Marketing Attribution Models
1.0.10
Python班级创建的旨在解决有关数字营销归因的问题。
在线浏览时,用户在转换之前具有多个接触点,这可能会导致更长,更复杂的旅程。
如何适当的信用转换并选择对媒体的投资?
为此,我们应用归因模型。
启发式模型:
上次交互:
Gogle Analytics和其他媒体平台(例如Google Ads和Facebook Business Manager)中的默认归因;
只有最后一个接触点才能归功于转换。
上次点击非直接:
所有直接流量都被忽略了,因此结果的100%进入了客户在转换之前访问网站的最后一个渠道。
第一次交互:
结果完全归因于第一个接触点。
线性:
每个接触点都同样值得注意。
时间衰减:
最近的一个接触点越多,获得的信誉就越多。
位置:
在该模型中,结果的40%归因于最后一个接触点,第一个接触点又归因于第一个接触点,其余20%平均分布在中途通道之间。
算法模型
沙普利价值
在游戏理论中,此值是对合作游戏中每个玩家的贡献的估计。
通过将旅程的过程归功于渠道。在每个排列中,都会给出一个通道,以估计其整体上的实质性。
例如,让我们看一下以下四义旅程:
有机搜索> Facebook>直接> $ 19 (作为收入)
为了获取每个频道的沙普利价值,我们首先需要考虑此给定旅程的组件排列的所有转换值。
有机搜索> $ 7
Facebook> 6美元
直接> $ 4
有机搜索> Facebook> 15美元
有机搜索>直接> $ 7
Facebook> Direct> 9美元
有机搜索> Facebook>直接> 19美元
组件joneys的数量呈指数增加,您拥有的较截然不同的通道:对于n通道,速率为2^n(n的功率为2)。
换句话说,有3个不同的接触点有8个排列。例如,超过15个过程是不可行的。
默认情况下,在计算莎普利价值时,仅考虑接触点的顺序,只有它们的存在或缺乏。为此,排列数量增加。
考虑到这一点,请注意,在考虑交互的顺序时,很难使用此模型。对于n个通道,不仅有给定通道I的2^n排列,而且还存在包含不同位置的所有置换。
沙普利价值的一些问题和局限性
马尔可夫链是马尔可夫链是一个特定的随机过程,在该过程中,任何下一个状态的概率分布仅取决于当前状态,而无视任何先前状态及其序列。
在多通道属性中,我们可以使用马尔可夫链来计算媒体通道对与过渡矩阵之间的相互作用的概率。
关于每个通道在转换方面的贡献,删除效果提出:对于每个jorney,删除了给定的通道并计算了转换概率。
因此,归因于通道的值是通过转换概率与一旦所述通道在一般概率上删除的概率之间差的比率获得的。
换句话说,频道的去除效果越大,其贡献就越大。
**使用马尔可夫流程时,由于通道的数量或顺序,没有限制。它们的顺序本身是该算法的基本组成部分。
>> pip install marketing_attribution_models from marketing_attribution_models import MAM 创建MAM对象时,两个数据框架模板可以用作输入,这取决于参数group_channels的值是什么。
对于此解释,我们将使用一个数据框架,其中尚未将旅程分组,每行都是不同的会话,没有唯一的旅程ID。
注意: MAM类具有用于旅程ID创建的内置参数, create_journey_id_id_based_on_conversion ,如果为true ,则根据用户ID创建ID,在group_channels_id_list参数中输入,而列表示转换是否有其转换,名称由浏览_WITH_CONV_COLNAME参数定义。
在这种情况下,将订购每个不同用户的所有会话,对于每次转换,都会创建新的旅程ID。但是,我们强烈鼓励此旅程ID创建是根据手头和探索性结论的知识来定制的。例如,如果在给定的业务中注意到,平均旅行时间约为一周,则可以定义新的评论者,以便一旦任何用户在7天内没有任何互动,则在假设损失的假设下,旅程中断感兴趣的。
至于现在的参数,以下是它们为我们的group_ channels配置它们的方式= true方案:
attributions = MAM ( df ,
group_channels = True ,
channels_colname = 'channels' ,
journey_with_conv_colname = 'has_transaction' ,
group_channels_by_id_list = [ 'user_id' ],
group_timestamp_colname = 'visitStartTime' ,
create_journey_id_based_on_conversion = True )为了探索和理解MAM的功能,通过使用Random_DF参数设置为true来实现“随机数据帧发生器”。
attributions = MAM ( random_df = True )创建对象MAM之后,我们可以通过添加我们的rowent_id并使用属性“ .dataframe”来查看数据库。
attributions . DataFrame| outhere_id | channels_agg | time_till_conv_agg | converted_agg | conversion_value | |
|---|---|---|---|---|---|
| 0 | ID:0_J:0 | 0.0 | 真的 | 1 | |
| 1 | ID:0_J:1 | Google搜索 | 0.0 | 真的 | 1 |
| 2 | ID:0_J:10 | Google搜索>有机>电子邮件营销 | 72.0> 24.0> 0.0 | 真的 | 1 |
| 3 | ID:0_J:11 | 有机的 | 0.0 | 真的 | 1 |
| 4 | ID:0_J:12 | 电子邮件营销> Facebook | 432.0> 0.0 | 真的 | 1 |
| ... | ... | ... | ... | ... | ... |
| 20341 | ID:9_J:5 | 直接> Facebook | 120.0> 0.0 | 真的 | 1 |
| 20342 | ID:9_J:6 | Google搜索> Google搜索> Google搜索 | 48.0> 24.0> 0.0 | 真的 | 1 |
| 20343 | ID:9_J:7 | 有机>有机> Google搜索> Google搜索 | 480.0> 480.0> 288.0> 0.0 | 真的 | 1 |
| 20344 | ID:9_J:8 | 直接>有机 | 168.0> 0.0 | 真的 | 1 |
| 20345 | ID:9_J:9 | Google搜索>有机> Google搜索> EMAI ... | 528.0> 528.0> 408.0> 240.0> 0.0 | 真的 | 1 |
为生成的每个归因模型更新此属性。仅在启发式模型的情况下,一个新列附加了一个包含所述模型给出的归因值。
注意:属性.dataframe不会干扰任何模型计算。如果使用情况会改变,则以下结果不会受到影响。
attributions . attribution_last_click ()
attributions . DataFrame| outhere_id | channels_agg | time_till_conv_agg | converted_agg | conversion_value | |
|---|---|---|---|---|---|
| 0 | ID:0_J:0 | 0.0 | 真的 | 1 | |
| 1 | ID:0_J:1 | Google搜索 | 0.0 | 真的 | 1 |
| 2 | ID:0_J:10 | Google搜索>有机>电子邮件营销 | 72.0> 24.0> 0.0 | 真的 | 1 |
| 3 | ID:0_J:11 | 有机的 | 0.0 | 真的 | 1 |
| 4 | ID:0_J:12 | 电子邮件营销> Facebook | 432.0> 0.0 | 真的 | 1 |
| ... | ... | ... | ... | ... | ... |
| 20341 | ID:9_J:5 | 直接> Facebook | 120.0> 0.0 | 真的 | 1 |
| 20342 | ID:9_J:6 | Google搜索> Google搜索> Google搜索 | 48.0> 24.0> 0.0 | 真的 | 1 |
| 20343 | ID:9_J:7 | 有机>有机> Google搜索> Google搜索 | 480.0> 480.0> 288.0> 0.0 | 真的 | 1 |
| 20344 | ID:9_J:8 | 直接>有机 | 168.0> 0.0 | 真的 | 1 |
| 20345 | ID:9_J:9 | Google搜索>有机> Google搜索> EMAI ... | 528.0> 528.0> 408.0> 240.0> 0.0 | 真的 | 1 |
通常,使用的数据量是广泛的,因此不切实际甚至不可能分析归因于每次交易旅程的结果。但是,使用属性group_by_channels_models ,所有结果都可以通过频道进行分组。
注意:如果在两个不同的实例中使用相同的模型,则分组结果不会互相覆盖。它们(甚至更多)都在“ group_by_channels_models ”中显示。
attributions . group_by_channels_models| 频道 | attribution_last_click_heuristic |
|---|---|
| 直接的 | 2133 |
| 电子邮件营销 | 1033 |
| 3168 | |
| Google显示 | 1073 |
| Google搜索 | 4255 |
| 1028 | |
| 有机的 | 6322 |
| YouTube | 1093 |
与.dataframe属性一样,对于使用算法结果的每个模型也可以更新group_by_by_channels_models 。
attributions . attribution_shapley ()
attributions . group_by_channels_models| 频道 | attribution_last_click_heuristic | attribution_shapley_size4_conv_rate_algorithmic | |
|---|---|---|---|
| 0 | 直接的 | 109 | 74.926849 |
| 1 | 电子邮件营销 | 54 | 70.558428 |
| 2 | 160 | 160.628945 | |
| 3 | Google显示 | 65 | 110.649352 |
| 4 | Google搜索 | 193 | 202.179519 |
| 5 | 64 | 72.982433 | |
| 6 | 有机的 | 315 | 265.768549 |
| 7 | YouTube | 58 | 60.305925 |
如前所述,使用属性.dataframe和.group_by_channels_models时,所有启发式模型都相同,如前所述,所有启发式模型的方法的输出返回了一个包含两个pandas系列的元组。
attribution_first_click = attributions . attribution_first_click ()元组的第一个系列是旅程粒度的结果,类似于.dataframe属性中观察到的结果
attribution_first_click [ 0 ] 0 [1, 0, 0, 0, 0]
1 [1]
2 [1, 0, 0, 0, 0, 0, 0, 0, 0]
3 [1, 0]
4 [1]
...
20512 [1, 0]
20513 [1, 0, 0]
20514 [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
20515 [1, 0, 0]
20516 [1, 0, 0, 0]
Length: 20517, dtype: object
第二个包含带有通道粒度的结果,如.group_by_channels_models属性所示。
attribution_first_click [ 1 ]| 频道 | attribution_first_click_heuristic | |
|---|---|---|
| 0 | 直接的 | 2078 |
| 1 | 电子邮件营销 | 1095 |
| 2 | 3177 | |
| 3 | Google显示 | 1066 |
| 4 | Google搜索 | 4259 |
| 5 | 1007 | |
| 6 | 有机的 | 6361 |
| 7 | YouTube | 1062 |
在对象MAM中存在的所有模型中,仅上一次单击,首先单击和线性没有可自定义的参数,但是group_by_channels_models ,该参数具有布尔值,该值将设置为false时,该模型不会返回通道对false的归属。
创建的目的是复制Google Analytics的默认属性(上次点击非直接),在此,如果先前的介学在给定的时间板上具有直接的特定流量来源,则直接流量被覆盖了(默认情况下为6个月)。
如果未指定,则参数but_not_this_channel设置为“直接” ,但可以将其设置为业务的任何其他感兴趣的渠道。
attributions . attribution_last_click_non ( but_not_this_channel = 'Direct' )[ 1 ]| 频道 | attribution_last_click_non_direct_heuristic | |
|---|---|---|
| 0 | 直接的 | 11 |
| 1 | 电子邮件营销 | 60 |
| 2 | 172 | |
| 3 | Google显示 | 69 |
| 4 | Google搜索 | 224 |
| 5 | 67 | |
| 6 | 有机的 | 350 |
| 7 | YouTube | 65 |
该模型具有一个参数list_positions_first_middle_last ,其中每个旅程中频道位置的权重可以根据与业务相关的决策指定。引入通道的参数的默认分布为40% ,转换 /最后一个通道的默认分布为40% ,在层间通道中为20% 。
attributions . attribution_position_based ( list_positions_first_middle_last = [ 0.3 , 0.3 , 0.4 ])[ 1 ]| 频道 | attribution_position_based_0.3_0.3_0.4_heuristic | |
|---|---|---|
| 0 | 直接的 | 95.685085 |
| 1 | 电子邮件营销 | 57.617191 |
| 2 | 145.817501 | |
| 3 | Google显示 | 56.340693 |
| 4 | Google搜索 | 193.282305 |
| 5 | 54.678557 | |
| 6 | 有机的 | 288.148896 |
| 7 | YouTube | 55.629772 |
有两个可自定义的设置:衰减率,throght decay_over_time *参数,以及每个decaiment之间通过频率参数之间的时间(小时)。
但是,值得注意的是,如果频率间隔之间存在多个接触点,则转换值将平均分布在这些通道之间。
例如:
attributions . attribution_time_decay (
decay_over_time = 0.6 ,
frequency = 7 )[ 1 ]| 频道 | attribution_time_decay0.6_freq7_heuristic | |
|---|---|---|
| 0 | 直接的 | 108.679538 |
| 1 | 电子邮件营销 | 54.425914 |
| 2 | 159.592216 | |
| 3 | Google显示 | 64.350107 |
| 4 | Google搜索 | 192.838844 |
| 5 | 64.611414 | |
| 6 | 有机的 | 314.920082 |
| 7 | YouTube | 58.581845 |
uppon被称为,该型号返回带有四个组件的元组。前两个(索引0和1)就像启发式模型一样,分别代表.dataframe和.group_by_channels_models 。至于第三组和第四个组件(索引2和3),结果是过渡矩阵和去除效应表。
首先,可以指示是否考虑相同的状态转换(例如直接直接)。
attribution_markov = attributions . attribution_markov ( transition_to_same_state = False )| 频道 | attribution_markov_algorithmic | |
|---|---|---|
| 0 | 直接的 | 2305.324362 |
| 1 | 电子邮件营销 | 1237.400774 |
| 2 | 3273.918832 | |
| 3 | YouTube | 1231.183938 |
| 4 | Google搜索 | 4035.260685 |
| 5 | 1205.949095 | |
| 6 | 有机的 | 5358.270644 |
| 7 | Google显示 | 1213.691671 |
此配置不会影响每个通道的总体归因结果,而是在过渡矩阵中观察到的值。因为我们将Transition_TO_SAME_STATE设置为false ,所以表明状态过渡到自己的对角线是无效的。
ax , fig = plt . subplots ( figsize = ( 15 , 10 ))
sns . heatmap ( attribution_markov [ 2 ]. round ( 3 ), cmap = "YlGnBu" , annot = True , linewidths = .5 )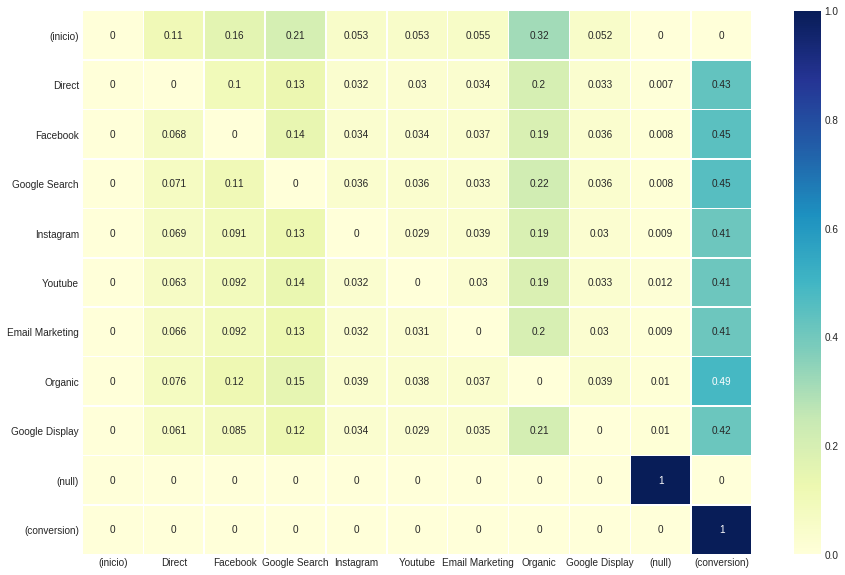
去除效果是第四属性_Markov输出,是通过转换概率与一度概率之间的差异的比率获得的,曾经在一般概率上删除了该通道。
ax , fig = plt . subplots ( figsize = ( 2 , 5 ))
sns . heatmap ( attribution_markov [ 3 ]. round ( 3 ), cmap = "YlGnBu" , annot = True , linewidths = .5 )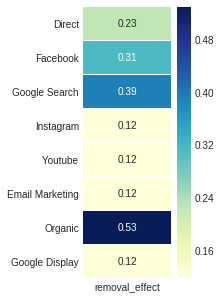
最后, MAM的第二个算法模型来自游戏理论。这里的目的是在使用有或没有给定渠道的旅程组合计算的合作游戏中分发每个玩家(在我们的情况下)的贡献(在我们的情况下)。
参数大小定义了每次旅程中一系列通道链的限制。默认情况下,它的值设置为4 ,这意味着仅考虑转换之前的最后四个通道。
每个通道的边际贡献的计算方法可以随阶参数而变化。默认情况下,它设置为false ,这意味着计算出贡献,无视旅程中每个通道的顺序。
attributions . attribution_shapley ( size = 4 , order = True , values_col = 'conv_rate' )[ 0 ]| 组合 | 转换 | total_ sequences | conversion_value | cons_rate | attribution_shapley_size4_conv_rate_order_algorithmic | |
|---|---|---|---|---|---|---|
| 0 | 直接的 | 909 | 926 | 909 | 0.981641 | [909.0] |
| 1 | 直接>电子邮件营销 | 27 | 28 | 27 | 0.964286 | [13.948270234099155,13.051729765900845] |
| 2 | 直接>电子邮件营销> Facebook | 5 | 5 | 5 | 1.000000 | [1.663666232390172,1.583583671498818,1.752 ... |
| 3 | 直接>电子邮件营销> Facebook> Google D ... | 1 | 1 | 1 | 1.000000 | [0.2563402919193473,0.23455607999963515,0.259 ... |
| 4 | 直接>电子邮件营销> Facebook> Google S ... | 1 | 1 | 1 | 1.000000 | [0.2522517802130265,0.2401286956930936,0.255 ... |
| ... | ... | ... | ... | ... | ... | ... |
| 1278 | YouTube>有机> Google搜索> Google dis ... | 1 | 2 | 1 | 0.500000 | [0.2514214624662836,0.24872101523605275,0.24 ... |
| 1279 | YouTube>有机> Google搜索> Instagram | 1 | 1 | 1 | 1.000000 | [0.2544401477637237,0.2541071889956603,0.253 ... |
| 1280 | YouTube>有机> Instagram | 4 | 4 | 4 | 1.000000 | [1.2757196742326997,1.4712839059493295,1.252 ... |
| 1281 | YouTube>有机> Instagram> Facebook | 1 | 1 | 1 | 1.000000 | [0.2357631944623868,0.2610913781266248,0.247 ... |
| 1282 | YouTube>有机> Instagram> Google搜索 | 3 | 3 | 3 | 1.000000 | [0.7223482210689489,0.7769049003203142,0.726 ... |
最后,指示用于计算shapley值的参数是values_col ,默认情况下将其设置为转换率。这样,没有转换的旅程就会进入acount。
但是,在使用模型时,有可能仅考虑字面转换。
attributions . attribution_shapley ( size = 3 , order = False , values_col = 'conversions' )[ 0 ]| 组合 | 转换 | total_ sequences | conversion_value | cons_rate | attribution_shapley_size3_conversions_algorithmic | |
|---|---|---|---|---|---|---|
| 0 | 直接的 | 11 | 18 | 18 | 0.611111 | [11.0] |
| 1 | 直接>电子邮件营销 | 4 | 5 | 5 | 0.800000 | [2.0,2.0] |
| 2 | 直接>电子邮件营销> Google搜索 | 1 | 2 | 2 | 0.500000 | [-3.166666666666665,-7.666666666666666,11.8 ... |
| 3 | 直接>电子邮件营销>有机 | 4 | 6 | 6 | 0.666667 | [-7.833333333333333,-10.833333333333332,22.6 ... |
| 4 | 直接> Facebook | 3 | 4 | 4 | 0.750000 | [-8.5,11.5] |
| ... | ... | ... | ... | ... | ... | ... |
| 75 | Instagram>有机> YouTube | 46 | 123 | 123 | 0.373984 | [5.83333333333332,34.33333333333333,5.83333 ... |
| 76 | Instagram> YouTube | 2 | 4 | 4 | 0.500000 | [2.0,0.0] |
| 77 | 有机的 | 64 | 92 | 92 | 0.695652 | [64.0] |
| 78 | 有机> YouTube | 8 | 11 | 11 | 0.727273 | [30.5,-22.5] |
| 79 | YouTube | 11 | 15 | 15 | 0.733333 | [11.0] |
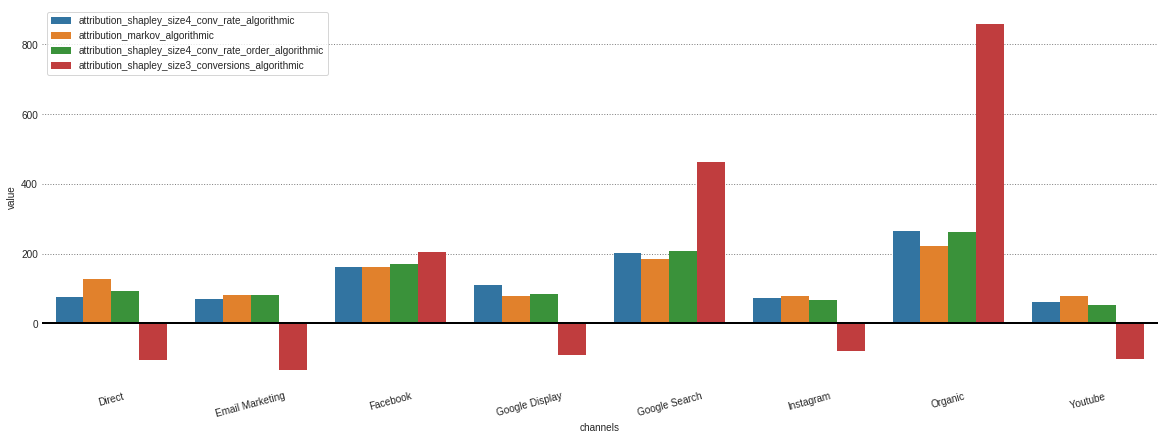
从我们的.group_by_channels_models对象中获取了存储的不同模型的所有归因之后,可以绘制和比较洞察力的结果
attributions . plot ()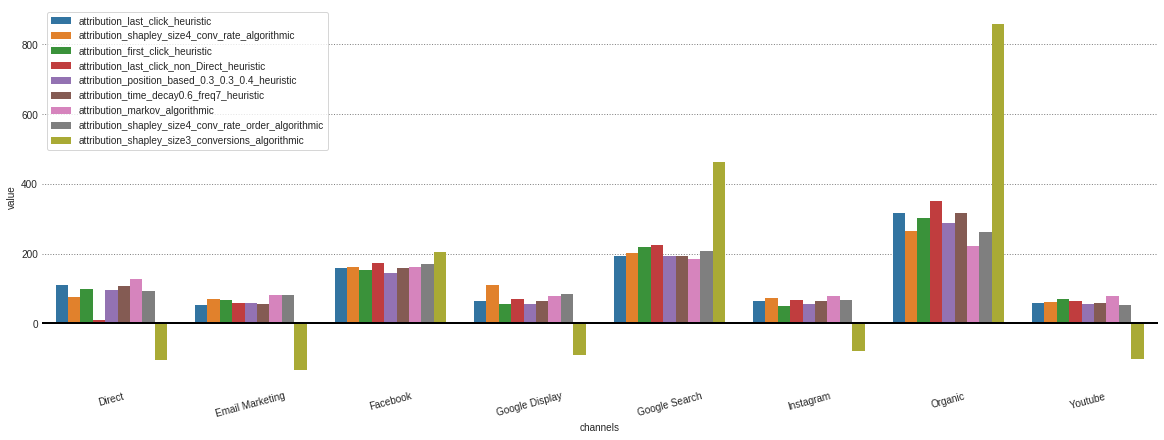
如果您只对算法模型感兴趣,那么我可以在model_type参数中指定。
attributions . plot ( model_type = 'algorithmic' )