paper2slides
1.0.0
使用大型语言模型(LLM)将任何Arxiv论文转换为幻灯片!该工具对于快速掌握研究论文的主要思想很有用。
产生的幻灯片的一些例子是:Word2Vec,gan,变压器,VIT,经过思考链,Star,DPO和AI科学家。在演示中查看许多其他生成幻灯片的示例。
该脚本将从Internet(ARXIV)下载文件,将信息发送到OpenAI API,然后在本地进行编译。请谨慎对待所共享的内容和潜在风险。如果您有您感兴趣的特定ARXIV ID,并且不想自己运行代码,请在“讨论”中告诉我,我很乐意将幻灯片添加到演示列表中。
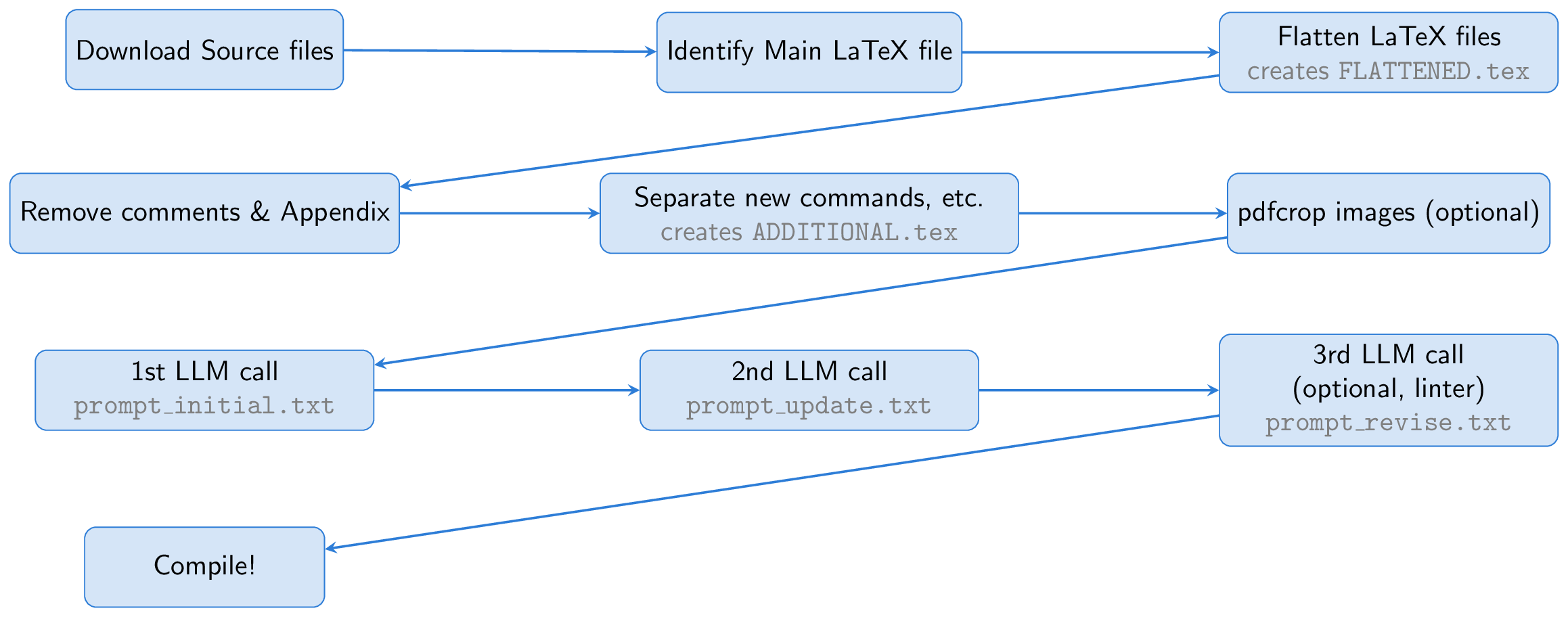
该过程首先下载Arxiv纸的源文件。识别并扁平的主乳胶文件,将所有输入文件合并到一个文档中( FLATTENED.tex )。我们通过删除注释和附录来预处理此合并文件。此预处理文件以及创建良好幻灯片的说明构成了我们提示的基础。
一个关键的想法是将Beamer用于幻灯片创建,从而使我们完全留在乳胶生态系统中。这种方法本质上将任务变成了摘要练习:将长乳胶纸转换为简洁的束乳胶。 LLM可以从字幕中推断数字的内容,并将其包括在幻灯片中,从而消除了对视觉功能的需求。
为了帮助LLM,我们创建了一个名为ADDITIONAL.tex的文件,其中包含所有必要的软件包, newCommand定义以及本文中使用的其他乳胶设置。在提示符中包含input{ADDITIONAL.tex}的该文件会缩短其并使生成幻灯片更可靠,尤其是对于具有许多自定义命令的理论论文。
LLM从乳胶源生成Beamer代码,但是由于第一次运行可能会出现问题,因此我们要求LLM自我了解和完善输出。选择的是,第三步涉及使用Linter检查生成的代码,结果将结果馈回LLM进行进一步的校正(此linter步骤是受AI科学家的启发)。最后,使用PDFLATEX将Beamer代码汇编为PDF表示。
all.zsh脚本可以自动化整个过程,通常在不到几分钟的时间内使用GPT-4O完成一张纸。
要求是:
requests库arxiv库openai图书馆arxiv-latex-cleaner库pdflatex的工作安装安装步骤:
克隆这个存储库:
git clone https://github.com/takashiishida/paper2slides.git
cd paper2slides安装所需的Python软件包:
pip install requests arxiv openai arxiv-latex-cleaner确保安装pdflatex并在系统路径中可用。 (可选)检查是否可以通过pdflatex test.tex编译样品test.tex 。检查test.pdf是否正确。可选地检查chktex和pdfcrop正在工作。
设置您的OpenAI API密钥:
export OPENAI_API_KEY= ' your-api-key ' all.sh脚本该脚本可自动下载Arxiv纸,处理并将其转换为Beamer演示文稿的过程。
bash all.sh < arxiv_id >用所需的Arxiv纸张ID替换<arxiv_id> 。可以从URL识别ID: https://arxiv.org/abs/xxxx.xxxx的ID是xxxx.xxxx 。
您还可以单独运行Python脚本以获得更多控制。
下载并处理Arxiv源文件
python arxiv2tex.py < arxiv_id >该脚本下载指定的Arxiv纸的源文件,提取它们,然后处理主乳胶文件。结果将保存在source/<arxiv_id>/FLATTENED.tex和source/<arxiv_id>/ADDITIONAL.tex中。
将乳胶转换为Beamer
python tex2beamer.py --arxiv_id < arxiv_id >该脚本读取已处理的乳胶文件并准备Beamer幻灯片。这是我们使用OpenAI API的地方。我们拨打两次,首先生成Beamer代码,然后自我了解Beamer代码。 (可选)使用以下标志: --use_linter和--use_pdfcrop 。发送到LLM的提示将保存在tex2beamer.log中。 Linter日志将保存在source/<arxiv_id>/linter.log中。
将Beamer转换为PDF
python beamer2pdf.py < arxiv_id >该脚本将Beamer文件编译为PDF演示文稿。
提示将保存在prompt_initial.txt , prompt_update.txt和prompt_revise.txt中,但随时可以根据您的需求进行调整。它们包含一个称为占位符的占位PLACEHOLDER_FOR_FIGURE_PATHS 。这将被纸张中使用的图路径替换。我们要确保路径在Beamer代码中正确使用。 LLM通常会犯错误,因此我们将其明确包含在提示中。
成功率在我的经验中约为90%(编译可能失败或图像路径在某些情况下可能是错误的)。如果您遇到任何问题或有任何改进建议,请随时让我知道!


