algebraic nnhw
1.0.0
该存储库包含 ML 硬件架构的源代码,该架构需要近一半数量的乘法器单元才能实现相同的性能,通过执行替代内积算法,将近一半的乘法换成廉价的低位宽加法,同时仍然产生相同的输出作为常规内积。这增加了机器学习加速器的理论吞吐量和计算效率限制。有关完整详细信息,请参阅以下期刊出版物:
TE Pogue 和 N. Nicolici,“深度神经网络加速器的快速内积算法和架构”,载于 IEEE 计算机学报,卷。 73、没有。 2,第 495-509 页,2024 年 2 月,doi:10.1109/TC.2023.3334140。
文章网址:https://ieeexplore.ieee.org/document/10323219
开放获取版本:https://arxiv.org/abs/2311.12224
摘要:我们介绍了一种称为自由管道快速内积 (FFIP) 的新算法及其硬件架构,该算法改进了 Winograd 于 1968 年提出的尚未探索的快速内积算法 (FIP)。卷积层,FIP 适用于所有主要可分解为矩阵乘法的机器学习 (ML) 模型层,包括全连接层、卷积层、循环层和注意力/变换器层。我们首次在 ML 加速器中实现 FIP,然后介绍我们的 FFIP 算法和通用架构,这些算法和通用架构本质上提高了 FIP 的时钟频率,从而提高了类似硬件成本的吞吐量。最后,我们为 FIP 和 FFIP 算法和架构提供特定于 ML 的优化。我们证明,FFIP 可以无缝集成到传统定点脉动阵列 ML 加速器中,以一半数量的乘法累加 (MAC) 单元实现相同的吞吐量,或者它可以将最大脉动阵列尺寸加倍,以适应具有以下功能的设备:固定的硬件预算。我们针对具有 8 至 16 位定点输入的非稀疏 ML 模型的 FFIP 实现实现了比同类计算平台上同类最佳的现有解决方案更高的吞吐量和计算效率。
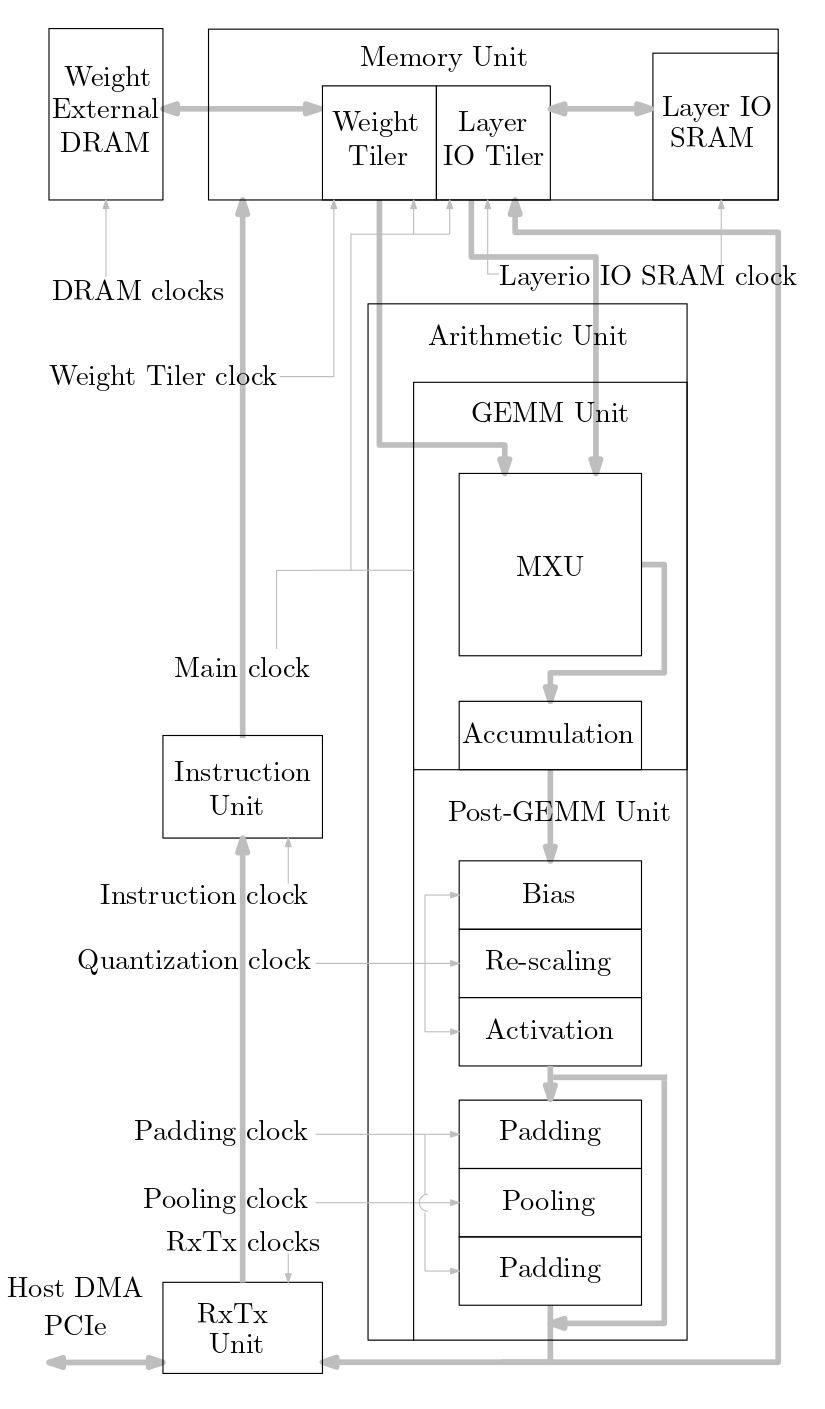
下图显示了此源代码中实现的机器学习加速器系统的概述:
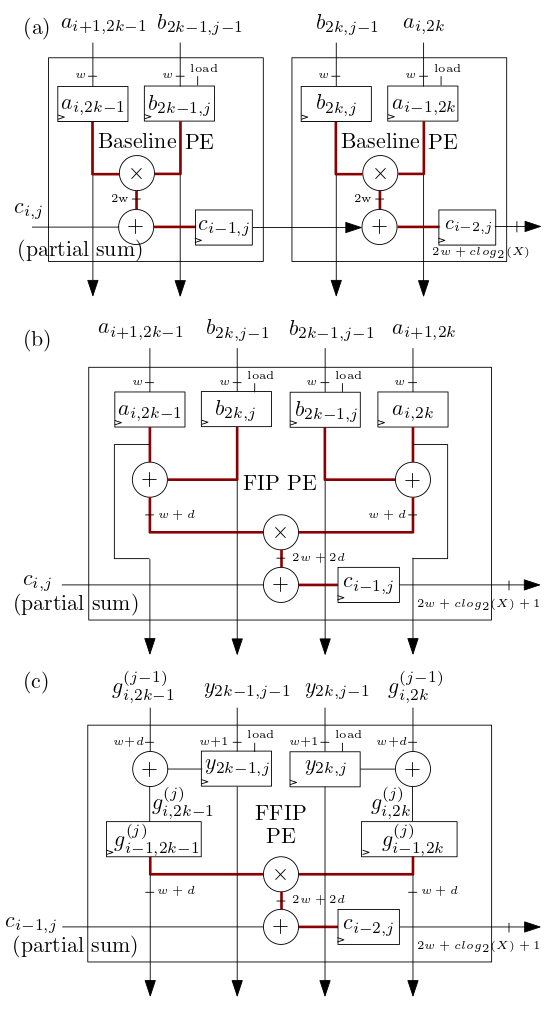
下面 (b) 和 (c) 中所示的 FIP 和 FFIP 脉动阵列/MXU 处理元件 (PE) 实现 FIP 和 FFIP 内积算法,并且每个单独提供与 (b) 和 (c) 中所示的两个基线 PE 相同的有效计算能力。 a) 与之前的脉动阵列机器学习加速器一样,实现基线内积:
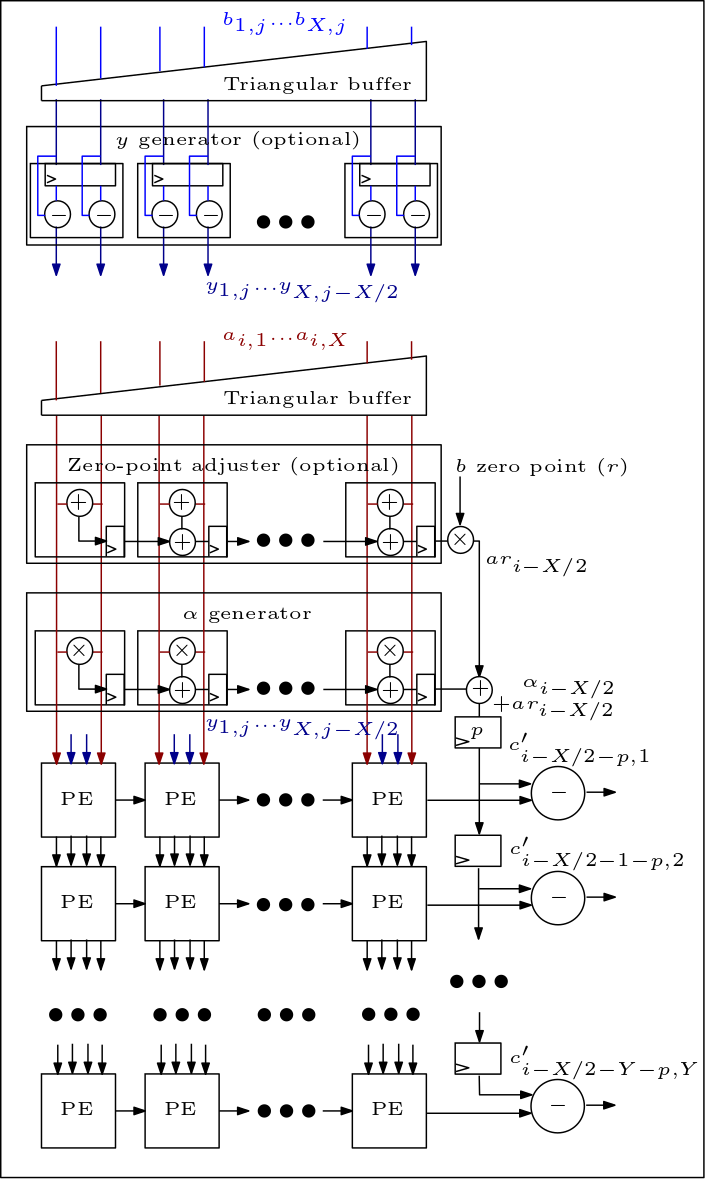
下图是 MXU/脉动阵列的示意图,显示了 PE 的连接方式:
源码组织如下:
文件 rtl/top/define.svh 和 rtl/top/pkg.sv 包含许多可配置参数,例如 Define.svh 中的 FIP_METHOD 定义脉动阵列类型(基线、FIP 或 FFIP),SZI 和 SZJ 定义脉动数组高度/宽度,以及定义输入位宽的 LAYERIO_WIDTH/WEIGHT_WIDTH。
目录 rtl/arith 包括 mxu.sv 和 mac_array.sv,其中包含基线、FIP 和 FFIP 脉动阵列架构的 RTL(取决于参数 FIP_METHOD 的值)。


