dalle flow
1.0.0


人类在线?从文本创建高清图像的工作流程
dall·e流是一种交互式工作流程,用于从文本提示中生成高清图像。首先,它利用dall·e-mega,Glid-3 XL和稳定的扩散来生成象征候选者,然后调用剪辑 - 服务以对候选者的提示进行排名。首选的候选者被喂入GLID-3 XL进行扩散,这通常会丰富质地和背景。最后,候选人通过Swinir将候选人提升到1024x1024。
DALL·E流是用Jina在客户端服务器体系结构中构建的,这使其具有很高的可扩展性,非阻滞流和现代的Pythonic界面。客户端可以通过TLS通过GRPC/WebSocket/HTTP与服务器进行交互。
为什么要在循环中?生成艺术是一个创造过程。尽管达尔·e释放了人们的创造力的最新进展,但拥有单个单独的输出UX/UI将想象力锁定在单一可能性上,无论这个单一的结果多么好,这都是不好的。通过将生成艺术形式化为迭代程序,dall·e流是单线的替代方法。
dall·e流在客户端服务器体系结构中。
grpcs://api.clip.jina.ai:2096 (需要jina >= v3.11.0 ),您需要首先从这里获得访问权限。有关更多详细信息,请参阅使用剪贴即服务。flow_parser.py中启用标志。grpcs://dalle-flow.dev.jina.ai 。现在,所有连接都使用TLS加密,请重新打开Google Colab中的笔记本。p2.x8large实例上可以再现。ViT-L/14@336px , steps 100->200 。
比较苹果和橙子的科学家")








")

的中世纪油画以表现主义的方式下棋时感到满意")





曾在古董黑白摄影中担任奥地利皇帝")







用美丽的花朵和水果制成的骑士,以syd brak的风格")





















使用客户非常容易。以下步骤最好在Jupyter Notebook或Google Colab中运行。
您需要先安装Docarray和Jina:
pip install " docarray[common]>=0.13.5 " jina我们为您提供了一台演示服务器:
配x 由于大量要求,我们的服务器可能会延迟响应。但是,我们对保持正常运行时间的高度有信心。您还可以在此处遵循指令来部署自己的服务器。
server_url = 'grpcs://dalle-flow.dev.jina.ai'现在,让我们定义提示:
prompt = 'an oil painting of a humanoid robot playing chess in the style of Matisse'让我们将其提交给服务器并可视化结果:
from docarray import Document
doc = Document ( text = prompt ). post ( server_url , parameters = { 'num_images' : 8 })
da = doc . matches
da . plot_image_sprites ( fig_size = ( 10 , 10 ), show_index = True )在这里,我们生成了24个候选者,从达勒 - 梅加(Dalle-Mega)产生了8个候选者,8个来自GLID3 XL的候选者,以及稳定扩散的8个候选者,这是在num_images中定义的,大约需要约2分钟。如果对您来说太长,则可以使用较小的值。

24个候选人用剪贴画和服务对象进行排序,索引0是由Clip评判的最佳候选人。当然,您可能会有所不同。注意左上角的数字吗?选择您最喜欢的一个并获得更好的视图:
fav_id = 3
fav = da [ fav_id ]
fav . embedding = doc . embedding
fav . display ()
现在,让我们将选定的候选物提交到服务器以进行扩散。
diffused = fav . post ( f' { server_url } ' , parameters = { 'skip_rate' : 0.5 , 'num_images' : 36 }, target_executor = 'diffusion' ). matches
diffused . plot_image_sprites ( fig_size = ( 10 , 10 ), show_index = True )这将根据所选图像提供36张图像。您可以通过给skip_rate一个接近零值或接近一个值来迫使其接近给定图像来使模型更具即兴创作。整个过程大约需要约2分钟。

选择您最喜欢的图像,然后仔细观察:
dfav_id = 34
fav = diffused [ dfav_id ]
fav . display ()
最后,提交到最后一步的服务器:将其提升到1024 x 1024px。
fav = fav . post ( f' { server_url } /upscale' )
fav . display ()就是这样!这是一个。如果不满意,请重复该程序。

顺便说一句,docarray是一个强大且易于使用的数据结构,用于非结构化数据。对于在跨/多模式域工作的数据科学家来说,它是超级富有成效的。要了解有关docarray的更多信息,请查看文档。
您可以按照以下说明托管自己的服务器。
dall·e流在其峰值处需要一个带有21GB VRAM的GPU。所有服务都被挤进了这个GPU,其中包括(大致)
config.yml ,512x512)以下合理的技巧可用于进一步降低VRAM:
它需要在硬盘驱动器上至少有50GB的空间,主要用于下载验证的型号。
需要高速互联网。下载模型时,慢速/不稳定的互联网可能会引起令人沮丧的超时。
仅测试CPU的环境,可能无法正常工作。 Google Colab可能会投掷OOM,因此也无法正常工作。

如果您已经安装了Jina,则可以通过以下方式生成以上流程图:
# pip install jina
jina export flowchart flow.yml flow.svg如果您想使用稳定的扩散,则首先需要在网站上注册一个帐户,并同意模型的条款和条件。登录后,您可以找到通往此处所需的模型的版本:
compvis / sd-v1-5 inpainting.ckpt
在下载“权重”部分下,单击sd-v1-x.ckpt的链接。写作时的最新权重为sd-v1-5.ckpt 。
DOCKER用户:将此文件放入名为ldm/stable-diffusion-v1的文件夹中,并重命名IT model.ckpt 。仔细按照以下说明进行操作,因为默认情况下未启用SD。
本地用户:将此文件放入dalle/stable-diffusion/models/ldm/stable-diffusion-v1/model.ckpt中,完成“本地运行”下的其余步骤后。仔细按照以下说明进行操作,因为默认情况下未启用SD。
我们提供了可以直接拉动的预制码头图像。
docker pull jinaai/dalle-flow:latest我们提供了一个Dockerfile,该码头使您可以将服务器从框中运行。
我们的Dockerfile将CUDA 11.6用作基本图像,您可能需要根据系统进行调整。
git clone https://github.com/jina-ai/dalle-flow.git
cd dalle-flow
docker build --build-arg GROUP_ID= $( id -g ${USER} ) --build-arg USER_ID= $( id -u ${USER} ) -t jinaai/dalle-flow .该建筑将需要10分钟的平均互联网速度,这将导致18GB Docker的图像。
要运行它,只需做:
docker run -p 51005:51005
-it
-v $HOME /.cache:/home/dalle/.cache
--gpus all
jinaai/dalle-flow另外,您也可以使用一些启用或禁用的工作流程运行,以防止内存外崩溃。为此,通过以下环境变量之一:
DISABLE_DALLE_MEGA
DISABLE_GLID3XL
DISABLE_SWINIR
ENABLE_STABLE_DIFFUSION
ENABLE_CLIPSEG
ENABLE_REALESRGAN
例如,如果您想禁用GLID3XL工作流,请运行:
docker run -e DISABLE_GLID3XL= ' 1 '
-p 51005:51005
-it
-v $HOME /.cache:/home/dalle/.cache
--gpus all
jinaai/dalle-flow-v $HOME/.cache:/root/.cache避免在每个Docker运行中下载重复的模型。-p 51005:51005的第一部分是您的主机公共端口。如果您公开服务,请确保人们可以访问此端口。其第二个标准杆是Flow.yml中定义的端口。ENABLE_STABLE_DIFFUSION手动启用它。ENABLE_CLIPSEG手动启用它。ENABLE_REALESRGAN手动启用它。 稳定的扩散只有在您下载了权重并使它们作为虚拟卷中提供时,才能启用稳定的扩散,同时为SD启用环境标志( ENABLE_STABLE_DIFFUSION ) 。
您应该以前将权重放入名为ldm/stable-diffusion-v1的文件夹中,并将其标记为model.ckpt 。在下面的YOUR_MODEL_PATH/ldm上替换您的系统中的路径,以将权重输送到Docker映像中。
docker run -e ENABLE_STABLE_DIFFUSION= " 1 "
-e DISABLE_DALLE_MEGA= " 1 "
-e DISABLE_GLID3XL= " 1 "
-p 51005:51005
-it
-v YOUR_MODEL_PATH/ldm:/dalle/stable-diffusion/models/ldm/
-v $HOME /.cache:/home/dalle/.cache
--gpus all
jinaai/dalle-flow您应该在运行后像以下内容一样看到屏幕:
请注意,与本地运行不同,在Docker内部运行可能会提供更少的生动进度键,颜色日志和打印。这是由于码头容器中终端的局限性。它不会影响实际用法。
本地运行需要一些手动步骤,但通常更容易调试。
mkdir dalle && cd dalle
git clone https://github.com/jina-ai/dalle-flow.git
git clone https://github.com/jina-ai/SwinIR.git
git clone --branch v0.0.15 https://github.com/AmericanPresidentJimmyCarter/stable-diffusion.git
git clone https://github.com/CompVis/latent-diffusion.git
git clone https://github.com/jina-ai/glid-3-xl.git
git clone https://github.com/timojl/clipseg.git您应该具有以下文件夹结构:
dalle/
|
|-- Real-ESRGAN/
|-- SwinIR/
|-- clipseg/
|-- dalle-flow/
|-- glid-3-xl/
|-- latent-diffusion/
|-- stable-diffusion/
cd dalle-flow
python3 -m virtualenv env
source env/bin/activate && cd -
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu116
pip install numpy tqdm pytorch_lightning einops numpy omegaconf
pip install https://github.com/crowsonkb/k-diffusion/archive/master.zip
pip install git+https://github.com/AmericanPresidentJimmyCarter/[email protected]
pip install basicsr facexlib gfpgan
pip install realesrgan
pip install https://github.com/AmericanPresidentJimmyCarter/xformers-builds/raw/master/cu116/xformers-0.0.14.dev0-cp310-cp310-linux_x86_64.whl &&
cd latent-diffusion && pip install -e . && cd -
cd stable-diffusion && pip install -e . && cd -
cd SwinIR && pip install -e . && cd -
cd glid-3-xl && pip install -e . && cd -
cd clipseg && pip install -e . && cd -如果您使用的话,我们需要下载几个型号:GLID-3-XL:
cd glid-3-xl
wget https://dall-3.com/models/glid-3-xl/bert.pt
wget https://dall-3.com/models/glid-3-xl/kl-f8.pt
wget https://dall-3.com/models/glid-3-xl/finetune.pt
cd - clipseg和RealESRGAN都要求您设置正确的缓存文件夹路径,通常是$ HOME/。
cd dalle-flow
pip install -r requirements.txt
pip install jax~=0.3.24现在,您在dalle-flow/下,运行以下命令:
# Optionally disable some generative models with the following flags when
# using flow_parser.py:
# --disable-dalle-mega
# --disable-glid3xl
# --disable-swinir
# --enable-stable-diffusion
python flow_parser.py
jina flow --uses flow.tmp.yml您应该立即看到此屏幕:

首先,下载DALL·E Mega型号和其他必要型号将需要〜8分钟。程序运行只需大约1分钟即可传达成功消息。
当一切准备就绪时,您会看到:
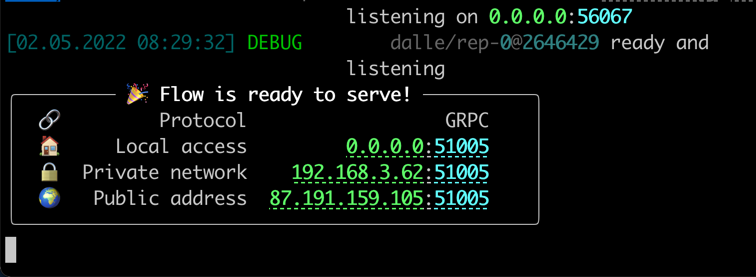
恭喜!现在,您应该能够运行客户端。
您可以根据需要修改和扩展服务器流量,例如更改模型,添加持久性,甚至自动启动到Instagram/opensea。使用Jina和Docarray,您可以轻松地制作dall·e Flow Cloud-native并准备生产。
为了减少VRAM的使用情况,您可以将CLIP-as-service用作外部执行程序,可在grpcs://api.clip.jina.ai:2096 。
首先,确保您从控制台网站或CLI创建了一个访问令牌,如下
jina auth token create < name of PAT > -e < expiration days >然后,您需要从flow.yml更改执行者相关的配置( host , port , external , tls和grpc_metadata )。
...
- name : clip_encoder
uses : jinahub+docker://CLIPTorchEncoder/latest-gpu
host : ' api.clip.jina.ai '
port : 2096
tls : true
external : true
grpc_metadata :
authorization : " <your access token> "
needs : [gateway]
...
- name : rerank
uses : jinahub+docker://CLIPTorchEncoder/latest-gpu
host : ' api.clip.jina.ai '
port : 2096
uses_requests :
' / ' : rank
tls : true
external : true
grpc_metadata :
authorization : " <your access token> "
needs : [dalle, diffusion]您也可以使用flow_parser.py自动生成并使用CLIP-as-service作为外部执行程序来生成和运行流程:
python flow_parser.py --cas-token " <your access token>'
jina flow --uses flow.tmp.yml
配x grpc_metadata仅在Jinav3.11.0之后可用。如果您使用的是旧版本,请升级到最新版本。
现在,您可以在流中使用免费的CLIP-as-service 。
DALL·E流由Jina AI支持,并在Apache-2.0下获得许可。我们正在积极雇用AI工程师,解决方案工程师,以开放源代码构建下一个神经搜索生态系统。


