
GFT的官方实施,GFT是图表上的跨域跨任务基础模型。徽标由dall·e 3生成。
由Zehong Wang,Zheyuan Zhang,Nitesh V Chawla,Chuxu Zhang和Yanfang Ye撰写。
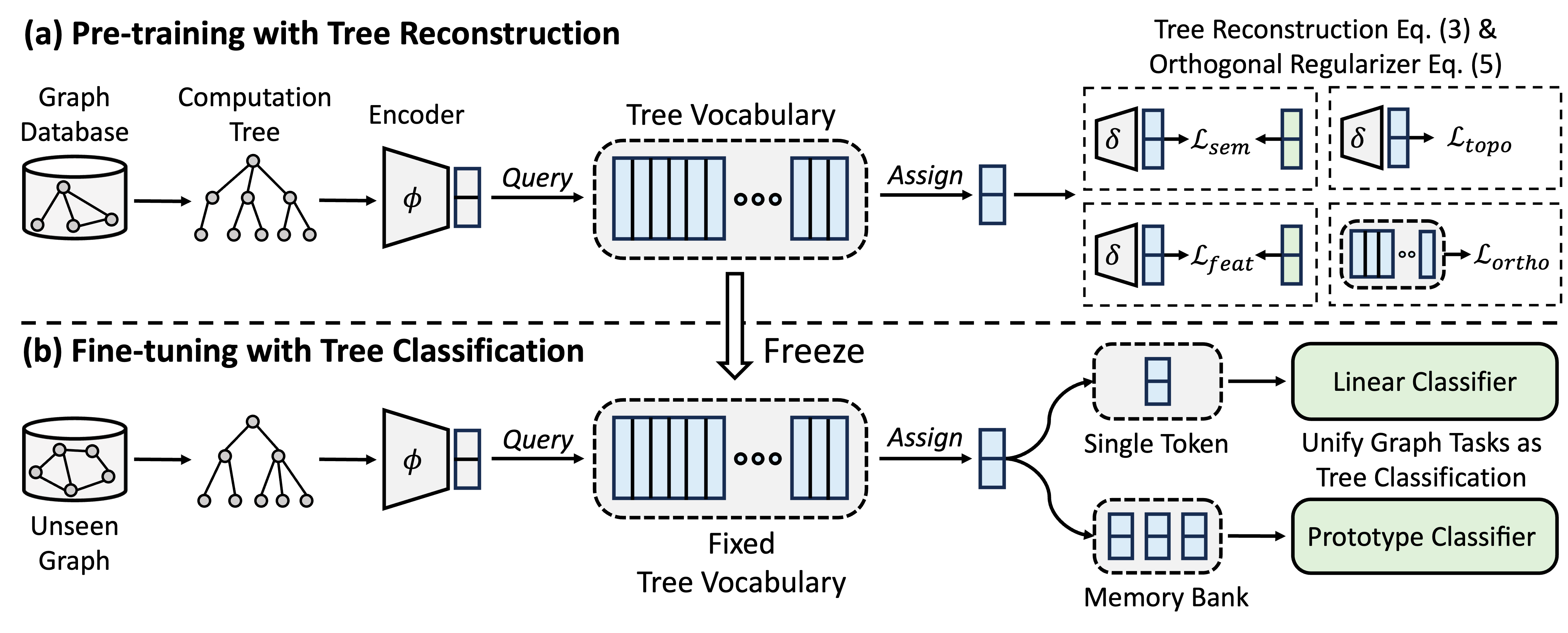
GFT是一种跨域和交叉任务图基础模型,它将计算树视为可转移的模式,以获得可转移的树词汇。此外,GFT提供了一个统一的框架,以使与图形相关的任务与单个图形模型(例如,GNN)相结合,以共同处理节点级别,边缘级别和图形级任务。
在预训练期间,该模型通过树重建任务编码从图数据库中的通用知识到树词汇。在微调中,将学习的树词汇应用于将与图形相关的任务统一为树格分类任务,从而将所获得的常识调整为特定任务。
您可以使用conda安装环境。请运行以下脚本。我们在单个A40 48G GPU上运行所有实验,但是具有24G内存的GPU足以处理所有具有迷你批次的数据集。
conda env create -f environment.yml
conda activate GFT
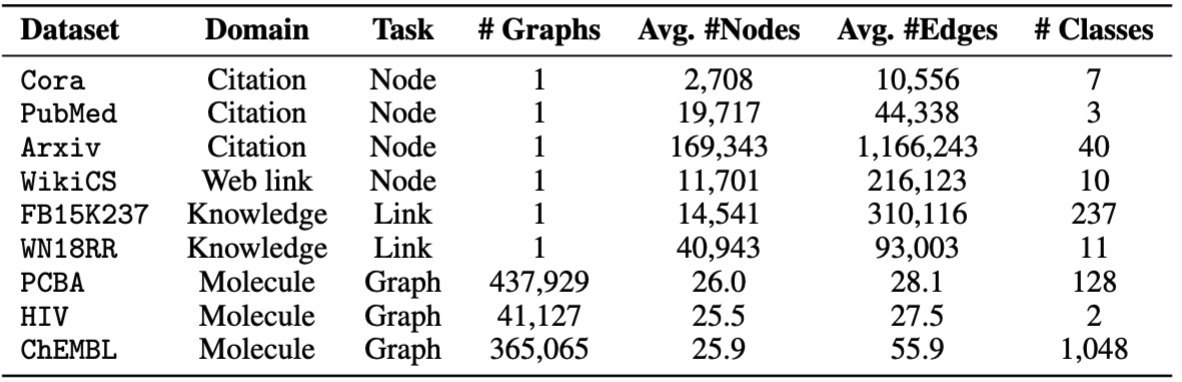
我们使用OFA提供的数据集。您可以运行pretrain.py以自动下载数据集,默认情况下将下载到/data文件夹。管道将通过将文本描述转换为文本嵌入来自动预处理数据集。
另外,您可以下载我们的预处理数据集并在/data文件夹上解压缩。
GFT代码以文件夹/GFT表示。结构如下。
└── GFT
├── pretrain.py
├── finetune.py
├── dataset
│ ├── ...
│ └── process_datasets.py
├── model
│ ├── encoder.py
│ ├── vq.py
│ ├── pt_model.py
│ └── ft_model.py
├── task
│ ├── node.py
│ ├── link.py
│ └── graph.py
└── utils
├── args.py
├── loader.py
└── ...
您可以在各种图形上进行预处理和finetune.py进行pretrain.py 。
为了重现结果,我们分别在config/pretrain.yaml和config/finetune.yaml中提供了详细的超参数用于预处理和填充。为了利用默认的超参数,我们为预处理和Finetune提供了一个命令--use_params 。
# Pretraining with default hyper-parameters
python GFT/pretrain.py --use_params
# Finetuning on Cora with default hyper-parameters
python GFT/finetune.py --use_params --dataset cora
# Few-shot learning on Cora with default hyper-parameters
python GFT/finetune.py --use_params --dataset cora --setting few_shot
对于芬口,我们提供八个数据集,包括cora , pubmed , wikics , arxiv , WN18RR , FB15K237 , chemhiv和chempcba 。
另外,您可以运行脚本以重现实验。
# Pretraining with default hyper-parameters
sh script/pretrain.sh
# Finetuning on all datasets with default hyper-parameters
sh script/finetune.sh
# Few-shot learning on all datasets with default hyper-parameters
sh script/few_shot.sh
注意:验证的模型将存储在ckpts/pretrain_model/默认情况下。
# The basic command for pretraining GFT
python GFT/pretrain.py
当您运行pretrain.py时,您可以自定义预处理数据集和超参数。
您可以使用--pretrain_dataset (或--pt_data )设置使用的预处理数据集和相应的权重。预定义的数据配置位于config/pt_data.yaml中,具有以下结构。
all:
cora: 5
pubmed: 5
arxiv: 5
wikics: 5
WN18RR: 5
FB15K237: 10
chemhiv: 1
chemblpre: 0.1
chempcba: 0.1
...
在上面的情况下, all内容都是设置的名称,这意味着所有数据集都在预处理中使用。对于每个数据集,都有一个键值对,其中键是数据集名称,值是采样权重。例如, cora: 5表示cora数据集将在单个时期中进行5次采样。您可以设计自己的数据集组合,以预处理GFT。
您可以通过更改编码器的超参数,向量量化,模型训练来自定义训练阶段。
--pretrain_dataset :指示预处理数据集。与上述相同。--use_params :使用预定义的超参数。--seed :用于预处理的种子。--hidden_dim :GNNS隐藏层中的尺寸。--num_layers :GNN层。--activation :激活函数。--backbone :骨干GNN。--normalize :归一化层。--dropout :GNN层的辍学。--code_dim :词汇中每个代码的维度。--codebook_size :词汇中的代码数。--codebook_head :代码书的头数。如果数字大于1,则将共同使用多个词汇。--codebook_decay :代码的衰减率。--commit_weight :承诺术语的重量。--pretrain_epochs :时期的数量。--pretrain_lr :学习率。--pretrain_weight_decay :L2正常器的重量。--pretrain_batch_size :批处理大小。--feat_p :功能损坏率。--edge_p :边缘/结构损坏率。--topo_recon_ratio :边缘的比率应重建。--feat_lambda :特征损失的重量。--topo_lambda :拓扑损失的重量。--topo_sem_lambda :重建边缘特征中拓扑损失的重量。--sem_lambda :语义损失的重量。--sem_encoder_decay :语义编码器的动量更新速率。 # The basic command for adapting GFT on downstream tasks via finetuning.
python GFT/finetune.py
您可以设置--dataset指示下游数据集,以及--use_params为每个数据集使用预定义的超参数。您可以指出的其他超参数如下。
对于具有1个预定义分裂的图形,您可以设置--repeat进行多个实验。
--hidden_dim :GNNS隐藏层中的尺寸。--num_layers :GNN层。--activation :激活函数。--backbone :骨干GNN。--normalize :归一化层。--dropout :GNN层的辍学。--code_dim :词汇中每个代码的维度。--codebook_size :词汇中的代码数。--codebook_head :代码书的头数。如果数字大于1,则将共同使用多个词汇。--codebook_decay :代码的衰减率。--commit_weight :承诺术语的重量。--finetune_epochs :时代的数量。--finetune_lr :学习率。--early_stop :最大早期停止时期。--batch_size :如果设置为0,请进行完整的图形训练。--lambda_proto :芬特列中原型分类器的重量。
--lambda_act :填充中线性分类器的重量。
--trade_off :使用Prototype Classier或使用线性分类器进行推理之间的权衡。
您可以添加--no_lin_clf或--no_proto_clf分别避免使用线性分类器或原型分类器。请注意,这两个术语是冲突,因为您必须使用至少一个分类器。
# The basic command for adaptation GFT on downstream tasks via few-shot learning.
python GFT/finetune.py --setting few_shot
您可以设置--dataset指示下游数据集,以及--use_params为每个数据集使用预定义的超参数。您可以指出的其他超参数如下。
专门用于几次学习的超参数是
--n_train :用于对模型进行填充的每课的培训实例数。请注意,小n_train实现了理想的性能--n_task :采样任务的数量。--n_way :方法数。--n_query :以每条方式设置的查询大小。--n_shot :支撑设置的大小。--hidden_dim :GNNS隐藏层中的尺寸。--num_layers :GNN层。--activation :激活函数。--backbone :骨干GNN。--normalize :归一化层。--dropout :GNN层的辍学。--code_dim :词汇中每个代码的维度。--codebook_size :词汇中的代码数。--codebook_head :代码书的头数。如果数字大于1,则将共同使用多个词汇。--codebook_decay :代码的衰减率。--commit_weight :承诺术语的重量。--finetune_epochs :时代的数量。--finetune_lr :学习率。--early_stop :最大早期停止时期。--batch_size :如果设置为0,请进行完整的图形训练。--lambda_proto :芬特列中原型分类器的重量。
--lambda_act :填充中线性分类器的重量。
--trade_off :使用Prototype Classier或使用线性分类器进行推理之间的权衡。
您可以添加--no_lin_clf或--no_proto_clf分别避免使用线性分类器或原型分类器。请注意,这两个术语是冲突,因为您必须使用至少一个分类器。
实验结果可能由于预处理过程中的随机初始化而有所不同。我们在训练中使用不同的随机种子(IE,1-5)提供实验结果,以显示随机初始化的潜在影响。
| 科拉 | PubMed | Wiki-CS | arxiv | WN18RR | FB15K237 | 艾滋病病毒 | PCBA | 平均的 | |
|---|---|---|---|---|---|---|---|---|---|
| 种子= 1 | 78.58±0.90 | 77.55±1.54 | 79.38±0.57 | 72.24±0.16 | 91.56±0.33 | 89.67±0.35 | 72.69±1.93 | 78.24±0.23 | 79.99 |
| 种子= 2 | 78.27±1.26 | 76.41±1.36 | 79.36±0.62 | 72.13±0.24 | 91.72±0.19 | 89.66±0.31 | 71.62±2.45 | 78.20±0.33 | 79.67 |
| 种子= 3 | 78.16±1.62 | 76.28±1.37 | 79.32±0.65 | 72.13±0.30 | 91.57±0.44 | 89.78±0.23 | 71.58±2.28 | 78.12±0.37 | 79.62 |
| 种子= 4 | 78.42±1.37 | 75.76±1.58 | 79.44±0.62 | 72.36±0.34 | 91.70±0.24 | 89.73±0.21 | 72.57±2.46 | 78.34±0.27 | 79.79 |
| 种子= 5 | 78.56±1.62 | 76.49±2.00 | 79.27±0.55 | 72.18±0.26 | 91.47±0.39 | 89.80±0.19 | 72.27±0.93 | 78.31±0.34 | 79.79 |
| 报告 | 78.62±1.21 | 77.19±1.99 | 79.39±0.42 | 71.93±0.12 | 91.91±0.34 | 89.72±0.20 | 72.67±1.38 | 77.90±0.64 | 79.92 |
为了更好地确保可重复性,我们在此链接中提供了种子= 1的检查点。由于其最佳平均表现,我们选择了它。您可以在路径ckpts/pretrain_model/中解压缩下载的文件,并在使用finetune.py时设置--pt_seed 1 ,以精致利用我们提供的检查点。
如果您有疑问,请联系[email protected]或打开问题。
如果您发现仓库对您的研究很有用,请正确引用原始论文。
@inproceedings { wang2024gft ,
title = { GFT: Graph Foundation Model with Transferable Tree Vocabulary } ,
author = { Wang, Zehong and Zhang, Zheyuan and Chawla, Nitesh V and Zhang, Chuxu and Ye, Yanfang } ,
booktitle = { The Thirty-eighth Annual Conference on Neural Information Processing Systems } ,
year = { 2024 } ,
url = { https://openreview.net/forum?id=0MXzbAv8xy }
}该存储库基于OFA,PYG,OGB和VQ的代码库。感谢他们的分享!


