pytorch openai transformer lm
1.0.0
这是Alec Radford,Karthik Narasimhan,Tim Salimans和Ilya Sutskever提供的Openai论文“通过生成预培训来提高语言理解的TensorFlow代码的Pytorch实现”。
该实现包括一个脚本,以加载Pytorch模型中的权重,并由作者通过TensorFlow实现进行训练。
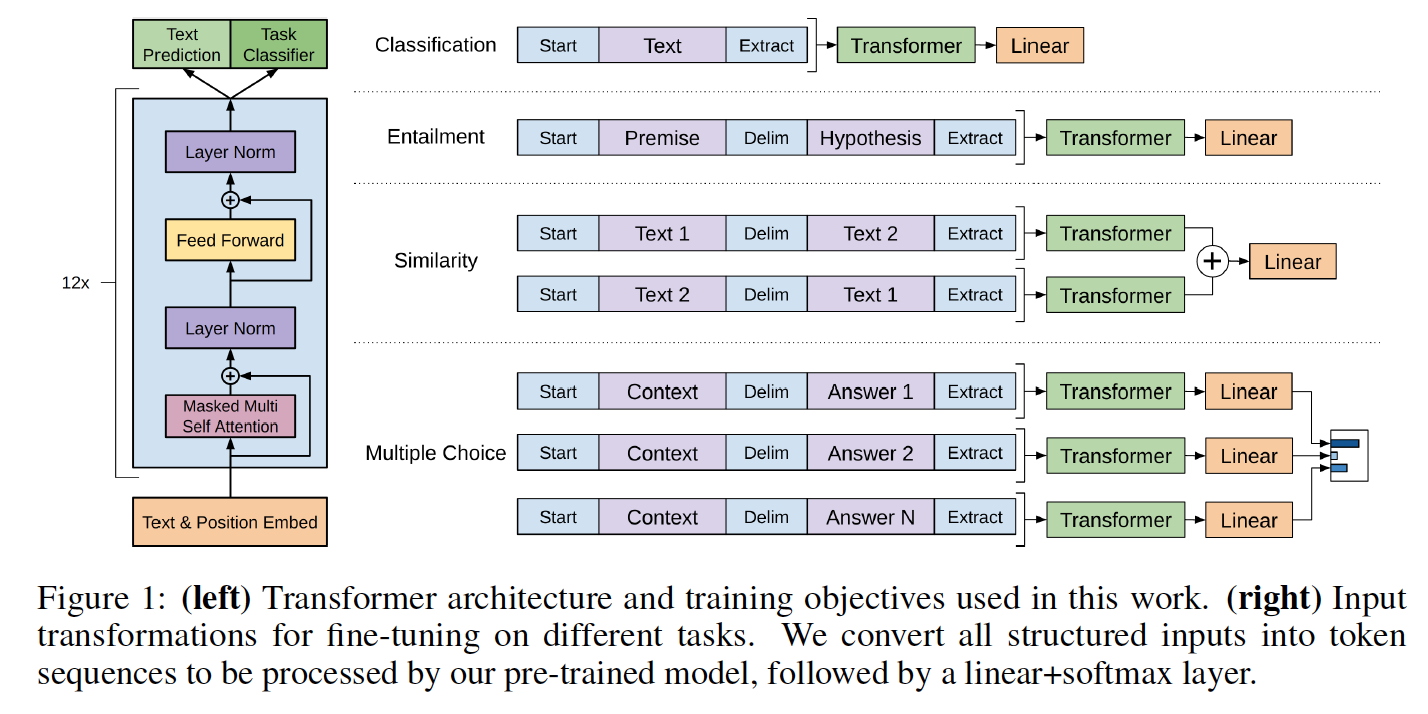
模型类和加载脚本位于model_pytorch.py中。
Pytorch模型中模块的名称遵循TensorFlow实现中变量的名称。此实施试图尽可能遵循原始代码,以最大程度地减少差异。
因此,该实现还包括Openai论文中使用的修改后的ADAM优化算法:
要通过导入model_pytorch.py来使用模型IT自我,您只需要:
要在Train.py中运行分类器培训脚本。您还需要:
您可以通过克隆Alec Radford的存储库来下载OpenAI预训练版本的权重,并将包含预训练权重的model文件夹放在本仓库中。
该模型可以用作具有OpenAI预先训练的权重的变压器语言模型,如下:
from model_pytorch import TransformerModel , load_openai_pretrained_model , DEFAULT_CONFIG
args = DEFAULT_CONFIG
model = TransformerModel ( args )
load_openai_pretrained_model ( model )该模型生成变压器的隐藏状态。您可以在model_pytorch.py中使用LMHead类来添加与编码器的权重并获得完整语言模型的解码器。您还可以在model_pytorch.py中使用ClfHead类在变压器之上添加分类器,并如OpenAI出版物中所述获取分类器。 (请参阅__________py的__main__函数中的两个示例)
要使用变压器的位置编码器,应使用utils.py的encode_dataset()函数编码数据集。请参阅train.py中__main__功能的开头,以查看如何正确定义词汇并编码数据集。
该模型也可以按照Openai论文中详细介绍的分类器集成。训练代码在train.py中包含了关于rocstories的微调任务的一个示例。
可以从关联的网站下载Rocstories数据集。
与TensorFlow代码一样,该代码实现了Rocstories在论文中报告的cloze测试结果,该结果可以通过运行来复制:
python -m spacy download en
python train.py --dataset rocstories --desc rocstories --submit --analysis --data_dir [path to data here]在Rocstories上为3个时期的Pytorch模型进行填充需要10分钟才能在单个NVIDIA K-80上运行。
该Pytorch版本的单次运行测试精度为85.84%,而作者报告的张力量代码为85.8%,而论文报告的最佳单次运行精度为86.5%。
作者实现使用8 GPU,因此可以容纳64个样本的批次,而本实现为单个GPU,因此出于内存原因,在K80上仅限于20个实例。在我们的测试中,将批处理大小从8个样品增加到20个样品将测试准确性提高了2.5分。通过使用多GPU设置(尚未尝试)可以获得更好的精度。
Rocstories数据集上的先前的SOTA为77.6%(Chaturvedi等人的“隐藏连贯模型”出版在“故事理解中”,用于预测下一步发生的事情“ EMNLP 2017,这也是一张非常好的论文!)


