mario ai
1.0.0
该项目包含训练模型的代码,该模型将仅使用RAW像素作为输入(无手工设计功能)自动播放超级马里奥世界的第一级。如Atari论文(摘要)中所述,使用的技术是深Q学习,并结合了空间变压器。
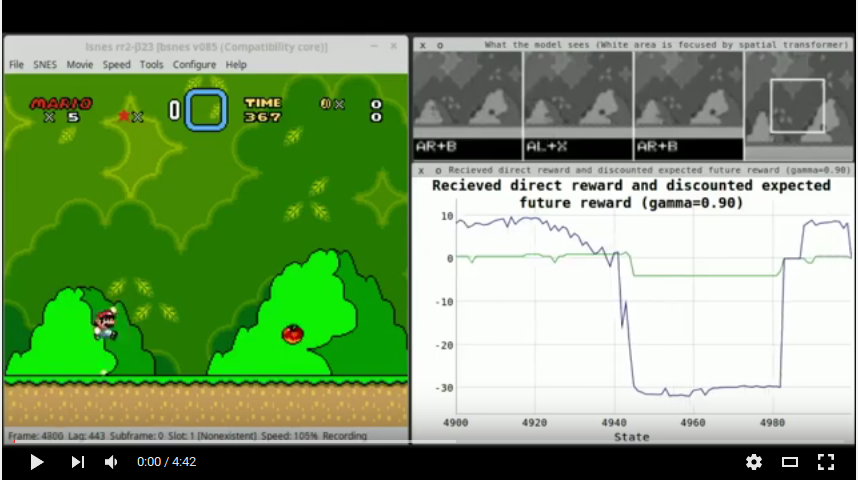
训练方法是带有重播记忆的深度Q学习,即模型观察屏幕的序列,将其保存到其内存中,然后在其上进行训练,其中“训练”意味着它学会了准确预测预期的动作奖励值(”动作“平均”按钮x”)基于收集的记忆。默认情况下,重播内存的大小为250k条目。当它开始满足时,新的条目代替了较旧的条目。对于培训批次,选择了示例(均匀分布),并根据网络到目前为止所学到的知识来重新估计记忆的回报。
每个示例的输入都有以下结构:
t当前设置为4(请注意,这包括序列的最后一个状态)。屏幕在每个第五帧中都会捕获。每个示例的输出是所选操作的动作奖励值(接收到下一个状态的直接奖励 +折扣Q值)。该模型每个状态可以选择两个动作:一个箭头按钮(向上,向下,右,左)和其他控制按钮之一(a,b,x,y)。这与Atari模型不同,Atari模型只能一次选择一个按钮。 (没有这种更改,理论上可能不会跳很多跳,这迫使您按下按钮并向右移动。)奖励功能的构造方式几乎永远不会是0,正是两个,正是两个每个示例的输出值预计为非零。
代理商获得以下奖励:
+0.5如果代理向右移动,则+1.0如果它快速向右移动(与上一个游戏状态相比8个像素或更多),则-1.0 ,如果向左移动,则为-1.5 ,如果是-1.5快速移动向左(-8像素或更多)。+2.0 ,而级别的动画正在播放。-3.0死亡动画在演奏时。 gamma (预期/间接奖励的折扣)设置为0.9 。
仅在得分上提高模型(例如在Atari纸上)的训练很可能是行不通的,因为当敌人的产卵位置在屏幕外移动时,敌人重生,因此代理商可以一次又一次地杀死它们,每次增加得分。
选择性MSE用于训练代理。也就是说,对于每个示例梯度,就像是MSE一样。但是,如果目标奖励为0,则所有动作值的梯度都设置为0。这是因为每个示例仅包含一对选定按钮的接收奖励(箭头按钮,另一个按钮)。其他成对的行动是可能的,但代理商没有选择它们,因此对他们的奖励尚不清楚。他们的奖励值(按照示例)设置为0,但不是因为它们确实是0,而是因为我们不知道代理商选择了什么奖励。因此,对它们的反向传播梯度(即,如果代理预测值不相等,则是不合理的。
此实现可以负担得出基于奖励与0不相等的奖励,可以区分所选的和不是选择的按钮(在目标向量中),因为所选按钮的收到的奖励几乎从来没有完全0(由于构建奖励功能)。其他实现可能需要更多地照顾这一步骤。
该政策是一项Epsilon-Greedy,始于Epsilon = 0.8,在第400k-the-the Chose的动作下退火至0.1。每当根据策略选择随机操作时,代理会抛出硬币(即50:50机会),然后随机将其两个(箭头,其他按钮)操作之一随机,或者将它们随机化。
该模型由三个分支组成:
在分支的末尾,在到达输出神经元之前,将所有内容合并到一个通过隐藏层馈送的向量。这些输出神经元预测每个按下按钮的预期奖励。
网络概述:

空间变压器需要一个本地化网络,如下所示:

这两个网络总体上约为660万参数。
该代理仅在第一层进行培训(首先是在开始时在Overworld的右侧)。其他级别由于代理几乎无法应对的各种困难而遭受了更大的损失。其中一些是:
第一级几乎没有这些困难,因此将自己放在DQN上,这就是为什么在这里使用它的原因。在任何级别上进行培训,然后对另一个级别进行测试也很困难,因为每个级别似乎都会引入新事物,例如新的和完全不同的敌人或新机械师(攀爬,新物品,将您挤死的物体等)。
luarocks install packageName ): nn , cudnn , paths , image , display 。显示通常不是火炬的一部分。git clone https://github.com/qassemoquab/stnbhwd.gitcd stnbhwdluarocks make stnbhwd-scm-1.rockspecsudo apt-get install sqlite3 libsqlite3-devluarocks install lsqlite3source/src/libray/lua.cpp并在namespace { : #ifndef LUA_OK
#define LUA_OK 0
#endif
#ifdef LUA_ERRGCMM
REGISTER_LONG_CONSTANT("LUA_ERRGCMM", LUA_ERRGCMM, CONST_PERSISTENT | CONST_CS);
#endif
source/include/core/controller.hpp ,然后将函数do_button_action从私人更改为公共。只需剪切行void do_button_action(const std::string& name, short newstate, int mode);在private:阻止并将其粘贴到public:块。source/src/lua/input.cpp和lua lua::functions LUA_input_fns(... (在文件末尾)插入: int do_button_action(lua::state& L, lua::parameters& P)
{
auto& core = CORE();
std::string name;
short newstate;
int mode;
P(name, newstate, mode);
core.buttons->do_button_action(name, newstate, mode);
return 1;
}
core.lua2->input_controllerdata显然永远不会设置(BTW会让这些功能默默失败,即没有任何错误)。source/src/lua/input.cpp中,在block lua::functions LUA_input_fns(... ,添加do_button_action in到lua命令中,可以从模拟器中加载的lua脚本调用。 {"controller_info", controller_info}, to {"controller_info", controller_info}, {"do_button_action", do_button_action},source/ 。make编译模拟器。options.build中。libwxgtk3.0-dev而不是2.8 dev,因为该软件包的官方页面可能会告诉您要这样做。source/执行sudo cp lsnes /usr/bin/ && sudo chown root:root /usr/bin/lsnes 。之后,您可以通过在控制台窗口中键入lsnes来启动LSNES。sudo mkdir /media/ramdisksudo chmod 777 /media/ramdisksudo mount -t tmpfs -o size=128M none /media/ramdisk && mkdir /media/ramdisk/mario-ai-screenshotsconfig.lua中更改SCREENSHOT_FILEPATH 。git clone https://github.com/aleju/mario-ai.git 。cd进入创建的目录。lsnes启动LSNES(来自存储库目录)。Configure -> Settings -> Advanced然后将LUA内存限制设置为1024MB。 (只能完成一次。)Configure -> Settings -> Controller )。播放直到跨世界弹出。在那里,向右移动并开始该级别。稍微播放一个级别,并通过模拟器的File -> Save -> State到子目录states/train来保存少数状态。名称没关系,但是它们必须以.lsmv结束。 (尝试在整个层面上传播各州。)th -ldisplay.start启动显示服务器。如果您尚未安装显示,请使用luarocks install display 。http://localhost:8000/在浏览器中打开显示服务器输出。Tools -> Run Lua script...并选择train.lua 。Tools -> Reset Lua VM停止培训。learned/中删除文件。请注意,您可以保留重播内存( memory.sqlite )并使用它训练新的网络。您可以使用test.lua测试模型。不要指望它表现出色。代理商仍然会死很多,如果您结束了一系列不良参数的培训,则更是如此。


