toyCarIRL
1.0.0
强化学习(RL)是试错学习的最基本、最直观的形式,它是大多数具有某种思维能力的生物体学习的方式。通常被称为探索学习,这是新生儿学习迈出第一步的方式,即首先采取随机动作,然后慢慢找出导致向前行走运动的动作。
请注意,本文假设您对强化学习框架有很好的了解,请通过这门精彩在线课程 AI_Berkeley 的第 5 周和第 6 周熟悉 RL。
现在我一直问自己的问题是,这种学习的驱动力是什么,是什么迫使智能体以它正在做的方式学习特定的行为。在了解更多关于 RL 的知识后,我想到了奖励的概念,基本上,代理试图以这样的方式选择其行为,即从特定行为中获得的奖励最大化。现在,为了使代理执行不同的行为,必须修改/利用奖励结构。但是假设我们只了解专家的行为,那么我们如何估计环境中特定行为的奖励结构呢?嗯,这就是逆强化学习(IRL)的问题,在给定最优专家策略(实际上假设是最优)的情况下,我们希望确定潜在的奖励结构。
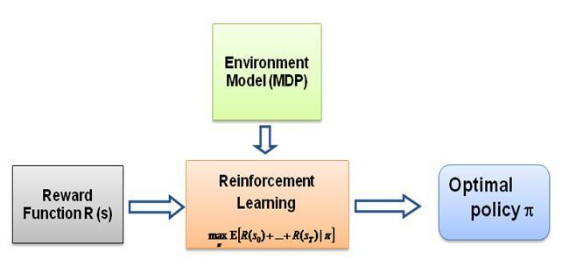
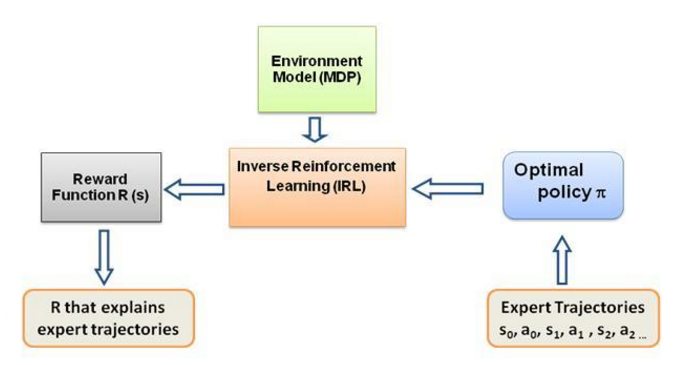
再说一次,这不是一篇关于逆向强化学习的介绍文章,而是关于如何使用/编码逆向强化学习框架来解决您自己的问题的教程,但 IRL 是它的核心,了解它是最重要的首先。 IRL 过去已经被广泛研究,并且已经开发了算法,请浏览论文 Ng 和 Russell,2000,以及 Abbeel 和 Ng,2004 以获取更多信息。
这篇文章采用了 Abbeel 和 Ng,2004 年的算法来解决 IRL 问题。
这里的想法是在充满障碍的 2D 世界中编写一个简单的代理来复制/克隆环境中的不同行为,这些行为是在人类/计算机专家手动给出的专家轨迹的帮助下输入的。这种从专家演示中学习的形式在科学文献中被称为学徒学习,其核心是逆强化学习,我们只是试图找出这些不同行为的不同奖励函数。
总的来说,是的,它们是同一件事,意思是从演示中学习(LfD)。两种方法都从演示中学习,但它们学到的东西不同:
通过逆强化学习的学徒学习将尝试推断老师的目标。换句话说,它将从观察中学习奖励函数,然后可以将其用于强化学习。如果它发现目标是用锤子敲钉子,它就会忽略老师的眨眼和抓挠,因为它们与目标无关。
模仿学习(又名行为克隆)会尝试直接模仿老师。这可以仅通过监督学习来实现。人工智能将尝试复制每一个动作,甚至是不相关的动作,例如眨眼或抓挠,甚至是错误。你也可以在这里使用强化学习,但前提是你有奖励函数。
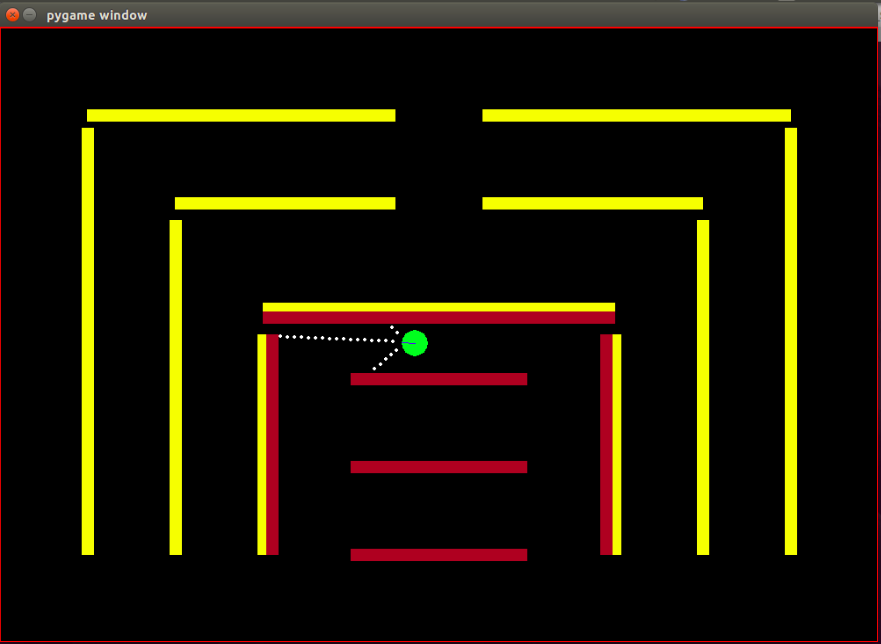
代理:代理是一个绿色小圆圈,其前进方向由蓝线指示。
传感器:代理配备了 3 个距离传感器和颜色传感器,这是代理拥有的有关环境的唯一信息。
状态空间:代理的状态由 8 个可观察的特征组成 -
请注意,进行归一化是为了确保每个可观察的特征值都在 [0,1] 范围内,这是 IRL 算法收敛的奖励的必要条件。
奖励:每帧后的奖励被计算为在相应帧中观察到的特征值的加权线性组合。这里第t帧的奖励r_t是通过权重向量w与第t帧的特征值向量的点积计算出来的,即状态向量phi_t。这样 r_t = w^T x phi_t。
可用动作:对于每个新帧,代理会自动向前迈出一步,可用动作可以将代理向左、向右转动或不执行任何操作(即简单的向前一步),请注意,转动动作也包括向前运动,它不是原地旋转。
障碍:环境由坚硬的墙壁组成,故意涂上不同的颜色。该代理具有颜色感应功能,有助于区分障碍物类型。这样设计环境是为了方便测试IRL算法。
机器人的起始位置(状态)是固定的,因为根据 IRL 算法,所有迭代的起始状态必须相同。
请注意,强化学习算法完全采用了 Matt Harvey 的这篇文章,只做了一些微小的修改,因此谈论我所做的更改是非常有意义的,即使读者对 RL 感到满意,我也强烈建议浏览一下这篇文章是为了了解强化学习是如何发生的。
环境发生了显着变化,智能体不仅能够感知 3 个传感器的距离,还能感知障碍物的颜色,从而能够区分障碍物。此外,代理的尺寸现在更小,其传感点现在更近,以获得更高的分辨率和更好的性能。现在必须将障碍物静态化,以简化测试IRL算法的过程,这很可能会导致数据过度拟合,但我目前并不担心这一点。如上所述,观察集或代理状态已从 3 个增加到 8 个,并且在代理状态中包含了崩溃功能。奖励结构完全改变,奖励现在是这8个特征的加权线性组合,智能体不再在碰撞障碍物时获得-500奖励,而是碰撞的特征值为+1,不碰撞的特征值为0,算法根据专家的行为决定应该为该特征分配什么权重。
正如 Matt 博客中所述,这里的目的不仅仅是教 RL 代理避开障碍物,我的意思是为什么要对奖励结构做出任何假设,让奖励结构完全由专家演示中的算法决定,看看会有什么行为特定的奖励设置达成!
特征或基函数phi_i 基本上是状态中的可观察值。当前问题的特征已在上面的状态空间部分中讨论。我们将 phi(s_t) 定义为所有特征期望 phi_i 的总和,这样:
奖励r_t - 在每个状态 s_t 观察到的这些特征值的线性组合。
策略 pi 的特征期望mu(pi) 是折扣特征值 phi(s_t) 的总和。
策略的特征期望与权重无关,它们仅依赖于运行期间访问的状态(根据策略)以及折扣因子 gamma 0 到 1 之间的数字(例如,在我们的例子中为 0.9)。为了获得策略的特征期望,我们必须与代理一起实时执行策略并记录访问的状态和获得的特征值。
专家策略特征期望或专家的特征期望mu(pi_E)是根据专家行为采取的行动获得的。我们基本上执行此策略并获得功能期望,就像我们执行任何其他策略一样。专家特征期望被赋予 IRL 算法以找到权重,使得与权重相对应的奖励函数类似于专家试图最大化的底层奖励函数(用通常的 RL 语言)。
随机策略特征期望- 执行随机策略并使用获得的特征期望来初始化 IRL。
维护我们在每次迭代后获得的策略功能期望列表。
一开始我们只有 pi^1 -> 随机策略特征期望。
通过凸优化找到 w^1 的第一组权重,该问题类似于 SVM 分类器,它试图给专家特征 expec 一个 +1 标签。和 -1 标签到所有其他策略功能预期。-
这样,
终止条件:
现在,一旦我们在一次优化迭代后获得了权重,即一旦我们获得了一个新的奖励函数,我们就必须学习该奖励函数所产生的策略。这相当于说,找到一个试图最大化所获得的奖励函数的策略。为了找到这个新策略,我们必须使用这个新的奖励函数来训练强化学习算法,并训练它直到 Q 值收敛,以获得策略的正确估计。
当我们学习到一个新的策略后,我们必须在线测试这个策略,以获得这个新策略对应的功能期望。然后,我们将这些新的特征期望添加到我们的特征期望列表中,并继续进行,无需 IRL 算法的下一次迭代,直到收敛。
现在让我们尝试掌握代码。请在此 git 存储库中找到完整的代码。您主要需要担心 3 个文件 -
ManualControl.py - 通过手动移动代理来获取专家的功能期望。运行“python3 manualControl.py”,等待 gui 加载,然后使用箭头键开始移动。赋予它您希望它复制的行为(请注意,您希望它复制的行为对于给定的状态空间应该是合理的)。一个好的技巧是假设你自己代替智能体,并思考你是否能够仅在当前状态空间的情况下区分给定的行为。有关更多详细信息,请参阅源文件。
toy_car_IRL.py - 主文件,这是 IRL 代码所在的位置。让我们一步一步看一下代码 -
{%要点51542f27e97eac1559a00f06b757df1a%}
导入依赖项并定义重要参数,根据需要更改行为。 FRAMES 是您希望 RL 算法运行的帧数。 100K还可以,大约需要2个小时。
{%要点49b602b9a3090773d492310175bb2e3f%}
创建易于使用的 irlAgent 类,该类接受随机和专家行为以及如图所示的其他重要参数。
{%要点bc17c06a07ea3b915827e89f3c13a2ae%}
getRLAgentFE 函数使用强化学习器中的 IRL_helper 来训练新模型,并通过运行该模型 2000 次迭代来获得特征期望。它基本上返回其获得的每组权重 (W) 的特征期望。
{% 要点 ce0ef99adc652c7469f1bc4303a3af41 %}
更新我们保存获得的策略及其各自的 t 值的字典。其中 t = (weights.tanspose)x(expert-newPolicy)。
{% 要点 be55a5d44e5b1ff13dfa68cc96f6b1b1 %}
上面讨论的主要 IRL 算法的实现。 {%要点9faee18596467ee33ac5d91fd0cb675f%}
凸优化在收到新策略时更新权重,基本上为专家策略分配 +1 标签,为所有其他策略分配 -1 标签,并在上述约束下优化权重。要了解有关此优化的更多信息,请访问网站
{%要点30cf6c59b9915054f3cf6d278f8f8a11%}
创建一个 irlAgent 并传递所需的参数,在您希望学习其权重的专家行为类型之间进行选择,然后运行 optimizationWeightFinder() 函数。请注意,我已经获得了红色、黄色和棕色行为的特征期望。算法终止后,您将在“weights-red/yellow/brown.txt”中获得权重列表,其中包含相应选定的行为。现在,要从所有获得的权重中选择最佳可能的行为,请播放saved-models_BEHAVIOR/evaluatedPolicies/目录中保存的模型,模型以以下格式保存: 'saved-models_'+ BEHAVIOR +'/evaluatedPolicies/'+迭代次数+ '-164-150-100-50000-100000' + '.h5' 。基本上,不同的迭代你会得到不同的权重,首先玩模型找出表现最好的模型,然后记下该模型的迭代次数,与该迭代次数对应的权重是让你最接近专家的权重行为。
然后还有一些文件您可能不需要更新/修改,至少对于本文中的内容来说是这样 -
经过大约 10-15 次迭代后,算法在所有 4 种不同的选择行为中收敛,我得到了以下结果:
| 重量 | 我喜欢黄色 | 我爱棕色 | 我爱红色 | 我爱碰撞 |
|---|---|---|---|---|
| w1(左传感器距离) | -0.0880 | -0.2627 | 0.2816 | -0.5892 |
| w2(中间传感器距离) | -0.0624 | 0.0363 | -0.5547 | -0.3672 |
| w3(右传感器距离) | 0.0914 | 0.0931 | -0.2297 | -0.4660 |
| w4(黑色) | -0.0114 | 0.0046 | 0.6824 | -0.0299 |
| W5(黄色) | 0.6690 | -0.1829 | -0.3025 | -0.1528 |
| W6(棕色) | -0.0771 | 0.6987 | 0.0004 | -0.0368 |
| W7(红色) | -0.6650 | -0.5922 | 0.0525 | -0.5239 |
| w8(崩溃) | -0.2897 | -0.2201 | -0.0075 | 0.0256 |
前三个行为中属于碰撞特征的权重被赋予较高的负值,因为这 3 个专家行为不希望智能体碰撞到障碍物。而最后一个行为(即讨厌的机器人)中相同特征的权重是正的,因为专家行为提倡碰撞。
显然,颜色特征的权重与专家行为相关,当需要该颜色时权重较高,否则为相当低/负值以获得独特的行为。
距离特征权重非常模糊(违反直觉),并且很难在权重中找出一些有意义的模式。我唯一想指出的是,在当前设置下甚至可以区分顺时针和逆时针行为,距离特征将携带此信息。
请注意,在设计问题结构时,首先考虑您作为一个人是否能够区分给定行为与当前状态集(观察)的可用性,这一点非常重要。否则,您可能只是强制算法寻找不同的权重,而没有完全提供必要的信息。
如果你真的想进入 IRL,我建议你实际上尝试教代理一种新的行为(你可能必须为此修改环境,因为当前状态集可能的不同行为已经被利用了,好吧至少对我来说是这样)。
安装 Pygame 的依赖项:
sudo apt install mercurial libfreetype6-dev libsdl-dev libsdl-image1.2-dev libsdl-ttf2.0-dev libsmpeg-dev libportmidi-dev libavformat-dev libsdl-mixer1.2-dev libswscale-dev libjpeg-dev
然后安装 Pygame 本身:
pip3 install hg+http://bitbucket.org/pygame/pygame
这是模拟使用的物理引擎。它刚刚经历了相当重要的重写 (v5),因此您需要获取旧的 v4 版本。 v4 是为 Python 2 编写的,因此有几个额外的步骤。
返回您的家或下载并获取 Pymunk 4:
wget https://github.com/viblo/pymunk/archive/pymunk-4.0.0.tar.gz
拆开包装:
tar zxvf pymunk-4.0.0.tar.gz
从 Python 2 更新到 3:
cd pymunk-pymukn-4.0.0/pymunk
2to3 -w *.py
安装它:
cd .. python3 setup.py install
现在返回到克隆reinforcement-learning-car位置,并确保一切都可以与快速python3 learning.py配合使用。如果您看到屏幕上出现一个小点在屏幕上飞来飞去,那么您就可以开始了!
首先,您需要训练一个模型。这会将权重保存到saved-models文件夹中。您可能需要在运行之前创建此文件夹。您可以通过运行以下命令来训练模型:
python3 learning.py
训练模型可能需要 1 小时到 36 小时不等,具体取决于网络的复杂性和样本的大小。但是,它会每 25,000 帧输出一次权重,因此您可以在更短的时间内进入下一步。
编辑playing.py文件以更改要加载的模型的路径名称。对此感到抱歉,我知道它应该是命令行参数。
然后,观看汽车自行绕过障碍物!
python3 playing.py
这就是全部内容了。


