guidewire
1.0.0
将GuideWire CDA解释为三角洲表:作为一家技术公司,Guidewire为全球财产和伤亡保险公司提供了行业平台。通过其保险套件下的不同产品和服务,他们为用户提供了获取,处理和解决索赔,维护保单,支持承保和调整过程所需的操作功能。另一方面,Databricks通过其湖屋为用户提供了分析功能(从基本报告到复杂的ML解决方案)。通过将两个平台相结合在一起,P&C保险公司现在具有开始将高级分析功能(AI/ML)集成到其核心业务流程中的能力,并使用替代数据(例如天气数据)丰富了客户信息,但同样对Enterprise的关键信息进行了协调和报告。规模。
GuideWire通过其云数据访问产品(CDA)支持数据访问分析环境。不幸的是,将文件存储为不同的时间戳和架构Evolution下的单个镶木文件,这对于最终用户来说很难处理。与其单独处理文件,为什么我们不生成delta log清单文件以仅在需要时读取所需的信息,而无需下载,处理和调和复杂的信息?这是该计划的背后原则。生成的三角洲表将无法实现(数据不会在物理上移动),而是充当指导线数据的浅克隆。
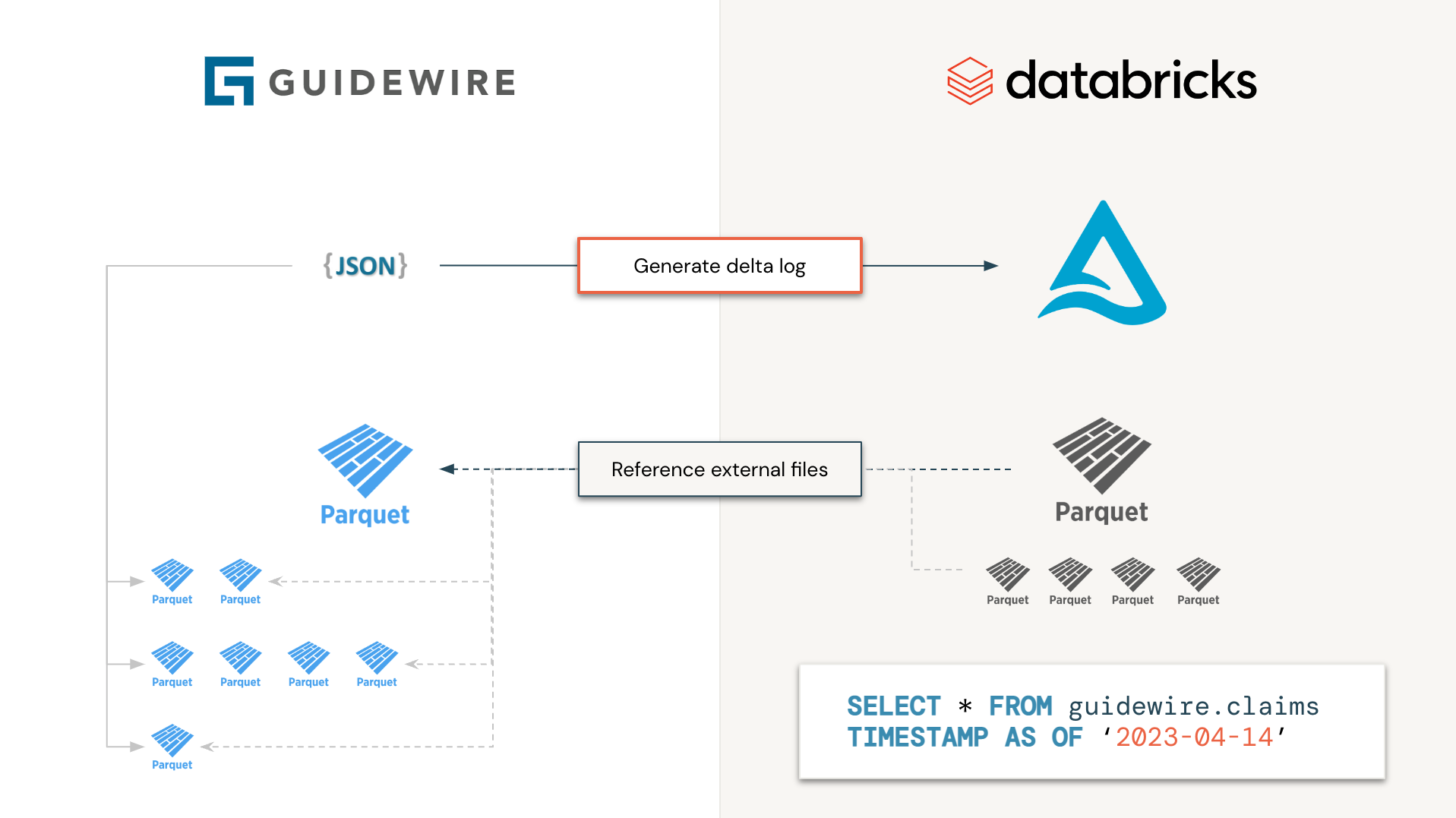
更具体地说,我们将同时(即作为Spark作业)独立处理所有GuideWire表,其中每个任务都将仅列出Parquet文件和文件夹并相应地生成Delta日志。从最终用户的角度来看,GuideWire将看起来像Delta表并进行处理,从而将处理时间从几天减少到几秒钟(因为我们不必通过许多Spark作业下载和处理每个文件)。

由于数据现在位于三角洲湖上(无论是物理化是否实现),因此可以从三角洲湖的所有下游能力中受益,“订阅”通过自动加载器功能,Delta Live Table(DLT)甚至Delta共享,加速,加速是时候从几天到几分钟洞悉。
由于该模型遵循浅层克隆方法,因此建议仅授予最终用户的读取许可,因为生成的三角洲VACCUM操作可能会导致指南S3存储桶的数据丢失。我们强烈建议组织不要将此RAW数据集公开给最终用户,而是创建具有实质性数据的银色版本。请注意, OPTIMIZE命令将导致使用优化的镶木木材文件对最新的Delta快照进行构成现象。仅将相关文件从原始S3到目标表进行物理下载。
import com . databricks . labs . guidewire . Guidewire
val manifestUri = " s3://bucket/key/manifest.json "
val databasePath = " /path/to/delta/database "
Guidewire .index(manifestUri, databasePath)默认情况下,此命令将以数据增量为单位运行,并在${databasePath}/_checkpoints下加载我们以前存储为Delta表的检查点。如果您需要重新索引全部指南数据,请提供可选的savemode参数如下
import org . apache . spark . sql . SaveMode
Guidewire .index(manifestUri, databasePath, saveMode = SaveMode . Overwrite )遵循“浅克隆”模式,将不会存储导丝文件,而是从可以定义为外部表的三角洲位置引用的。
CREATE DATABASE IF NOT EXISTS guidewire;
CREATE EXTERNAL TABLE IF NOT EXISTS guidewire . policy_holders LOCATION ' /path/to/delta/database/policy_holders ' ;最后,我们可以在不同的时间戳上查询GuiderWire数据并访问其所有不同版本。
SELECT * FROM guidewire . policy_holders
VERSION AS OF 2 mvn clean package -Pshaded按照Maven标准,添加配置文件shaded以生成一个独立的JAR文件,其中包含所有依赖项。该罐子可以相应地安装在数据键环境上。


