 10 ,
dec_depth = 12 ,
dec_reversible = True ,
enc_reversible = True ,
attn_dropout = 0.05 ,
ff_dropout = 0.05 ,
sparse_3dna_kernel_size = ( 5 , 3 , 3 ),
sparse_3dna_dilation = ( 1 , 2 , 4 ),
shift_video_tokens = True
). cuda ()
# data
trainer = NUWATrainer (
nuwa = nuwa , # NUWA transformer
dataset = dataset , # video dataset class
num_train_steps = 1000000 , # number of training steps
lr = 3e-4 , # learning rate
wd = 0.01 , # weight decay
batch_size = 8 , # batch size
grad_accum_every = 4 , # gradient accumulation
max_grad_norm = 0.5 , # gradient clipping
num_sampled_frames = 10 , # number of frames to sample
results_folder = './results' # folder to store checkpoints and samples
)
trainer . train ()该库依赖于该矢量量化库,该库进行了许多改进(改进的 vqgan、正交码本正则化等)。要使用这些改进中的任何一项,您可以通过在VQGanVAE初始化上添加vq_来配置矢量量化器关键字参数。
前任。改进的vqgan中提出的cosine sim
from nuwa_pytorch import VQGanVAE
vae = VQGanVAE (
dim = 64 ,
image_size = 256 ,
num_layers = 4 ,
vq_use_cosine_sim = True
# VectorQuantize will be initialized with use_cosine_sim = True
# https://github.com/lucidrains/vector-quantize-pytorch#cosine-similarity
). cuda () @misc { wu2021nuwa ,
title = { N"UWA: Visual Synthesis Pre-training for Neural visUal World creAtion } ,
author = { Chenfei Wu and Jian Liang and Lei Ji and Fan Yang and Yuejian Fang and Daxin Jiang and Nan Duan } ,
year = { 2021 } ,
eprint = { 2111.12417 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { esser2021taming ,
title = { Taming Transformers for High-Resolution Image Synthesis } ,
author = { Patrick Esser and Robin Rombach and Björn Ommer } ,
year = { 2021 } ,
eprint = { 2012.09841 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { iashin2021taming ,
title = { Taming Visually Guided Sound Generation } ,
author = { Vladimir Iashin and Esa Rahtu } ,
year = { 2021 } ,
eprint = { 2110.08791 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { ding2021cogview ,
title = { CogView: Mastering Text-to-Image Generation via Transformers } ,
author = { Ming Ding and Zhuoyi Yang and Wenyi Hong and Wendi Zheng and Chang Zhou and Da Yin and Junyang Lin and Xu Zou and Zhou Shao and Hongxia Yang and Jie Tang } ,
year = { 2021 } ,
eprint = { 2105.13290 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { kitaev2020reformer ,
title = { Reformer: The Efficient Transformer } ,
author = { Nikita Kitaev and Łukasz Kaiser and Anselm Levskaya } ,
year = { 2020 } ,
eprint = { 2001.04451 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @misc { shazeer2020talkingheads ,
title = { Talking-Heads Attention } ,
author = { Noam Shazeer and Zhenzhong Lan and Youlong Cheng and Nan Ding and Le Hou } ,
year = { 2020 } ,
eprint = { 2003.02436 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @misc { shazeer2020glu ,
title = { GLU Variants Improve Transformer } ,
author = { Noam Shazeer } ,
year = { 2020 } ,
url = { https://arxiv.org/abs/2002.05202 }
} @misc { su2021roformer ,
title = { RoFormer: Enhanced Transformer with Rotary Position Embedding } ,
author = { Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu } ,
year = { 2021 } ,
eprint = { 2104.09864 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @inproceedings { ho2021classifierfree ,
title = { Classifier-Free Diffusion Guidance } ,
author = { Jonathan Ho and Tim Salimans } ,
booktitle = { NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications } ,
year = { 2021 } ,
url = { https://openreview.net/forum?id=qw8AKxfYbI }
} @misc { liu2021swin ,
title = { Swin Transformer V2: Scaling Up Capacity and Resolution } ,
author = { Ze Liu and Han Hu and Yutong Lin and Zhuliang Yao and Zhenda Xie and Yixuan Wei and Jia Ning and Yue Cao and Zheng Zhang and Li Dong and Furu Wei and Baining Guo } ,
year = { 2021 } ,
eprint = { 2111.09883 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { crowson2022 ,
author = { Katherine Crowson } ,
url = { https://twitter.com/RiversHaveWings/status/1478093658716966912 }
}关注是最稀有、最纯粹的慷慨形式。 ——西蒙娜·韦尔


