Shadow Hand Controller
1.0.0
我们使用深度学习和深入的增强学习为在Mujoco环境中的阴影手模型构建了一个控制器。控制器允许手执行标志性手势。这只手的支撑手势是:
影子手演示:https://youtu.be/vt_booel3fu

ShadowHand是由Mujoco_menagerie存储库提供的3D机器人手,用于学术和研究目的。可以在这里找到:https://github.com/deepmind/mujoco_menagerie/tree/main/main/shadow_hand
Shadow Hand使用20个位置电动机作为执行器,可以在其手指和手腕上移动。它的执行器的控制范围有限,由制造商定义。可以通过将Mujoco模拟器下载并通过Drag&Drop将Shadow Hand XML文件(位于OBJecs/Showe_hand/castic_left.xml)导入Shadow Hand XML文件(位于objecs/shower_hand/castic_left.xml )来找到每个执行器的位置。要查看每个执行器的位置和方向,必须在模拟窗口内启用关节选项,这可以在渲染/模型元素面板中找到。算法,它们在XML文件中进行了分析描述。
下面提供了每个手动执行器的位置以及控制范围:
| ID | ctrl_limit_left | ctrl_limit_right |
|---|---|---|
| 0 | -0.523599 | 0.174533 |
| 1 | -0.698132 | 0.488692 |
| 2 | -1.0472 | 1.0472 |
| 3 | 0 | 1.22173 |
| 4 | -0.20944 | 0.20944 |
| 5 | -0.698132 | 0.698132 |
| 6 | -0.261799 | 1.5708 |
| 7 | -0.349066 | 0.349066 |
| 8 | -0.261799 | 1.5708 |
| 9 | 0 | 3.1415 |
| 10 | -0.349066 | 0.349066 |
| 11 | -0.261799 | 1.5708 |
| 12 | 0 | 3.1415 |
| 13 | -0.349066 | 0.349066 |
| 14 | -0.261799 | 1.5708 |
| 15 | 0 | 3.1415 |
| 16 | 0 | 0.785398 |
| 17 | -0.349066 | 0.349066 |
| 18 | -0.261799 | 1.5708 |
| 19 | 0 | 3.1415 |

行为克隆(BC)是一种通过观察和模仿人类专家来执行任务的教学者的方法。在机器人技术中,这是特别常见的技术,模型学会通过模仿人类来执行任务。此方法涉及:
深度强化学习(DRL)是教学机器以最佳方式执行任务的另一种流行技术,但与行为克隆不同。虽然行为克隆直接从所需行为的示例(演示)中学习,但DRL通过与环境的互动并以奖励或惩罚的形式获得反馈来学习。在DRL环境中,代理商接收其状态
有两个流行的算法系列用于DRL问题:
行为克隆和DRL技术都需要数据集或模拟环境来检索数据。为了培训这两个代理,我们构建了一个由成对组成的数据集
神经网络接收输入向量并输出控制向量。虽然预计输入向量将是浮点值的向量,但我们的数据集包含符号,这些符号是字符串(单词)和订单,即整数数字。由于数据集很小,因此我们将每个单词和顺序转换为唯一向量,如下所示:
| 符号 | 向量 |
|---|---|
| 休息 | [0,0,0,0,0,0,1] |
| 降低 | [0,0,0,0,0,1,0] |
| 中指 | [0,0,0,0,1,0,0] |
| 是的 | [0,0,0,1,0,0,0] |
| 不 | [0,0,1,0,0,0,0] |
| 岩石 | [0,1,0,0,0,0,0] |
| 圆圈 | [1,0,0,0,0,0,0] |
| 命令 | 向量 |
|---|---|
| 1 | [0,0,1] |
| 2 | [0,1,0] |
| 3 | [1,0,0] |
现在,可以将这些功能连接并插入神经网络/DRL代理控制器中。
神经网络的目的是预测20个执行器的控制值:
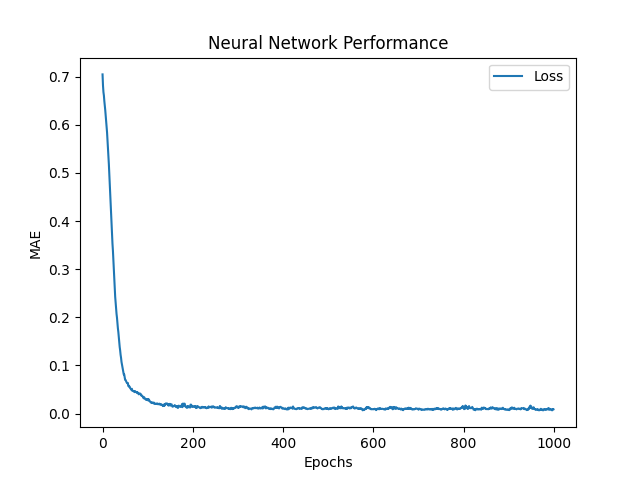
近端策略优化(PPO)是一种流行的政策梯度义务,它解决了信托区域政策优化(TRPO)面临的培训稳定性和效率方面的一些挑战。 PPO介绍了一种剪裁机制,以防止任何单个步骤都过于彻底更新(防止权重进行大型更新并急剧变化),从而确保新政策与旧策略不会太大偏离旧策略。 PPO旨在最大程度地提高目标函数的剪辑版本,而不是直接最大程度地提高预期奖励。该剪辑的客观限制了新政策和旧政策的概率之比。具体而言,如果与旧政策相比,新政策将大大提高该动作的可能性,则此更改被删除为指定范围内(例如,0.8至1.2之间)。这样可以防止过度侵略性的更新,从而迅速将其融合为次优政策。此范围由剪辑参数定义
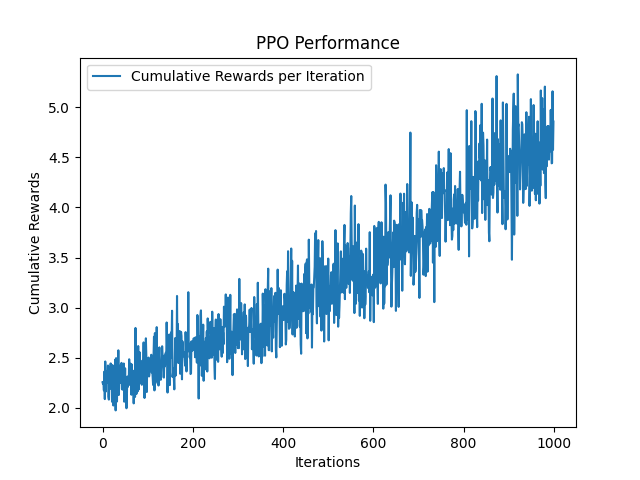
就像BC神经网络一样,PPO作为输入并输出手的目标控制对(符号,顺序)对。然后,它不使用损失(错误)函数来评估其错误,而是使用奖励功能接收奖励,该奖励试图在每次迭代中最大化。奖励功能
start_ctrl = [1,1,1], end_ctrl = [2,2,2] and trajectory_steps=5 ,则手部执行2 + 3个控件[ 1,1,1]和[2,2,2]。可以在glfwsimulator类中提供自定义模型控制器,以便o控制手的执行器(检查simulate_neural_network_controller.py和simutate_neural_network_controller.py示例)。可以修改以下行
hand_controller = Controller(
model=agent,
ctrl_limits=ctrl_limits
)
以便将代理替换为自定义代理。代理(或模型)应继承控制器/controller.py文件中的Controller class ,并定义以下方法:
def _set_sign(self, sign: str) :将控制器的行为设置为指定的符号def _get_next_control(self, sign: str, order: int) :获取指定符号的下一个控件(例如,如果符号定义为10个顺序控件,则get_next_control应返回该顺序的下一个预测控件(check modec.py.py.py.py.py.py文件)。模拟环境是使用Mujoco提供的GLFW库来编写的。可以通过修改simulaton/pyopengl.py文件的while循环轻松修改它。
神经网络使用TensorFlow库构建在型号/TF/NN.PY中。可以通过扩展NeuralNetwork class的构建方法来构建自定义神经网络。当前的体系结构为每个输入向量使用2层128个单位(符号向量为128,订单向量为128个)和每一层中的Relu激活函数。然后,将两层串联成256个单位的向量,然后是另一层128个神经元,最后20个输出单元。最后20个单元用于设置执行器控件。
该存储库使用RLLIB的PPO代理。但是,可以添加几件事:


