存储库由在Pytorch实施并在MNIST数据集中培训的VQ-VAE组成。
VQ-VAE遵循与变量自动编码器(VAE)背后相同的基本概念。 VQ-VAE使用离散的潜在嵌入对于变量自动编码器,即z(潜在向量)的每个维度是一个离散的整数,而不是编码输入时通常使用的连续正态分布。
VAE由3个部分组成:
好吧,您可能会询问VQ-VAE带来的差异。让我们列出它们:
许多重要的现实对象是离散的。例如,在图像中,我们可能有“猫”,“汽车”等类别的类别,而在这些类别之间插入可能是没有意义的。离散表示也更容易建模。
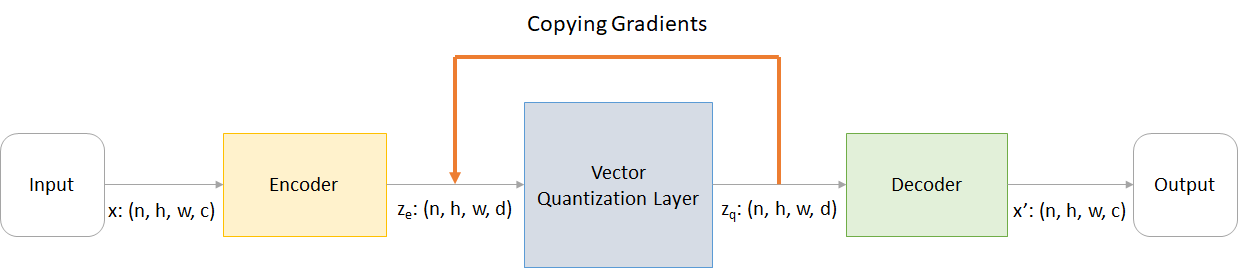
在哪里:
n :批次大小h :图像高度w :图像宽度c :输入图像中的通道数d :隐藏状态处的频道数量这是VQ-VAE网络工作的简要概述:
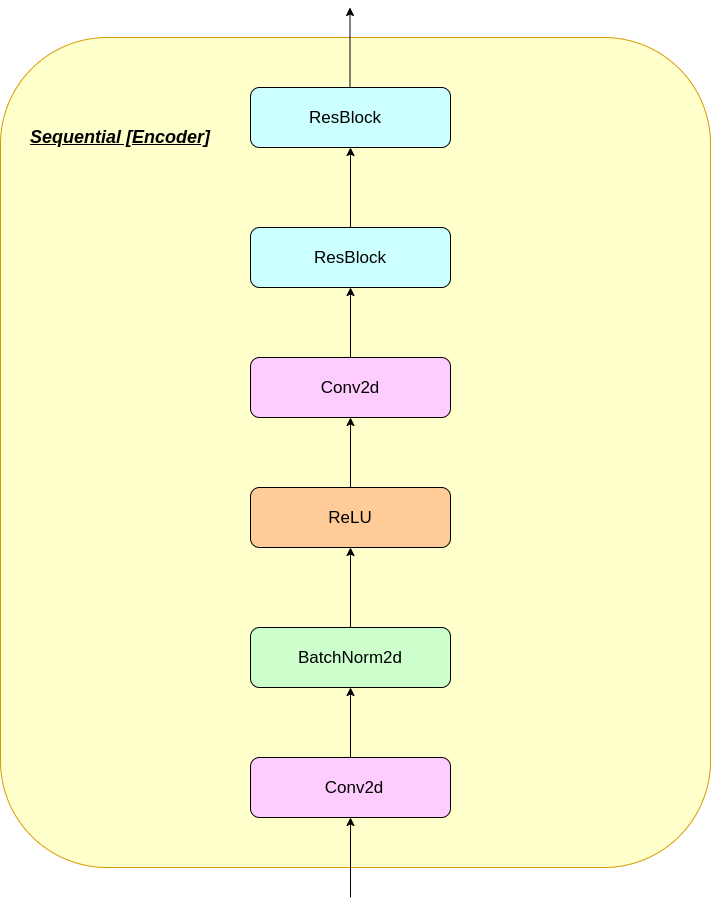
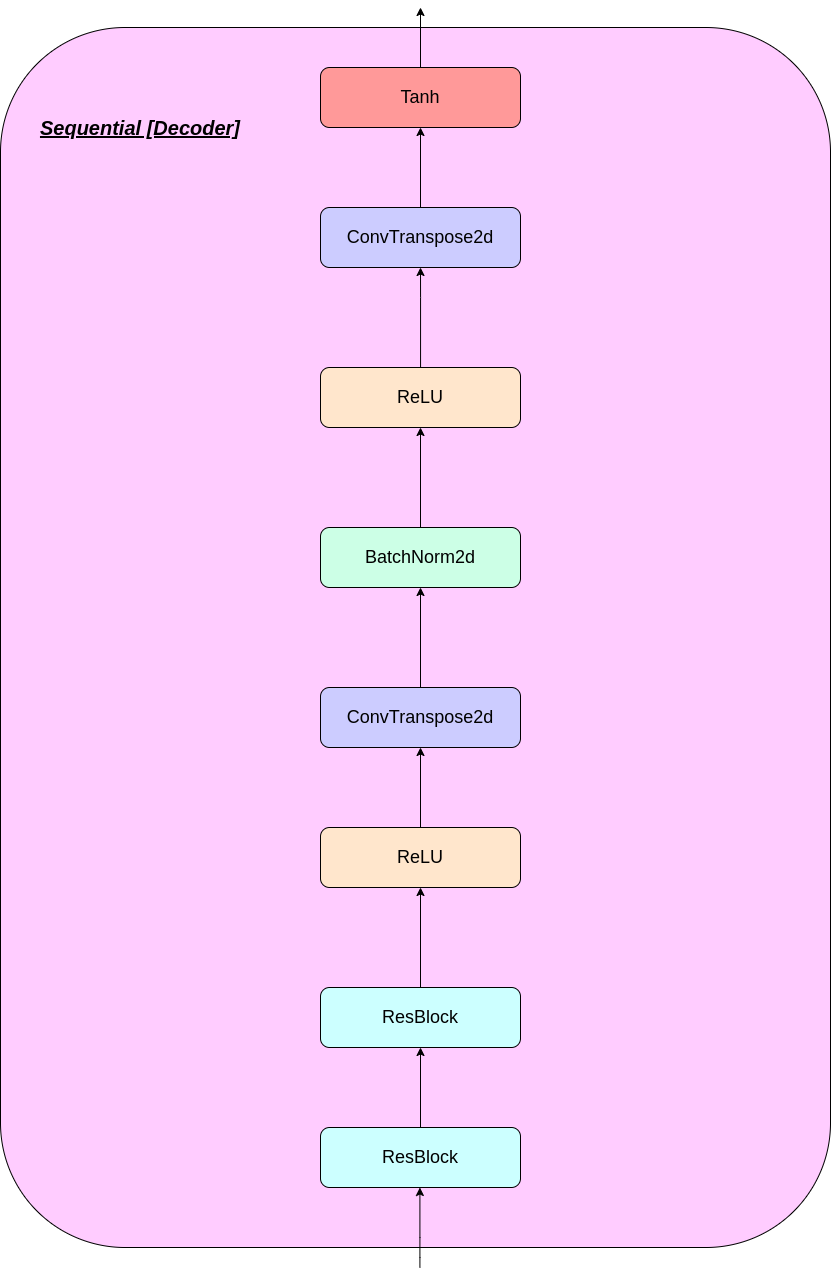
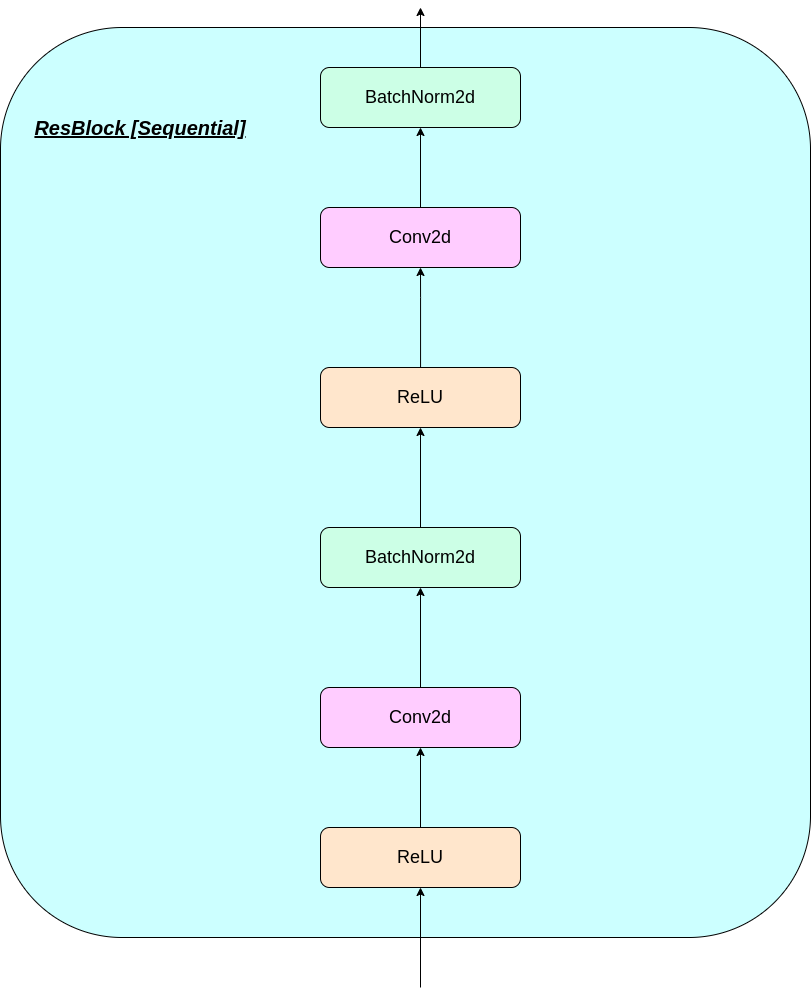
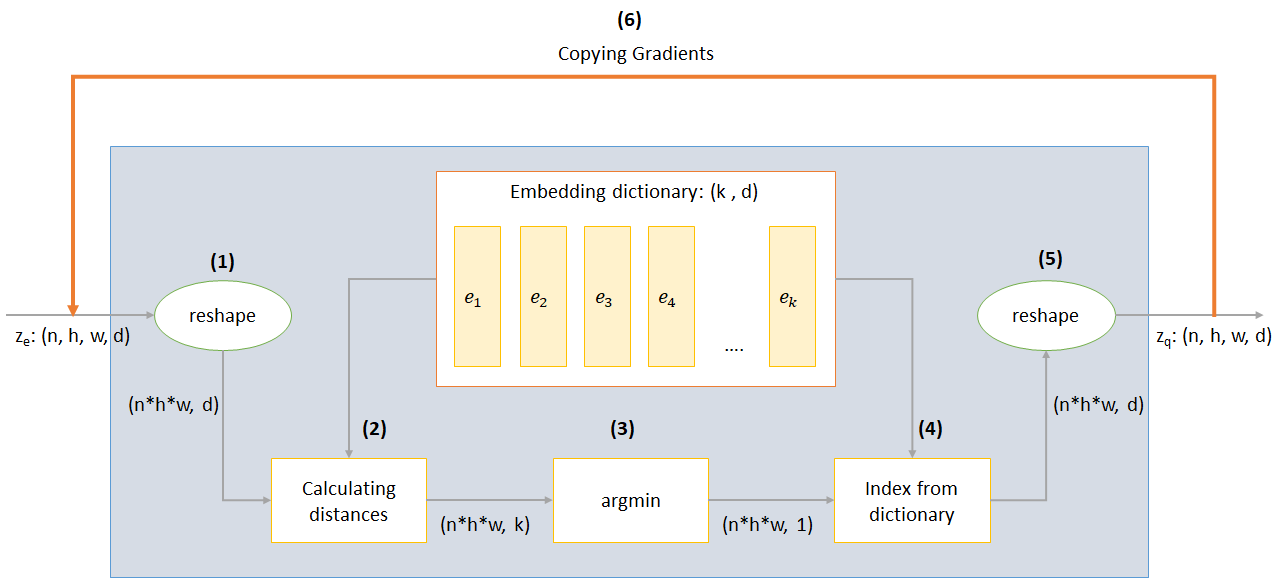
VQ层的工作可以用六个步骤来解释:图中的编号:
VQ-VAE使用3个损失来计算训练期间的总损失:
重建损失:将解码器和编码器优化为VAE,即输入图像和重建之间的差异:
reconstruction_loss = -log( p(x|z_q) )
代码书丢失:由于梯度绕过嵌入嵌入,使用L2错误将嵌入向量E_I移至编码器输出的词典学习算法。
codebook_loss = ‖ sg[z_e(x)]− e ‖^2
(SG表示停止梯度操作员,这意味着没有梯度流过任何应用的梯度)
承诺损失:由于嵌入空间的体积是无尺寸的,因此如果嵌入E_I训练不如Encoder参数训练,则可以任意增长,因此添加了承诺损失以确保编码器承诺嵌入嵌入。
commitment_loss = β‖ z_e(x)− sg[e] ‖^2
(β是一种超参数,可以控制我们要与其他组件相比,要权衡承诺损失的程度)
您可以通过在CMD提示中运行以下操作来下载回购或克隆
https://github.com/praeclarumjj3/VQ-VAE-on-MNIST.git
您可以通过以下命令(在Google Colab中)从头开始训练模型
! python3 VQ-VAE.py --output-folder [NAME_OF_OUTPUT_FOLDER] --data-folder [PATH_TO_MNIST_dataset] --device ['cpu' or 'cuda' ] --hidden-size [SIZE] --k [NUMBER] --batch-size [BATCH_SIZE] --num_epoch [NUMBER_OF_EPOCHS] --lr [LEARNING_RATE] --beta [VALUE] --num-workers [NUMBER_OF_WORKERS]
output-folder - 数据文件夹的名称data-folder - 数据文件夹的名称device - 设置设备(CPU或CUDA,默认:CPU)hidden-size - 潜在向量的大小(默认:40)k潜在向量的数量(默认值:512)batch-size - 批量尺寸(默认:128)num-epochs - 时期数(默认值:10)lr亚当优化器的学习率(默认:2E -4)beta承诺损失的贡献,在0.1到2.0之间(默认:1.0)num-workers - 轨迹采样的工人数量(默认:cpu_count() - 1)该程序会自动下载MNIST数据集并将其保存到PATH_TO_MNIST_dataset文件夹中(您需要创建此文件夹)。这只会发生一次。
它还创建了一个logs文件夹和models文件夹,并且内部创建了一个文件夹,其中传递的名称分别保存了内部的日志和模型检查点。
要从单位高斯运行以下命令(在Google colab中)随机生成z采样的新图像:
! python3 generate.py --model [SAVED_MODEL_FILENAME] --input [MNIST_or_random] --device ['cpu' or 'cuda' ] --hidden-size [SIZE] --k [NUMBER] --filename [SAVING_NAME]
model - 包含模型的文件名input -MNIST或随机device - 设置设备(CPU或CUDA,默认:CPU)hidden-size - 潜在向量的大小(默认:40)k潜在向量的数量(默认值:512)filename - 要保存哪个文件的名称它生成了10*10个图像网格,这些图像保存在名为generatedImages文件夹中。
您可以通过从model.txt中的链接下载预先训练的模型。
存储库包含以下文件
modules.py包含用于制作模型的不同模块VQ-VAE.py包含训练我们的VQ-VAE模型的功能和代码vector_quantizer.py此文件中定义了向量量化类generate-py从预训练的模型中生成新图像model.txt包含指向预训练模型的链接README.md redme概述了仓库references.txtreadme_images有多种图像的读数MNIST包含Zipped MNIST数据集(尽管需要在需要时自动下载)Training track for VQ-VAE.txt - 包含在我们的VQ-VAE模型训练期间的损失值logs_VQ-VAE包含我们VQ-VAE模型的拉链张板日志(程序自动创建)testers.py包含一些测试我们定义的模块的功能命令运行张量板(在Google Colab中):
%load_ext tensorboard
%tensordboard --logdir [path_to_folder_with_logs]
训练图像
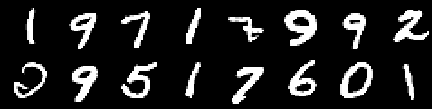
来自0个时代的图像

来自第二个时期的图像
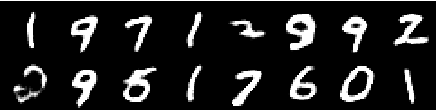
来自第四个时代的图像
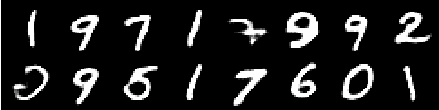
来自6个时代的图像
来自8个时代的图像
来自第10个时代的图像
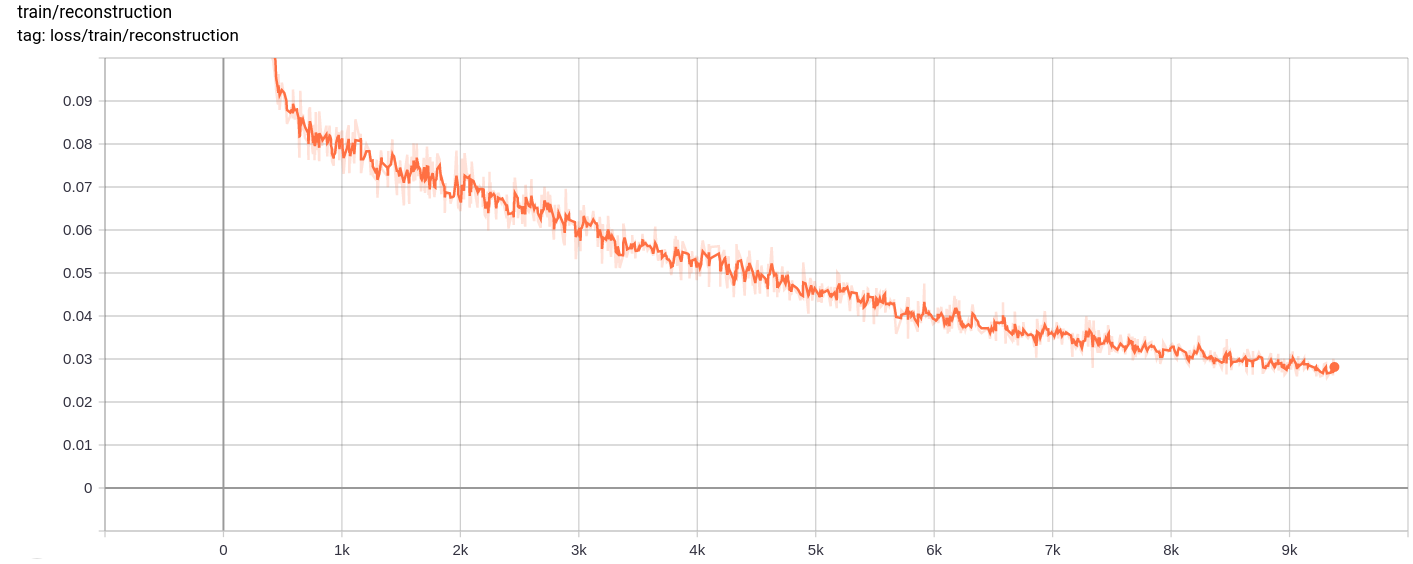
重建不断改进,最后几乎类似于训练_SET图像,这反映在损失值(在Training track for VQ-VAE.txt )。
重建损失
量化损失
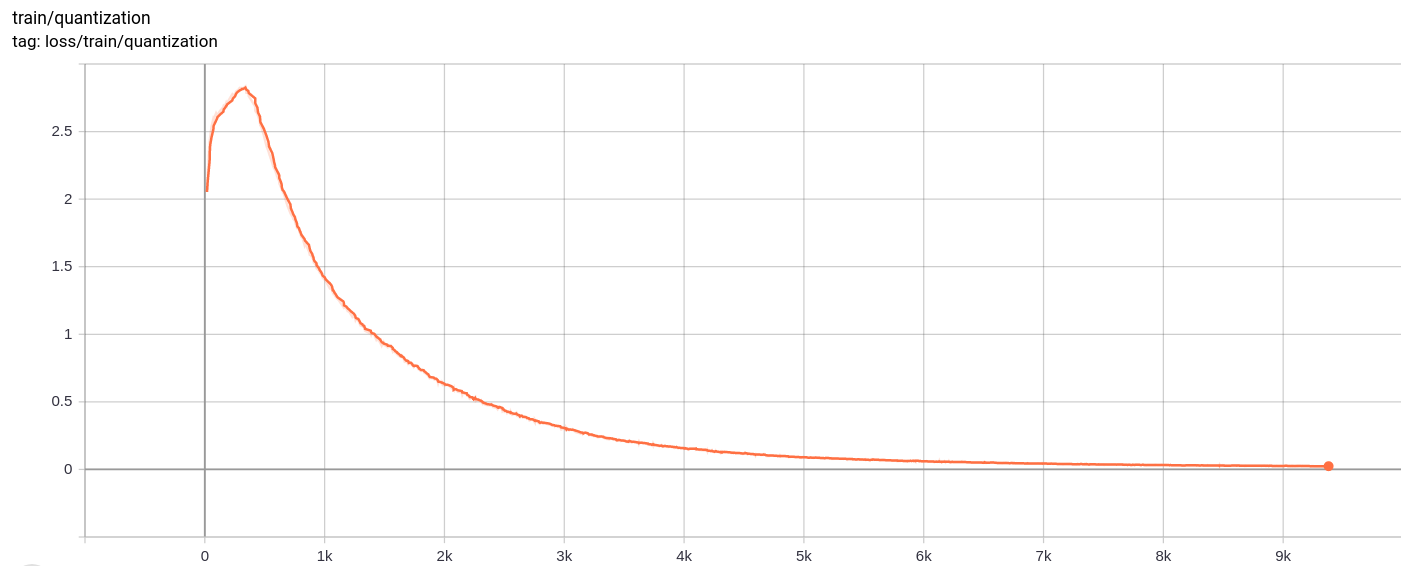
total_loss
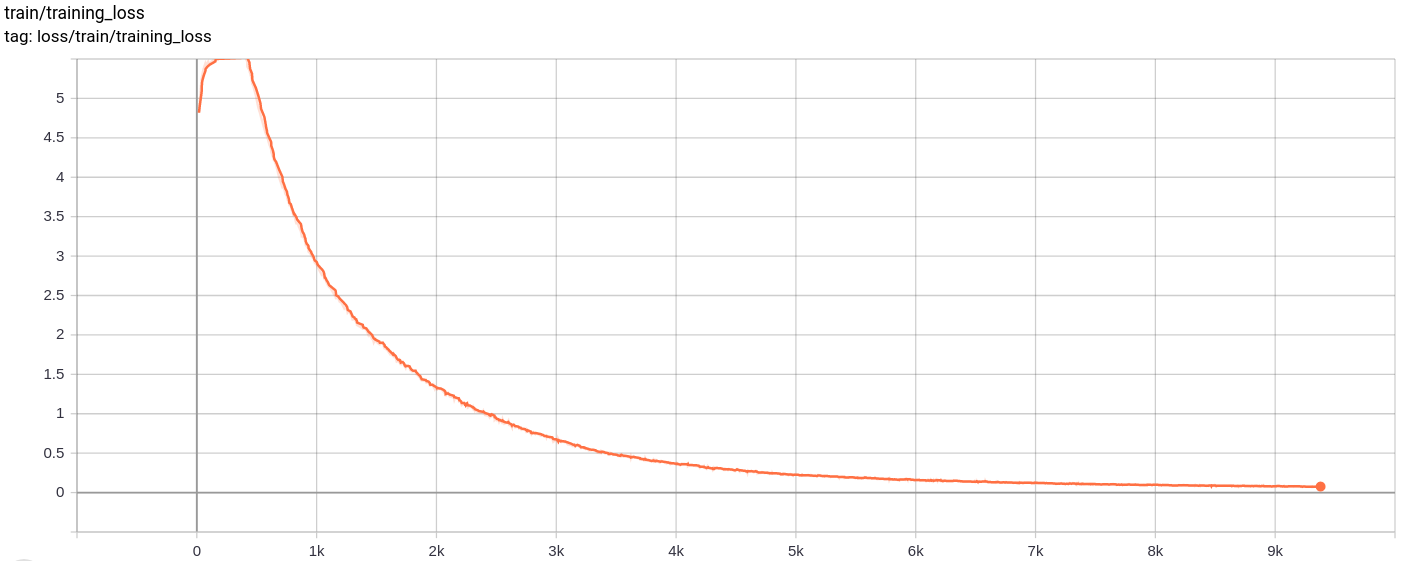
按预期,总损失,重建损失和量化损失均匀减少。
testing_loss
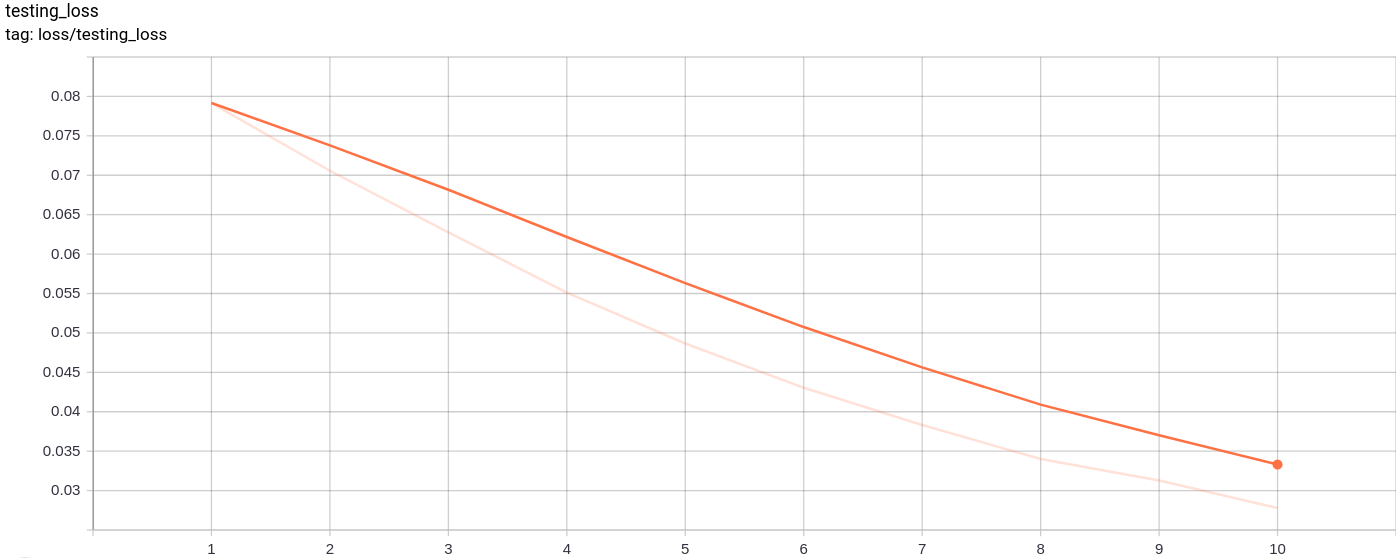
测试损失按预期均匀减少。
以下图像网格是在将MNIST图像作为输入传递后生成的:

这一代很好。
通过从单位高斯作为输入的AZ采样后,生成以下图像网格,然后通过解码器。


图像看起来并不完美。调整潜在空间的尺寸,嵌入向量的数量等可以帮助生成更好的随机图像。
该模型在Google Colab上接受了10个时期的培训,其中批量尺寸为128。
训练后,模型能够很好地重建输入图像,并且还能够生成新图像,尽管生成的图像不太好。
训练以及测试损失也几乎单调地减少。
我观察到,训练模型为10-20个时期训练产生了结果,这表明模型中可能有过度拟合的迹象。另外,我尝试了LatedNT空间的不同维度,最终dimension = 40产生了最佳结果。最佳维度范围是16-42之间。
以下资源有助于使这个存储库


