MambaTransformer
1.0.0

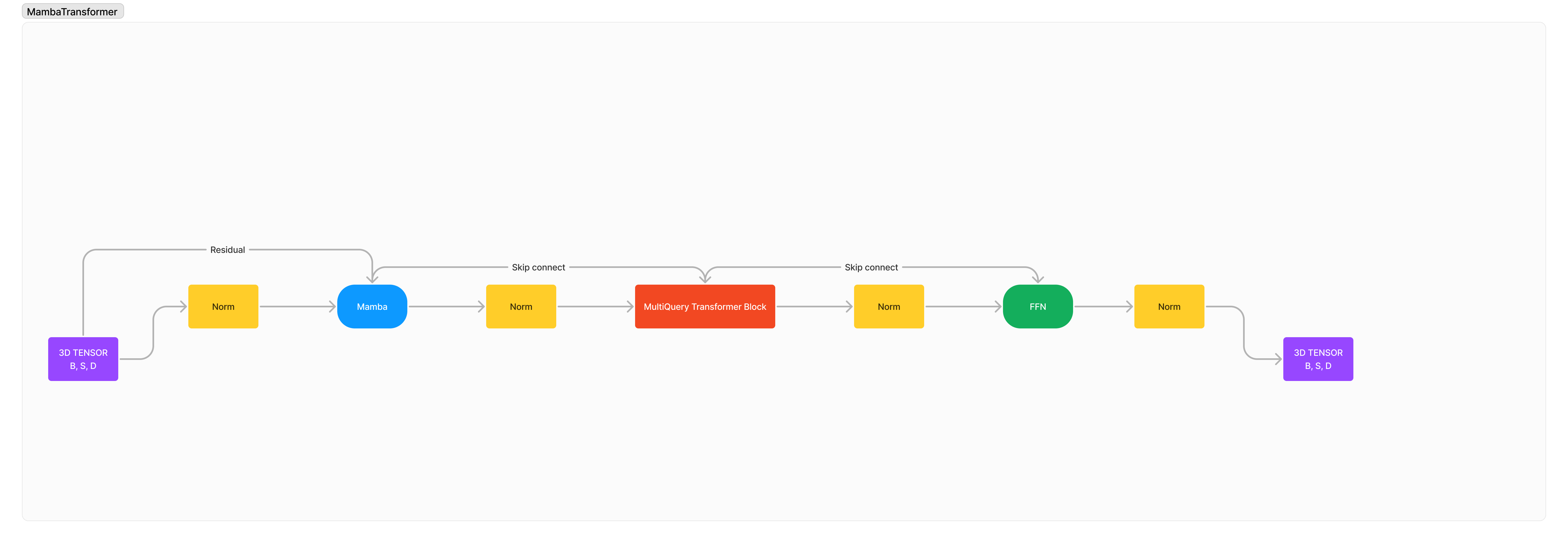
将 Mamba/SSM 与 Transformer 集成以增强长上下文和高质量序列建模。
这是我设计的 100% 新颖的架构,结合了 SSM 和 Attention 的优点和缺点,形成了一种全新的高级架构,其目的是超越我们的旧限制。更快的处理速度、更长的上下文长度、更低的长序列困惑度、增强且卓越的推理,同时保持小而紧凑。
该架构本质上是: x -> norm -> mamba -> norm -> transformer -> norm -> ffn -> norm -> out 。
我添加了许多标准化,因为我相信默认情况下,由于 2 个外部架构相互集成,训练稳定性会严重降低。
pip3 install mambatransformer
import torch
from mamba_transformer import MambaTransformer
# Generate a random tensor of shape (1, 10) with values between 0 and 99
x = torch . randint ( 0 , 100 , ( 1 , 10 ))
# Create an instance of the MambaTransformer model
model = MambaTransformer (
num_tokens = 100 , # Number of tokens in the input sequence
dim = 512 , # Dimension of the model
heads = 8 , # Number of attention heads
depth = 4 , # Number of transformer layers
dim_head = 64 , # Dimension of each attention head
d_state = 512 , # Dimension of the state
dropout = 0.1 , # Dropout rate
ff_mult = 4 , # Multiplier for the feed-forward layer dimension
return_embeddings = False , # Whether to return the embeddings,
transformer_depth = 2 , # Number of transformer blocks
mamba_depth = 10 , # Number of Mamba blocks,
use_linear_attn = True , # Whether to use linear attention
)
# Pass the input tensor through the model and print the output shape
out = model ( x )
print ( out . shape )
# After many training
model . eval ()
# Would you like to train this model? Zeta Corporation offers unmatchable GPU clusters at unbeatable prices, let's partner!
# Tokenizer
model . generate ( text )
麻省理工学院


