使用神经网络反转矩阵。
反转矩阵对神经网络提出了独特的挑战,这主要是由于执行精确的算术操作(例如乘法和激活分裂)的固有局限性。传统的密集网络通常需要这些任务的帮助,因为它们没有明确设计来处理矩阵反转中涉及的复杂性。用简单密集的神经网络进行的实验显示出了很大的困难,从而实现了准确的矩阵反转。尽管进行了各种优化架构和培训过程的尝试,但结果通常需要改进。但是,过渡到更复杂的体系结构(7层剩余网络(RESNET))会导致性能明显改善。
Resnet架构以其通过残留连接学习深度表示的能力而闻名,已证明有效地解决了矩阵反转。有了数百万个参数,该网络可以在更简单的模型无法使用的数据中捕获复杂的模式。但是,这种复杂性是有效的:有效概括需要大量的培训数据。
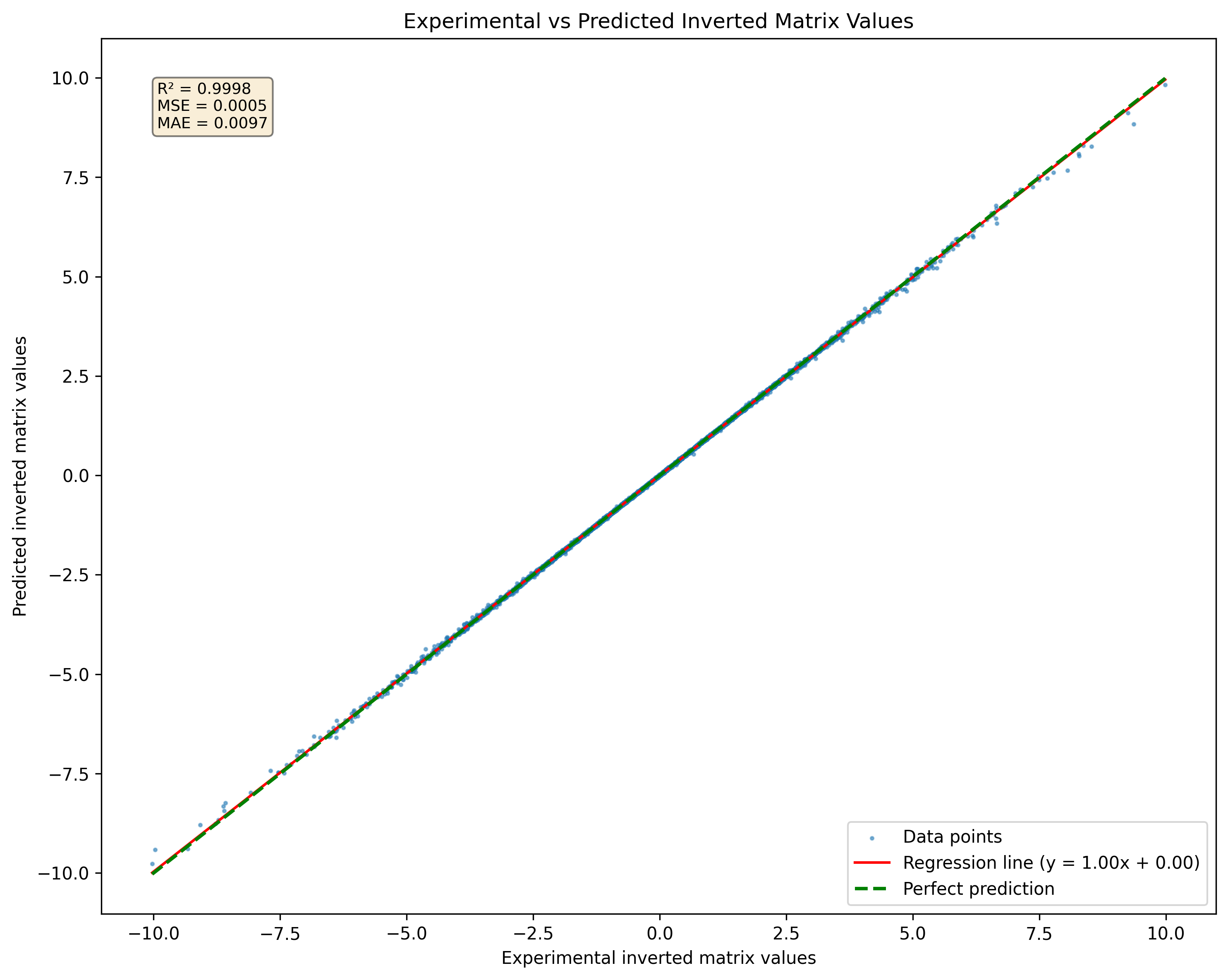 图1:神经网络的可视化预测数据集中从未见过的一组矩阵3x3的倒置矩阵
图1:神经网络的可视化预测数据集中从未见过的一组矩阵3x3的倒置矩阵
为了评估神经网络在预测矩阵反转时的性能,采用了特定的损失函数:
在此等式中:
目的是最大程度地减少身份矩阵与原始矩阵的乘积及其预测倒数之间的差异。该损失函数有效地衡量了预测的逆向准确性的距离。
另外,如果
此损失功能比传统损失函数具有不同的优势,例如平方误差(MSE)或平均绝对误差(MAE)。
反转精度的直接测量矩阵反转的主要目标是确保矩阵的乘积及其逆产生标识矩阵。损耗函数通过测量与身份矩阵的偏差直接捕获了这一要求。相反,MSE和MAE专注于预测值与真实值之间的差异,而无需明确解决矩阵反转的基本属性。
通过使用评估乘积AA -1AA -1与II的损失函数来强调结构完整性,它强调维持所涉及的矩阵的结构完整性。这在保留线性关系至关重要的应用中尤其重要。传统的损失功能(例如MSE和MAE)无法解释这一结构性方面,可能导致解决方案最小化误差但无法满足矩阵反转的数学要求。
适用于非单个矩阵的损失函数固有地假设倒置的矩阵是非单星的(即,可逆的)。在存在奇异矩阵的情况下,传统的损失功能可能会产生误导性结果,因为它们不能解释不可能获得有效的逆向。提出的损失函数突出了这种局限性,通过尝试倒入奇异矩阵时会产生较大的错误。
当使用神经网络进行基质反演时,一个重要的局限性是它们无法有效地处理奇异矩阵。单数矩阵没有逆;因此,神经网络试图预测此类矩阵逆的任何尝试都会产生不正确的结果。在实践中,如果在训练或推理过程中呈现一个单数矩阵,则网络仍可能会输出结果,但是此输出将无效或有意义。该限制强调了确保训练数据尽可能由非单明性矩阵组成的重要性。
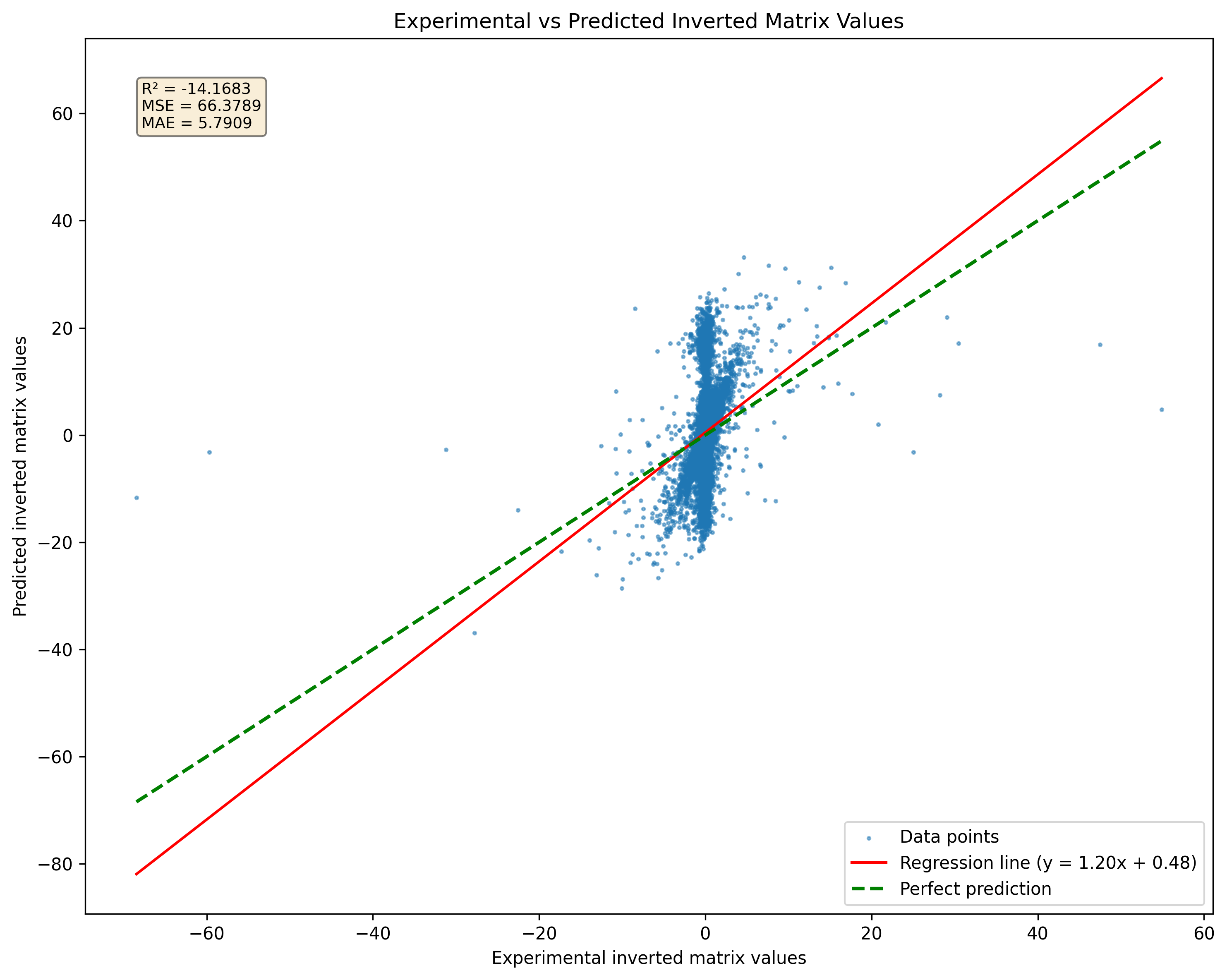 图2:奇异矩阵与伪引导的模型预测的比较。请注意,无论基质奇异性如何,该模型都会产生结果。
图2:奇异矩阵与伪引导的模型预测的比较。请注意,无论基质奇异性如何,该模型都会产生结果。
研究表明,重新网络模型可以记住大量样品而不会明显丧失准确性。但是,将数据集大小提高到1000万个样本可能会导致严重的过度拟合。尽管数据量大量,但这种过度拟合仍会发生,这突显了仅增加数据集大小并不能保证改进复杂模型的概括。为了应对这一挑战,可以采用连续的数据生成策略。可以在创建的情况下即时生成样品并将其馈送到网络中,而不是依靠静态数据集。这种方法对于缓解过度拟合至关重要,不仅提供了各种培训示例,而且还确保该模型暴露于不断发展的数据集中。
总而言之,尽管由于算术操作的局限性,矩阵反转对神经网络固有的挑战,但利用Resnet等高级体系结构可以产生更好的结果。但是,必须仔细考虑数据要求和过度适合风险。连续生成培训样本可以增强模型的学习过程并提高矩阵反转任务中的性能。该版本在讨论培训矩阵反转的神经网络的挑战和策略的同时保持了非个人化的语气。
DeepMatrixInversion根据LGPLV3许可证分配
要了解更多详细信息,请阅读文件“许可”或转到“ http://www.gnu.org/licenses/lgpl-3.0.html”
DeepMatrixInversion目前是Giuseppe Marco Randazzo的财产。
要安装DeepMatrixInversion存储库,您可以在下面使用诗歌,PIP或PIPX之间进行选择,这是两种方法的说明。
git clone https://github.com/gmrandazzo/DeepMatrixInversion.git
cd DeepMatrixInversion
python3 -m venv .venv
. .venv/bin/activate
pip install poetry
poetry install
这将使用所有必要的软件包来设置您的环境,以运行DeepMatrixInversion。
创建虚拟环境并使用PIP安装Deppmatrixinversion
python3 -m venv .venv
. .venv/bin/activate
pip install git+https://github.com/gmrandazzo/DeepMatrixInversion.git
如果您希望使用PIPX,该PIPX允许您在隔离环境中安装Python应用程序,请按照以下步骤进行操作:
python3 -m pip install --user pipx
apt-get install pipx
brew install pipx
sudo dnf install pipx
PIPX安装git+https://github.com/gmrandazzo/deepmatrixinversion.git
要训练可以执行矩阵倒置的模型,您将使用dmxtrain命令。此命令使您可以指定控制训练过程的各种参数,例如矩阵的大小,值范围和训练持续时间。
dmxtrain --msize < matrix_size > --rmin < min_value > --rmax < max_value > --epochs < number_of_epochs > --batch_size < size_of_batches > --n_repeats < number_of_repeats > --mout < output_model_path > dmxtrain --msize --rmin -1 --rmax 1 --epochs 5000 --batch_size 1024 --n_repeats 3 --mout ./Model_3x3
--msize <matrix_size>: Specifies the size of the square matrices to be generated for training. For example, 3 for 3x3 matrices.
--rmin <min_value>: Sets the minimum value for the random elements in the matrices. For instance, -1 will allow negative values.
--rmax <max_value>: Sets the maximum value for the random elements in the matrices. For example, 1 will limit values to a maximum of 1.
--epochs <number_of_epochs>: Defines how many epochs (complete passes through the training dataset) to run during training. A higher number typically leads to better performance; in this case, 5000.
--batch_size <size_of_batches>: Determines how many samples are processed before the model is updated. A batch size of 1024 means that 1024 samples are used in each iteration.
--n_repeats <number_of_repeats>: Indicates how many times to repeat the training process with different random seeds or initializations. This can help ensure robustness; for instance, repeating 3 times.
--mout <output_model_path>: Specifies where to save the trained model. In this example, it saves to ./Model_3x3.
训练模型后,您可以使用它在新输入矩阵上执行矩阵反转。推断的命令是DMXINVERT,它采用输入矩阵并输出其逆。
警告:DMXINVERT可以将比用于通过Sherman-Morrison-Woodbury矩阵块反转公式训练模型的矩阵更大。此功能仅适用于矩阵的块大小可以除以模型训练块大小而无需提醒。该功能是高度实验性的,可能需要修改。
dmxinvert --inputmx <input_matrix_file> --inverseout <output_csv_file> --model <model_path>
dmxinvert --inputmx input_matrix.csv --inverseout output_inverse.csv --model ./Model_3x3_*
--inputmx <input_matrix_file>: Specifies the path to the input matrix file that you want to invert. This file should contain a valid matrix format (e.g., CSV).
--inverseout <output_csv_file>: Indicates where to save the resulting inverted matrix. The output will be saved in CSV format.
--model <model_path>: Provides the path to the trained model that will be used for performing the inversion.
生成具有输入矩阵的人工数据集,并倒出输出倒置DMX DMXDATASETGENERATOR
dmxdatasetgenerator 3 10 -1 1 test_3x3_range_-1+1
这将生成10个尺寸3x3的矩阵,数字在-1至+1范围内。
dmxdatasetgenerator [matrix size] [number of samples] [range min] [range max] [outname_prefix]
然后可以使用DMXDATASETVERIFY验证数据集
dmxdatasetverify test_3x3_range_-1+1_matrices_3x3.mx test_3x3_range_-1+1_matrices_inverted_3x3.mx invertible
Dataset valid.
dmxdatasetverify [dataset matrix to invert] [dataset matrix inverted] [type: invertible or singular]
输入矩阵文件的格式应如下:
0.24077047370124594,-0.5012474139608847,-0.5409542929032876
-0.6257864520097793,-0.030705148203584942,-0.13723920334288975
-0.48095686716222064,0.19220406568380666,-0.34750000491973854
END
0.4575368007107925,0.9627977617090073,-0.4115240560547333
0.5191433428806012,0.9391491187187144,-0.000952683255491138
-0.17757763984424968,-0.7696584771443977,-0.9619759413623306
END
-0.49823271153034154,0.31993947803488587,0.9380291202366384
0.443652116558352,0.16745965310481048,-0.267270356721347
0.7075720067281346,-0.3310912886946993,-0.12013367141105102
END
每个数字的块代表一个单独的矩阵,然后是指示该矩阵末端的末端标记。


