ainovelprompter
1.0.0
AI新颖的提示者可以根据用户指定特征为小说生成写作提示。
AI Novel Novel Propter是一个桌面应用程序,旨在帮助作家为Chatgpt和Claude等人工智能写作助理创建一致且结构良好的提示。该工具有助于管理故事元素,角色细节,并生成正确格式的提示,以继续您的小说。
可执行文件在构建/bin上可执行
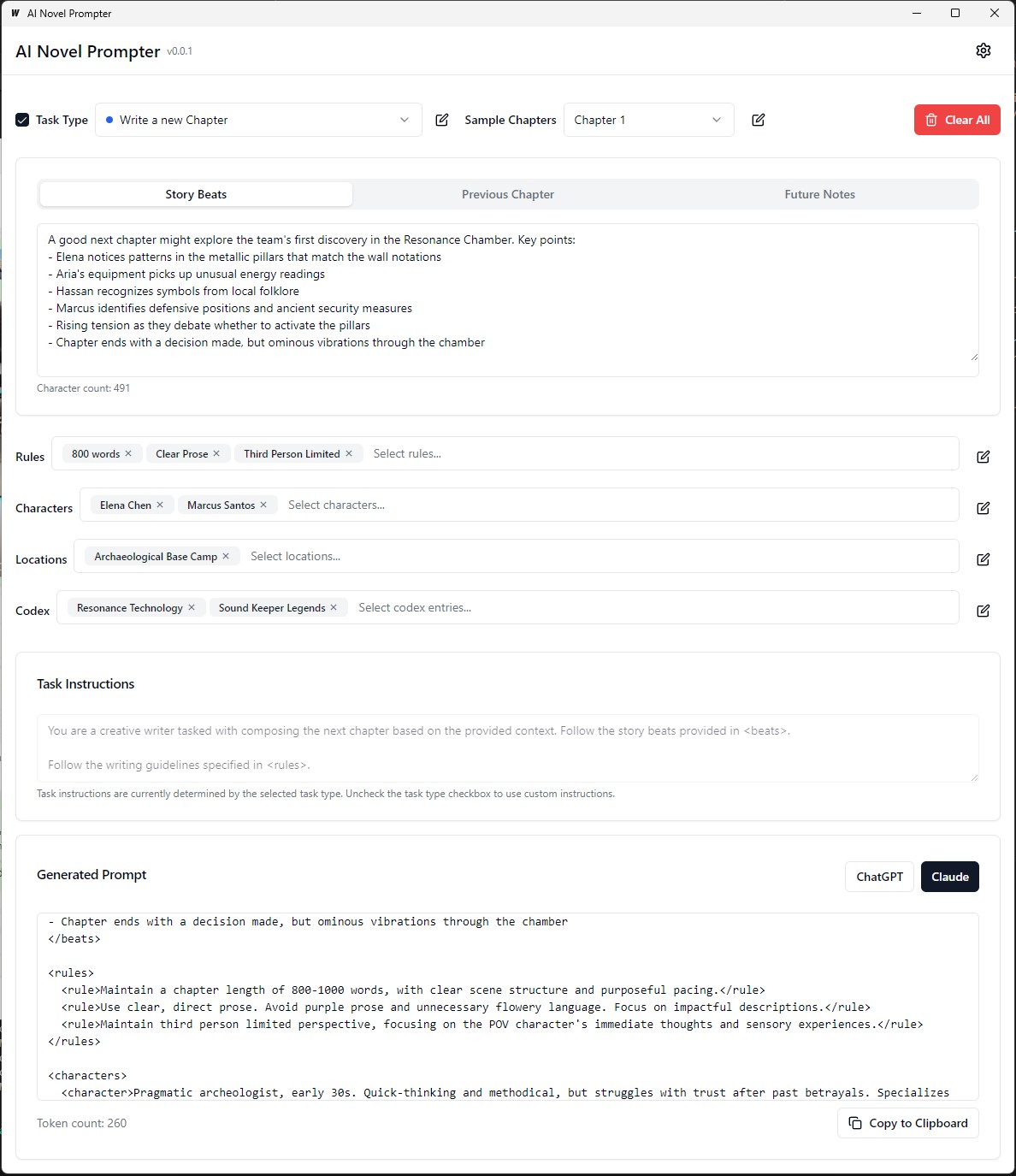
每个类别都可以在不同的提示中进行编辑,保存和重复使用:
前端:
后端:
.ai-novel-prompter # Clone the repository
git clone [repository-url]
# Install frontend dependencies
cd frontend
npm install
# Build and run the application
cd ..
wails dev要构建可重新分配的生产模式包,请使用wails build 。
wails build可执行文件在构建/bin上可执行
或以:
wails build -nsis可以为Mac完成此指南的最新部分
构建应用程序将在build目录中可用。
初始设置:
创建一个提示:
生成输出:
在运行应用程序之前,请确保已安装以下内容:
git clone https://github.com/danielsobrado/ainovelprompter.git
cd ainovelprompter
导航到server目录:
cd server
安装GO依赖性:
go mod download
使用您的数据库配置更新config.yaml文件。
运行数据库迁移:
go run cmd/main.go migrate
启动后端服务器:
go run cmd/main.go
导航到client端目录:
cd ../client
安装前端依赖性:
npm install
启动前端开发服务器:
npm start
http://localhost:3000访问应用程序。 git clone https://github.com/danielsobrado/ainovelprompter.git
cd ainovelprompter
使用您的数据库配置更新docker-compose.yml文件。
使用Docker组成启动应用程序:
docker-compose up -d
http://localhost:3000访问应用程序。 server/config.yaml文件中修改后端配置。client/src/config.ts文件中修改前端配置。 要构建生产前端,请在client目录中运行以下命令:
npm run build
可以在client/build目录中生成生产的文件。
该小指南提供了有关如何在Linux(WSL)的Windows子系统上安装PostgreSQL的说明,以及管理用户权限并解决常见问题的步骤。
打开WSL终端:启动您的WSL发行版(建议使用Ubuntu)。
更新软件包:
sudo apt update安装PostgreSQL :
sudo apt install postgresql postgresql-contrib检查安装:
psql --version设置PostgreSQL用户密码:
sudo passwd postgres创建数据库:
createdb mydb访问数据库:
psql mydb来自SQL文件的导入表:
psql -U postgres -q mydb < /path/to/file.sql列出数据库和表:
l # List databases
dt # List tables in the current database开关数据库:
c dbname创建新用户:
CREATE USER your_db_user WITH PASSWORD ' your_db_password ' ;授予特权:
ALTER USER your_db_user CREATEDB;角色不存在错误:切换到“ Postgres”用户:
sudo -i -u postgres
createdb your_db_name拒绝创建扩展名的权限:登录为'Postgres'并执行:
CREATE EXTENSION IF NOT EXISTS pg_trgm;未知用户错误:确保您使用已识别的系统用户或正确地涉及SQL环境中的PostgreSQL用户,而不是通过sudo 。
为了生成自定义培训数据,以微调语言模型来模仿乔治·麦克唐纳(George MacDonald)的写作风格,该过程始于Gutenberg Project Gutenberg的一部小说“公主和哥布林”的全文。然后,使用提示提示将文本分解为单个故事节奏或关键时刻,该提示指示AI为每个节拍生成一个JSON对象,捕获作者,情感语气,写作类型和实际文本摘录。
接下来,GPT-4用于用自己的文字重写每个故事节拍,从而生成一组带有唯一标识符的JSON数据,将每个重写的节拍链接到其原始对应物。为了简化数据并使其对训练更有用,使用Python功能将各种情感色调映射到较小的核心音调。然后使用两个JSON文件(原始和重写的节拍)来生成训练提示,在此要求该模型以原始作者的样式重新绘制GPT-4生成的文本。最后,将这些提示及其目标输出格式化为JSONL和JSON文件,准备用于微调语言模型以捕获MacDonald的独特写作样式。
在上一个示例中,使用语言模型生成解释文本的过程涉及一些手动任务。用户必须手动提供输入文本,运行脚本,然后查看生成的输出以确保其质量。如果输出不符合所需的标准,则用户将需要手动用不同的参数重试生成过程或对输入文本进行调整。
但是,随着process_text_file函数的更新版本,整个过程已完全自动化。该函数需要读取输入文本文件,将其分成段落,并自动将每个段落发送到语言模型以进行释义。它结合了各种检查和重试机制,以处理生成的输出不符合指定标准的情况,例如包含不必要的短语,太短或太长或由多个段落组成。
自动化过程包括几个关键功能:
从最后一个处理的段落恢复:如果脚本被中断或需要多次运行,它将自动检查输出文件并从最后一段成功地解释段落中恢复处理。这样可以确保进步不会丢失,并且脚本可以在其停止的位置接收。
带有随机种子和温度的重试机制:如果生成的释义无法满足指定的标准,则脚本将自动将生成过程检验到指定的次数。每次重试时,它会随机更改种子和温度值以引入生成的响应中的变化,从而增加了获得令人满意的输出的机会。
进度保存:脚本将进度保存到输出文件中,每个指定的段落数(例如,每500段)。如果在处理大型文本文件期间发生任何中断或错误的情况下,这种防止数据丢失。
详细的日志记录和摘要:脚本提供详细的日志记录信息,包括输入段落,生成的输出,重试尝试以及失败的原因。它还在结尾产生了一个摘要,显示了段落的总数,成功的段落,跳过段落以及回程总数。
为了生成ORPO自定义培训数据,以微调语言模型,以模仿乔治·麦克唐纳(George MacDonald)的写作风格。
输入数据应为JSONL格式,每行包含一个包括提示和选择响应的JSON对象。 (从上一个微调)要使用脚本,您需要使用API键设置OpenAI客户端并指定输入和输出文件路径。运行脚本将处理JSONL文件并生成一个带有提示,选择响应和生成的拒绝响应的CSV文件。脚本可以节省每100行的进度,并且可以在中断的情况下恢复到关闭的位置。完成后,它提供了处理的总线路,书面线,跳过线条和重试详细信息的摘要。
数据集质量重要:95%的结果取决于数据集质量。干净的数据集是必不可少的,因为即使有一点糟糕的数据也会损害模型。
手动数据审查:清洁和评估数据集可以大大改善模型。这是一个耗时但必要的步骤,因为没有任何参数调整可以修复有缺陷的数据集。
训练参数不应改善,而应防止模型降解。在强大的数据集中,目标应该是在指导模型时避免负面影响。没有最佳的学习率。
模型尺度和硬件限制:较大的型号(33B参数)可能会启用更好的微调,但至少需要48GB VRAM,这使得它们在大多数家庭设置中都不切实际。
梯度积累和批处理大小:梯度积累有助于通过增强不同数据集的概括来减少过度拟合,但是几批后它可能会降低质量。
与调整良好的模型相比,数据集的大小对于微调基本模型更为重要。超负荷具有过多的数据,可能会降低其先前的微调。
理想的学习率时间表从热身阶段开始,保持稳定,以使一个时代稳定,然后使用余弦时间表逐渐减少。
模型等级和概括:可训练参数的数量会影响模型的细节和概括。较低的模型可以更好地推广但丢失细节。
LORA的适用性:参数有效的微调(PEFT)适用于大型语言模型(LLMS)和诸如稳定扩散(SD)之类的系统,证明其多功能性。
Unsploth社区帮助解决了Finetuning Llama3的几个问题。以下是要记住的一些关键点:
双BOS令牌:固定期间的双BOS令牌可能会破坏东西。 Unsploth会自动解决此问题。
GGUF转换:GGUF转换被打破。小心双BOS,然后使用CPU代替GPU进行转换。 Unsploth具有内置的自动GGUF转换。
故障基础重量:Llama 3的某些基数(不是指令)的权重为“ buggy”(未训练): <|reserved_special_token_{0->250}|> <|eot_id|> <|start_header_id|> <|end_header_id|> 。这可能会导致NAN和越野车结果。不绒布会自动修复此问题。
系统提示:根据Unsploth社区的说法,添加系统提示可以使指示版本(可能是基本版本)更好。
量化问题:量化问题很常见。请参阅此比较,表明您可以通过Llama3获得良好的性能,但是使用错误的量化会损害性能。要进行填充,请使用BitsandBytes NF4提高准确性。对于GGUF,请尽可能使用i版本。
长上下文模型:长上下文模型受过良好的训练。他们只是将绳索伸展,有时没有任何培训,然后在怪异的串联数据集上训练以使其成为长数据集。这种方法无法正常工作。如果从8K到1M上下文长度缩放,则平稳,连续的长上下文缩放会更好。
为了解决其中一些问题,请使用不塞来进行固定的乳白色3。
在微调以作者风格释义的语言模型时,评估产生的释义的质量和有效性很重要。
以下评估指标可用于评估模型的性能:
BLEU(双语评估研究):
sacrebleu库。from sacrebleu import corpus_bleu; bleu_score = corpus_bleu(generated_paraphrases, [original_paragraphs])Rouge(以召回的研究为目标评估):
rouge库。from rouge import Rouge; rouge = Rouge(); scores = rouge.get_scores(generated_paraphrases, original_paragraphs)困惑:
perplexity = model.perplexity(generated_paraphrases)造型测量指标:
stylometry学库。from stylometry import extract_features; features = extract_features(generated_paraphrases)要将这些评估指标集成到您的Axolotl管道中,请执行以下步骤:
通过创建目标作者作品的段落数据集并将其分为培训和验证集来准备培训数据。
按照前面讨论的方法,使用培训集对您的语言模型进行微调。
使用微型模型为验证集中的段落生成释义。
使用相应的库( sacrebleu , rouge , stylometry )实现评估指标,并计算每个生成的释义的分数。
通过收集人类评估者的评分和反馈来进行人类评估。
分析评估结果,以评估产生的释义的质量和样式,并做出明智的决定以改善您的微调过程。
这是如何将这些指标集成到管道中的示例:
from sacrebleu import corpus_bleu
from rouge import Rouge
from stylometry import extract_features
# Fine-tune the model using the training set
fine_tuned_model = train_model ( training_data )
# Generate paraphrases for the validation set
generated_paraphrases = generate_paraphrases ( fine_tuned_model , validation_data )
# Calculate evaluation metrics
bleu_score = corpus_bleu ( generated_paraphrases , [ original_paragraphs ])
rouge = Rouge ()
rouge_scores = rouge . get_scores ( generated_paraphrases , original_paragraphs )
perplexity = fine_tuned_model . perplexity ( generated_paraphrases )
stylometric_features = extract_features ( generated_paraphrases )
# Perform human evaluation
human_scores = collect_human_evaluations ( generated_paraphrases )
# Analyze and interpret the results
analyze_results ( bleu_score , rouge_scores , perplexity , stylometric_features , human_scores )请记住要安装必要的库(Sacrebleu,Rouge,样式测定法),并调整代码以适合您的Axolotl或类似实现。
在此实验中,我探讨了各种AI模型之间根据详细提示生成1500字文本的功能和差异。我从https://chat.lmsys.org/,Chatgpt4,Claude 3 Opus和LM Studio中的一些本地型号测试了模型。每个模型都生成文本三次,以观察其输出的可变性。我还创建了一个单独的提示,以评估每个模型的第一次迭代的写作,并询问Chatgpt 4和Claude Opus 3提供反馈。
通过此过程,我观察到某些模型在执行之间表现出更高的可变性,而另一些模型倾向于使用相似的措辞。每种模型产生的单词数量以及对话,描述和段落的数量也存在显着差异。评估反馈表明,Chatgpt提出了更“精致”的散文,而Claude建议较少的紫色散文。根据这些发现,我编制了一系列外卖列表,以将其纳入下一个提示中,重点介绍精确的,多样化的句子结构,强大的动词,独特的幻想,幻想主题,一致的语气,独特的叙述者声音和引人入胜的节奏。要考虑的另一种技术是寻求反馈,然后根据反馈重写文本。
我愿意与他人合作,以进一步调整每个模型的提示,并探索他们在创意写作任务中的能力。
模型具有固有的格式偏差。有些型号更喜欢列表的连字符,而另一些则喜欢星号。使用这些模型时,有助于反映其偏好以获得一致的输出。
格式倾向:
Llama 3更喜欢用大胆的标题和星号列表。
示例:大胆的标题案例标题
在两个新线后列出带有星号的项目
列出由一个newline隔开的项目
下一个列表
更多列表项目
ETC...
几个示例:
系统及时依从性:
上下文窗口:
审查制度:
智力:
一致性:
列表和格式:
聊天设置:
管道设置:
Llama 3具有灵活且聪明,但具有上下文和引用局限性。相应地调整提示方法。
欢迎所有评论。如果您找到任何错误或有改进的建议,请打开问题或发送拉请请求。
该项目的许可在:属性 - 非商业 - 诺迪德剂(by-nc-nd)许可证中,请参见:https://creativecommons.org/licenses/by-nc-nc-nc-nd/4.0/deed.en


