liuli
v0.2.0
简单解释一下:
采集器:监控各自关注的公众号、书籍或者博客源等自定义阅读源,以统一标准格式流入Liuli作为输入源;
处理器:对目标内容进行自定义处理,如基于历史广告数据,利用机器学习实现一个广告分类器自动打标签,或者引入钩子函数在相关节点执行等;
分发器:依靠接口层进行数据请求&响应,为使用者提供个性化配置,然后根据配置自动进行分发,将干净的文章流向微信、钉钉、TG、RSS客户端甚至自建网站;
备份器:将处理后的文章进行备份,如持久化到数据库或者GitHub等。
这样做就实现了干净阅读环境的构建,衍生一下,基于获取的数据,可做的事情有很多,大家不妨发散一下思路。
开发进度看板:
v0.2.0: 实现基础功能,保证常规场景解决方案可应用
v0.3.0: 实现采集器自定义,用户所见即可采集
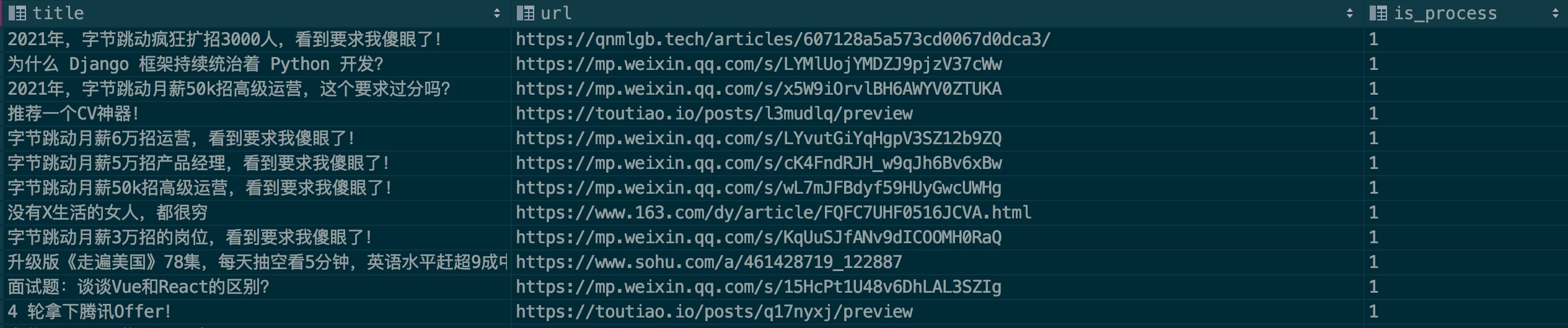
为了提升模型的识别准确率,我希望大家能尽力贡献一些广告样本,请看样本文件:.files/datasets/ads.csv,我设定格式如下:
| title | url | is_process |
|---|---|---|
| 广告文章标题 | 广告文章连接 | 0 |
字段说明:
title:文章标题
url:文章链接,如果微信文章想、请先验证是否失效
is_process:表示是否进行样本处理,默认填0即可
来个实例:
一般广告会重复在多个公众号投放,填写的时候麻烦查一下是否存在此条记录,希望大家能一起合力贡献,亲,来个 PR 贡献你的力量吧!
感谢以下开源项目:
Flask: web框架
Vue: 渐进式JavaScript框架
Ruia: 异步爬虫框架(自研自用)
playwright: 使用浏览器进行数据抓取
以上仅列出比较核心的开源依赖,更多第三方依赖请见Pipfile文件。
您任何PR都是对Liuli项目的大力支持,非常感谢以下开发者的贡献(排名不分先后):
欢迎一起交流(关注入群):


