lumiere pytorch
0.0.24
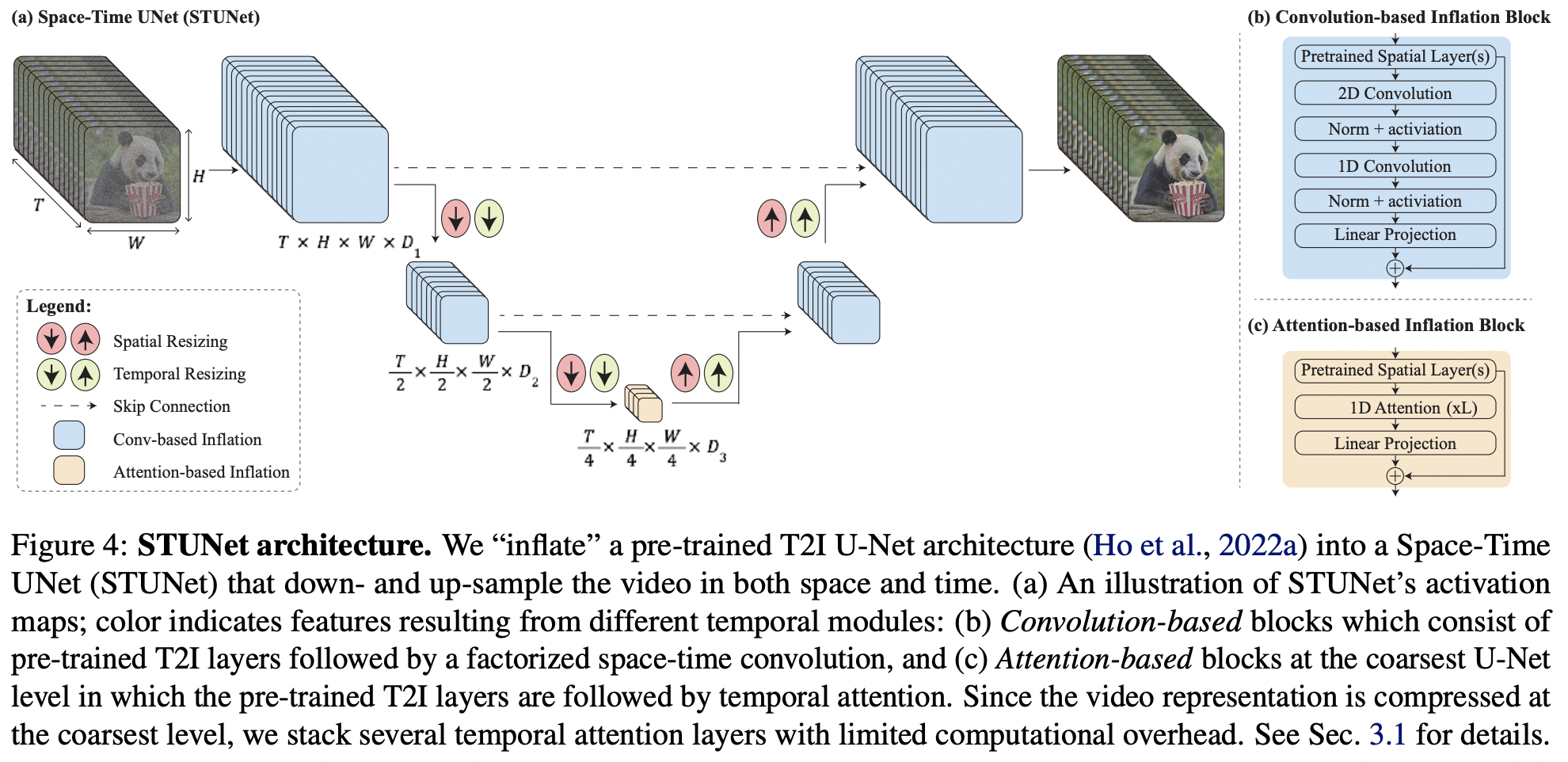
在 Pytorch 中实现 Lumiere(来自 Google Deepmind 的 SOTA 文本到视频生成)
Yannic 的论文评论
由于本文主要只是文本到图像模型之上的一些关键想法,因此将更进一步,将新的 Karras U-net 扩展到此存储库中的视频。
$ pip install lumiere-pytorch import torch
from lumiere_pytorch import MPLumiere
from denoising_diffusion_pytorch import KarrasUnet
karras_unet = KarrasUnet (
image_size = 256 ,
dim = 8 ,
channels = 3 ,
dim_max = 768 ,
)
lumiere = MPLumiere (
karras_unet ,
image_size = 256 ,
unet_time_kwarg = 'time' ,
conv_module_names = [
'downs.1' ,
'ups.1' ,
'downs.2' ,
'ups.2' ,
],
attn_module_names = [
'mids.0'
],
upsample_module_names = [
'ups.2' ,
'ups.1' ,
],
downsample_module_names = [
'downs.1' ,
'downs.2'
]
)
noised_video = torch . randn ( 2 , 3 , 8 , 256 , 256 )
time = torch . ones ( 2 ,)
denoised_video = lumiere ( noised_video , time = time )
assert noised_video . shape == denoised_video . shape 添加所有时间层
仅公开用于学习的时间参数,冻结其他所有内容
找出处理时间下采样后时间调节的最佳方法 - 而不是一开始就进行 pytree 转换,可能需要挂钩所有模块并检查批量大小
处理可能具有输出形状(batch, seq, dim)的中间模块
根据 Tero Karras 的结论,即兴设计具有震级保持功能的 4 个模块的变体
在 imagen-pytorch 上测试
研究多重扩散,看看它是否可以变成一些简单的包装器
@inproceedings { BarTal2024LumiereAS ,
title = { Lumiere: A Space-Time Diffusion Model for Video Generation } ,
author = { Omer Bar-Tal and Hila Chefer and Omer Tov and Charles Herrmann and Roni Paiss and Shiran Zada and Ariel Ephrat and Junhwa Hur and Yuanzhen Li and Tomer Michaeli and Oliver Wang and Deqing Sun and Tali Dekel and Inbar Mosseri } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:267095113 }
} @article { Karras2023AnalyzingAI ,
title = { Analyzing and Improving the Training Dynamics of Diffusion Models } ,
author = { Tero Karras and Miika Aittala and Jaakko Lehtinen and Janne Hellsten and Timo Aila and Samuli Laine } ,
journal = { ArXiv } ,
year = { 2023 } ,
volume = { abs/2312.02696 } ,
url = { https://api.semanticscholar.org/CorpusID:265659032 }
}

