rag experiment accelerator
1.0.0
RAG实验加速器是一种多功能工具,可帮助您使用Azure AI搜索和抹布模式进行实验和评估。本文档提供了一份全面的指南,涵盖了您需要了解的有关此工具的所有信息,例如其目的,功能,安装,用法等。
RAG实验加速器的主要目标是使对搜索查询的实验和评估以及OpenAI的响应质量进行实验和评估变得更加容易,更快。该工具对想要:的研究人员,数据科学家和开发人员有用:
2024年3月18日:添加了内容采样。此功能将允许数据集通过指定百分比进行采样。数据由内容聚集,然后将样品百分比在每个群集上占据,以尝试分布采样数据。
这样做是为了确保样本中的代表性结果,使整个数据集都可以跨越。
注意:如果由于新的依赖性,建议您在使用此工具之前使用此工具,建议重建环境。
RAG实验加速器是配置驱动器的,并提供了丰富的功能以支持其目的:
实验设置:您可以通过指定一系列搜索引擎参数,搜索类型,查询集和评估指标来定义和配置实验。
集成:它与Azure AI搜索,Azure机器学习,MLFlow和Azure OpenAI无缝集成。
丰富的搜索索引:它基于配置文件中可用的高参数配置创建多个搜索索引。
多个文档加载程序:该工具支持多个文档加载程序,包括通过Azure文档智能和基本的Langchain加载器加载。这使您可以灵活地尝试使用不同的提取方法并评估其有效性。
自定义文档智能加载程序:在为文档智能选择“预构建式Layout” API模型时,该工具会使用自定义文档智能加载程序加载数据。此自定义装载机支持将表格的格式化为列表的格式化为键值对(以增强LLM的可读性),不包括LLM的文件中不相关的部分(例如页码和页脚),可以使用REGEX等删除文件中的重复模式。由于每个表行被转换为文本行,以避免在中间打破一行,因此块由段落和行进行递归完成。自定义加载程序求助于“预先构建的layout”失败时,将较简单的“预构建layout” API模型作为后备。任何其他API模型都将利用Langchain的实现,该实现返回文档Intelligence API的原始响应。
查询生成:该工具可以生成各种可定制的查询集,可以针对特定的实验需求进行量身定制。
多种搜索类型:它支持多种搜索类型,包括纯文本,纯向量,跨矢量,多向量,混合动力等。这使您能够对搜索功能和结果进行全面分析。
子查询:模式评估用户查询,如果发现它足够复杂,则将其分解为较小的子查询以生成相关的上下文。
重新排列:使用LLM重新评估Azure AI搜索的查询响应,并根据查询和上下文之间的相关性进行排名。
指标和评估:它支持将生成的答案(实际)与基础真相答案(预期)进行比较的端到端指标,包括基于距离的,余弦和语义相似性指标。它还包括基于组件的指标,以评估使用LLM作为法官(例如上下文召回或回答相关性)的检索和发电性能,以及评估搜索结果的检索指标(例如,k)。
报告生成: RAG实验加速器可自动化报告生成的过程,并具有可视化效果,使得可以易于分析和共享实验结果。
多语言:该工具支持语言分析仪在单个语言上提供语言支持,并为搜索索引上的用户定义模式提供专业的(语言 - 敏捷)分析仪。有关更多信息,请参见分析仪的类型。
采样:如果您有一个较大的数据集和/或想加快实验,则可以使用采样过程来为指定百分比创建一个小但代表性的数据样本。数据将由内容聚集,每个群集中的一个百分比将作为样本的一部分。获得的结果应大致指示〜10%的边距内的完整数据集。一旦确定了方法,建议在完整数据集上运行以进行准确的结果。
目前,可以在本地运行RAG实验加速器,以利用以下一个:
使用开发容器将意味着为您安装了所有必需的软件。这将需要WSL。有关开发容器的更多信息,请访问容器。DEV
在主机计算机上安装以下软件,您将执行部署:
- 对于Windows -Windows Store Ubuntu 22.04.3 LTS
- Docker桌面
- Visual Studio代码
- VS代码扩展名:遥控器
建立WSL的进一步指导可以在此处找到。现在您有了先决条件,可以:
git clone https://github.com/microsoft/rag-experiment-accelerator.git
code .该项目在Vscode中打开后,应该询问您是否想“在开发容器中重新打开此功能”。是的。
如果您愿意,您当然可以在Windows/Mac机器上运行RAG实验加速器;您负责安装正确的工具。按照以下安装步骤:
git clone https://github.com/microsoft/rag-experiment-accelerator.gitconda create -n rag-experiment python=3.11
conda init bash关闭您的终端,打开一个新的终端,然后运行:
conda activate rag-experiment
pip install .az login
az account set --subscription= " <your_subscription_guid> "
az account show有3个选项可以安装所有必需的Azure服务:
该项目支持Azure开发人员CLI。
azd provisionazd up来使用azd provision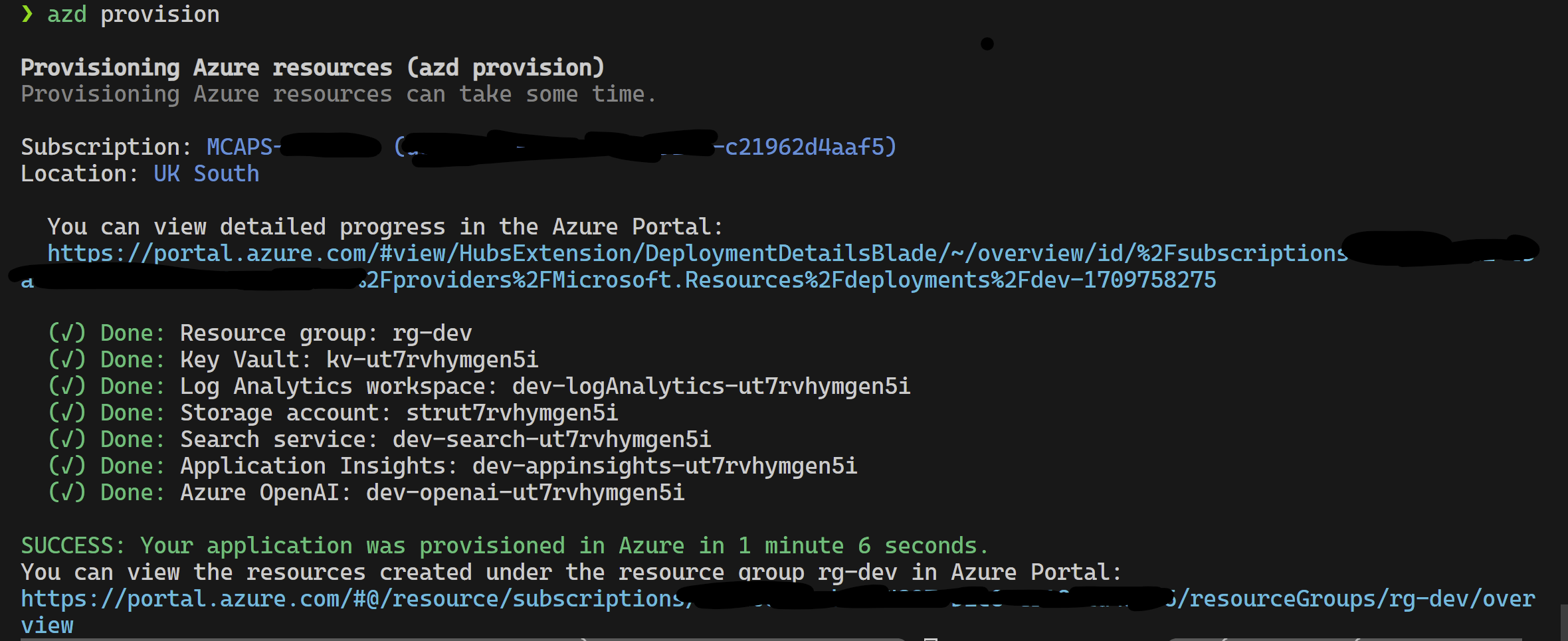
完成此操作后,您可以使用启动配置运行,或者调试4个步骤,而azd提供的当前环境将带有正确的值。
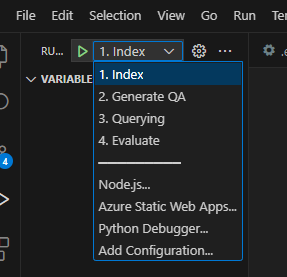
如果要从模板中自己部署基础架构,也可以单击此处:
如果您不想使用azd则可以使用普通的az CLI。
使用以下命令部署。
az login
az deployment sub create --subscription < subscription-id > --location < location > --template-file infra/main.bicep或者
用孤立的网络使用以下命令部署。用隔离网络的细节替换参数值。如果您希望部署到孤立的网络,则必须提供所有三个参数(即vnetAddressSpace , proxySubnetAddressSpace和subnetAddressSpace )。
az login
az deployment sub create --location < location > --template-file infra/main.bicep
--parameters vnetAddressSpace= < vnet-address-space >
--parameters proxySubnetAddressSpace= < proxy-subnet-address-space >
--parameters subnetAddressSpace= < azure-subnet-address-space >这是一个具有参数值的示例:
az deployment sub create --location uksouth --template-file infra/main.bicep
--parameters vnetAddressSpace= ' 10.0.0.0/16 '
--parameters proxySubnetAddressSpace= ' 10.0.1.0/24 '
--parameters subnetAddressSpace= ' 10.0.2.0/24 ' 要在本地使用RAG实验加速器,请按照以下步骤:
将提供的.env.template文件复制到名为.env的文件,并更新所有必需的值。 .env文件的许多必需值将来自以前已配置和/或可以从“配置基础架构”部分中提供的资源收集的资源。另请注意,默认情况下, LOGGING_LEVEL设置为INFO ,但可以更改为以下任何级别: NOTSET , DEBUG , INFO , WARN , ERROR , CRITICAL 。
cp .env.template .env
# change parameters manually将提供的config.sample.json文件复制到名为config.json的文件,然后更改任何超参数以量身定制实验。
cp config.sample.json config.json
# change parameters manually将任何摄入的文件(PDF,HTML,Markdown,Text,JSON或DOCX格式)复制到data文件夹中。
运行01_index.py (Python 01_Index.py)以创建Azure AI搜索索引并加载数据。
python 01_index.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-dd " The directory holding the data. Defaults to data "
-cf " JSON config filename. Defaults to config.json "运行02_qa_generation.py (python 02_qa_generation.py)使用Azure OpenAI生成问题 - 答案对。
python 02_qa_generation.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-dd " The directory holding the data. Defaults to data "
-cf " JSON config filename. Defaults to config.json "运行03_querying.py (Python 03_querying.py)以查询Azure AI搜索以在上下文中生成上下文,重新排名项目,并使用新上下文从Azure OpenAI中获取响应。
python 03_querying.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-cf " JSON config filename. Defaults to config.json "运行04_evaluation.py (Python 04_evaluation.py)使用各种方法计算指标,并使用MLFlow Integration在Azure机器学习中生成图表和报告。
python 04_evaluation.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-cf " JSON config filename. Defaults to config.json "另外,您可以使用Azure ML管道运行上述步骤(除02_qa_generation.py )。为此,请在此处遵循指南。
采样将在本地运行,以创建一个小但代表性的数据切片。这有助于快速实验并降低成本。获得的结果应大致指示〜10%的边距内的完整数据集。一旦确定了方法,建议在完整数据集上运行以进行准确的结果。
注意:采样只能在本地运行,在此阶段,在分布式AML计算群集上不支持它。因此,该过程将是在本地运行采样,然后使用生成的样本数据集在AML上运行。
如果您的数据集非常大,并且想运行类似的方法来采样数据,则可以在Microsoft Fabric或Azure Synapse Analytics的数据发现工具包中使用PYSPARK内存中分布式实现。
"sampling" : {
"sample_data" : " Set to true to enable sampling " ,
"only_run_sampling" : " If set to true, this will only run the sampling step and will not create an index or any subsequent steps, use this if you want to build a small sampled dataset to run in AML " ,
"sample_percentage" : " Percentage of the document corpus to sample " ,
"optimum_k" : " Set to 'auto' to automatically determine the optimum cluster number or set to a specific value e.g. 15 " ,
"min_cluster" : " Used by the automated optimum cluster process, this is the minimum number of clusters e.g. 2 " ,
"max_cluster" : " Used by the automated optimum cluster process, this is the maximum number of clusters e.g. 30 " ,
},采样过程将在采样目录中产生以下工件:
job_name命名的目录,该目录包含所采样的文件子集,这些目录可以指定为--data_dir参数,在运行AML上的整个过程时。
"optimum_k": auto配置值设置为自动,则采样过程将尝试自动设置最佳簇数。如果您大致知道数据中存在多少个广泛的内容,则可以覆盖这一点。肘图将在采样文件夹中生成。 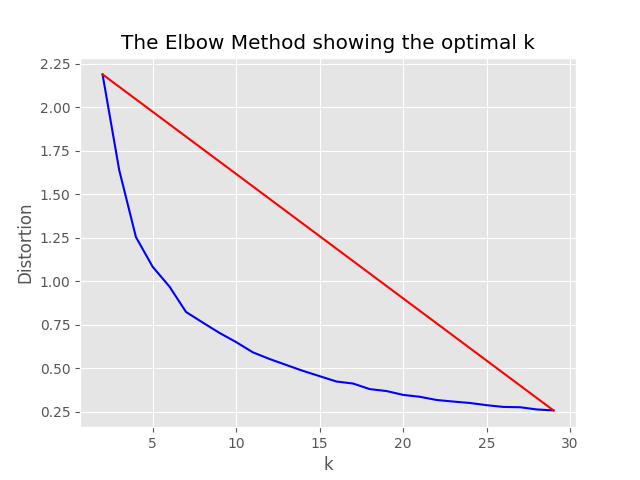
存在两个选项用于运行采样:即:
设置以下值以本地运行索引过程:
"sampling" : {
"sample_data" : true ,
"only_run_sampling" : false ,
"sample_percentage" : 10 ,
"optimum_k" : auto,
"min_cluster" : 2 ,
"max_cluster" : 30
},如果only_run_sampling配置值设置为true,则只能运行采样步骤,不会创建索引,并且任何其他后续步骤均未执行。将--data_dir参数设置为由采样过程创建的目录,该过程将是:
artifacts/sampling/config.[job_name]并执行AML管道步骤。
所有值都可以是元素列表。包括嵌套配置。当方法flatten()在特定节点上调用方法时,每个数组都会产生平面配置的组合,以选择1个随机组合 - 调用方法sample() 。
{
"experiment_name" : " If provided, this will be the experiment name in Azure ML and it will group all job run under the same experiment, otherwise (if left empty) index_name_prefix will be used and there may be more than one experiment " ,
"job_name" : " If provided, all jobs runs in Azure ML will be named with this property value plus timestamp, otherwise (if left empty) each job with be named only with timestamp " ,
"job_description" : " You may provide a description for the current job run which describes in words what you are about to experiment with " ,
"data_formats" : " Specifies the supported data formats for the application. You can choose from a variety of formats such as JSON, CSV, PDF, and more. [*] - means all formats included " ,
"main_instruction" : " Defines the main instruction prompt coming with queries to LLM " ,
"use_checkpoints" : " A boolean. If true, enables use of checkpoints to load data and skip processing that was already done in previous executions. " ,
"index" : {
"index_name_prefix" : " Search index name prefix " ,
"ef_construction" : " ef_construction value determines the value of Azure AI Search vector configuration. " ,
"ef_search" : " ef_search value determines the value of Azure AI Search vector configuration. " ,
"chunking" : {
"preprocess" : " A boolean. If true, preprocess documents, split into smaller chunks, embed and enrich them, and finally upload documents chunks for retrieval into Azure Search Index. " ,
"chunk_size" : " Size of each chunk e.g. [500, 1000, 2000] " ,
"overlap_size" : " Overlap Size for each chunk e.g. [100, 200, 300] " ,
"generate_title" : " A boolean. If true, a title is generated for the chunk of content and an embedding is created for it " ,
"generate_summary" : " A boolean. If true, a summary is generated for the chunk of content and an embedding is created for it " ,
"override_content_with_summary" : " A boolean. If true, The chunk content is replaced with its summary " ,
"chunking_strategy" : " determines the chunking strategy. Valid values are 'azure-document-intelligence' or 'basic' " ,
"azure_document_intelligence_model" : " represents the Azure Document Intelligence Model. Used when chunking strategy is 'azure-document-intelligence'. When set to 'prebuilt-layout', provides additional features (see above) "
},
"embedding_model" : " see 'Description of embedding models config' below " ,
"sampling" : {
"sample_data" : " Set to true to enable sampling " ,
"percentage" : " Percentage of the document corpus to sample " ,
"optimum_k" : " Set to 'auto' to automatically determine the optimum cluster number or set to a specific value e.g. 15 " ,
"min_cluster" : " Used by the automated optimum cluster process, this is the minimum number of clusters e.g. 2 " ,
"max_cluster" : " Used by the automated optimum cluster process, this is the maximum number of clusters e.g. 30 "
}
},
"language" : {
"analyzer" : {
"analyzer_name" : " name of the analyzer to use for the field. This option can be used only with searchable fields and it can't be set together with either searchAnalyzer or indexAnalyzer. " ,
"index_analyzer_name" : " name of the analyzer used at indexing time for the field. This option can be used only with searchable fields. It must be set together with searchAnalyzer and it cannot be set together with the analyzer option. " ,
"search_analyzer_name" : " name of the analyzer used at search time for the field. This option can be used only with searchable fields. It must be set together with indexAnalyzer and it cannot be set together with the analyzer option. This property cannot be set to the name of a language analyzer; use the analyzer property instead if you need a language analyzer. " ,
"char_filters" : " The character filters for the index " ,
"tokenizers" : " The tokenizers for the index " ,
"token_filters" : " The token filters for the index "
},
"query_language" : " The language of the query. Possible values: en-us, en-gb, fr-fr etc. "
},
"rerank" : {
"enabled" : " determines if search results should be re-ranked. Value values are TRUE or FALSE " ,
"type" : " determines the type of re-ranking. Value values are llm or cross_encoder " ,
"llm_rerank_threshold" : " determines the threshold when using llm re-ranking. Chunks with rank above this number are selected in range from 1 - 10. " ,
"cross_encoder_at_k" : " determines the threshold when using cross-encoding re-ranking. Chunks with given rank value are selected. " ,
"cross_encoder_model" : " determines the model used for cross-encoding re-ranking step. Valid value is cross-encoder/stsb-roberta-base "
},
"search" : {
"retrieve_num_of_documents" : " determines the number of chunks to retrieve from the search index " ,
"search_type" : " determines the search types used for experimentation. Valid value are search_for_match_semantic, search_for_match_Hybrid_multi, search_for_match_Hybrid_cross, search_for_match_text, search_for_match_pure_vector, search_for_match_pure_vector_multi, search_for_match_pure_vector_cross, search_for_manual_hybrid. e.g. ['search_for_manual_hybrid', 'search_for_match_Hybrid_multi','search_for_match_semantic'] " ,
"search_relevancy_threshold" : " the similarity threshold to determine if a doc is relevant. Valid ranges are from 0.0 to 1.0 "
},
"query_expansion" : {
"expand_to_multiple_questions" : " whether the system should expand a single question into multiple related questions. By enabling this feature, you can generate a set of alternative related questions that may improve the retrieval process and provide more accurate results " .,
"query_expansion" : " determines if query expansion feature is on. Value values are TRUE or FALSE " ,
"hyde" : " this feature allows you to experiment with various query expansion approaches which may improve the retrieval metrics. The possible values are 'disabled' (default), 'generated_hypothetical_answer', 'generated_hypothetical_document_to_answer' reference article - Precise Zero-Shot Dense Retrieval without Relevance Labels (HyDE - Hypothetical Document Embeddings) - https://arxiv.org/abs/2212.10496 " ,
"min_query_expansion_related_question_similarity_score" : " minimum similarity score in percentage between LLM generated related queries to the original query using cosine similarly score. default 90% "
},
"openai" : {
"azure_oai_chat_deployment_name" : " determines the Azure OpenAI deployment name " ,
"azure_oai_eval_deployment_name" : " determines the Azure OpenAI deployment name used for evaluation " ,
"temperature" : " determines the OpenAI temperature. Valid value ranges from 0 to 1. "
},
"eval" : {
"metric_types" : " determines the metrics used for evaluation (end-to-end or component-wise metrics using LLMs). Valid values for end-to-end metrics are lcsstr, lcsseq, cosine, jaro_winkler, hamming, jaccard, levenshtein, fuzzy_score, cosine_ochiai, bert_all_MiniLM_L6_v2, bert_base_nli_mean_tokens, bert_large_nli_mean_tokens, bert_large_nli_stsb_mean_tokens, bert_distilbert_base_nli_stsb_mean_tokens, bert_paraphrase_multilingual_MiniLM_L12_v2. Valid values for component-wise LLM-based metrics are llm_answer_relevance, llm_context_precision and llm_context_recall. e.g ['fuzzy_score','bert_all_MiniLM_L6_v2','cosine_ochiai','bert_distilbert_base_nli_stsb_mean_tokens', 'llm_answer_relevance'] " ,
}
}注意:更改配置时,请记住更改:
config.sample.json (示例config将由他人复制)embedding_model是一个数组,其中包含用于使用嵌入模型的配置。嵌入模型type必须是Azure OpenAI模型和sentence-transformer的azure ,用于拥抱句子变压器模型。
{
"type" : " azure " ,
"model_name" : " the name of the Azure OpenAI model " ,
"dimension" : " the dimension of the embedding model. For example, 1536 which is the dimension of text-embedding-ada-002 "
}如果您使用的是除text-embedding-ada-002以外的模型,则必须在dimension字段中指定模型的相应维度;例如:
{
"type" : " azure " ,
"model_name" : " text-embedding-3-large " ,
"dimension" : 3072
}可以在Azure OpenAI服务模型文档中找到不同Azure OpenAI嵌入模型的尺寸。
当使用较新的嵌入式模型(V3)时,您还可以利用它们的支持来缩短嵌入。在这种情况下,指定所需的尺寸数量,并添加shorten_dimensions标志以指示要缩短嵌入。例如:
{
"type" : " azure " ,
"model_name" : " text-embedding-3-large " ,
"dimension" : 256 ,
"shorten_dimensions" : true
}{
"type" : " sentence-transformer " ,
"model_name" : " the name of the sentence transformer model " ,
"dimension" : " the dimension of the model. This field is not required if model name is one of ['all-MiniLM-L6-v2', 'all-mpnet-base-v2', 'bert-large-nli-mean-tokens] "
}在查询中为问题提供了一个假设答案的示例,这是一个假设段落,该假设段落对查询有一个答案,或者产生很少的相关问题可能会改善检索的检索,从而获得更准确的文档块以传递到LLM上下文中。基于参考文章 - 精确的零射击密集检索,没有相关性标签(Hyde-假设文件嵌入)。
以下配置选项在此实验方法上打开:
{
"hyde" : " generated_hypothetical_answer "
}{
"hyde" : " generated_hypothetical_document_to_answer "
}此功能将产生相关的问题,过滤少于min_query_expansion_related_question_similarity_score from原始查询(使用余弦相似性得分),以及每个搜索文档的搜索文档,以及原始查询,将结果与原始疑问,DEDUPERTICT结果归还给Reranker和Top K步骤。
min_query_expansion_related_question_similarity_score的默认值设置为90%,您可以在config.json中更改此此事。
{
"query_expansion" : true ,
"min_query_expansion_related_question_similarity_score" : 90
}该解决方案与Azure机器学习集成在一起,并使用MLFlow来管理实验,作业和工件。您可以将以下报告视为评估过程的一部分:
all_metrics_current_run.html显示了每个选定的度量标准的问题和搜索类型的平均分数:
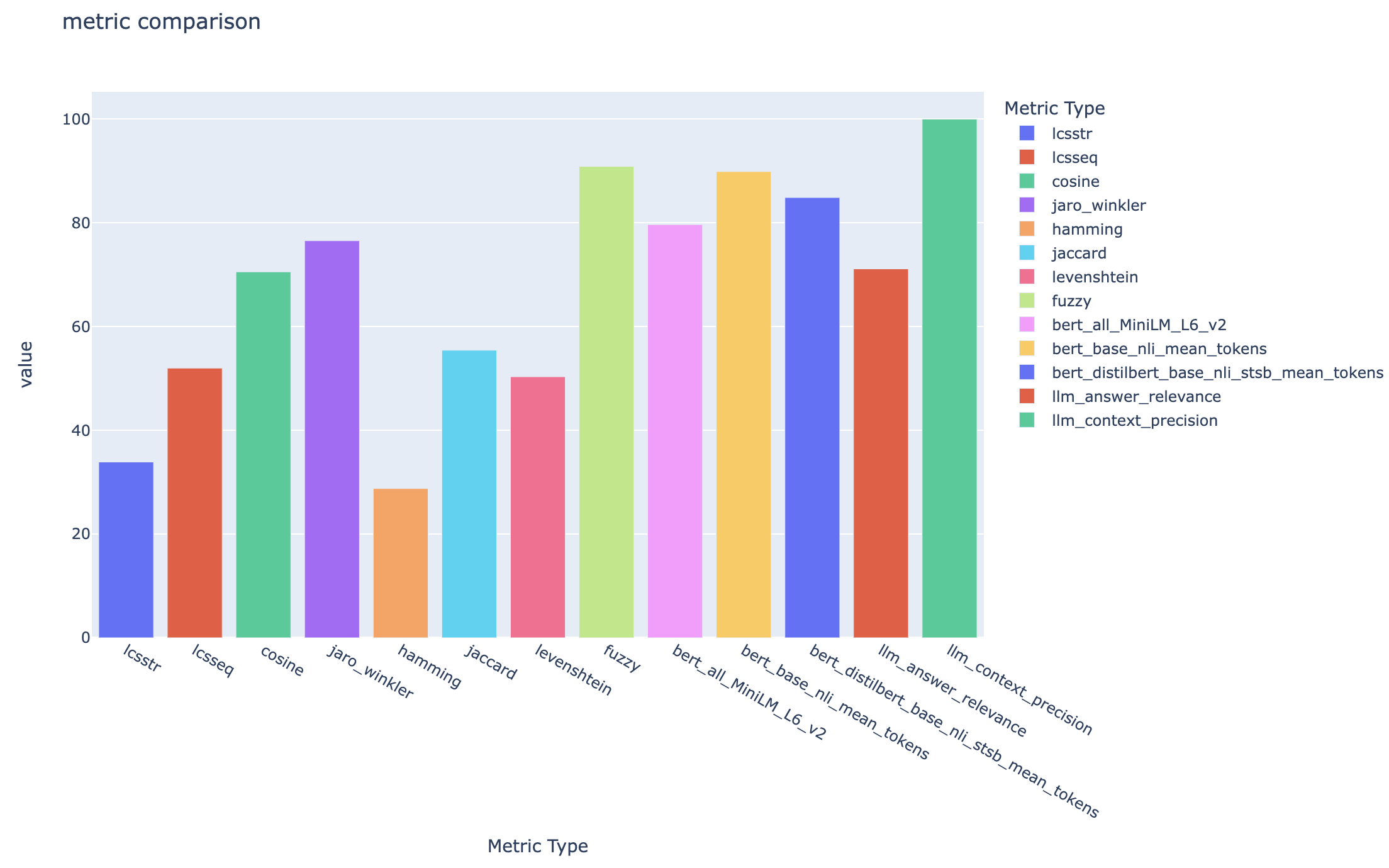
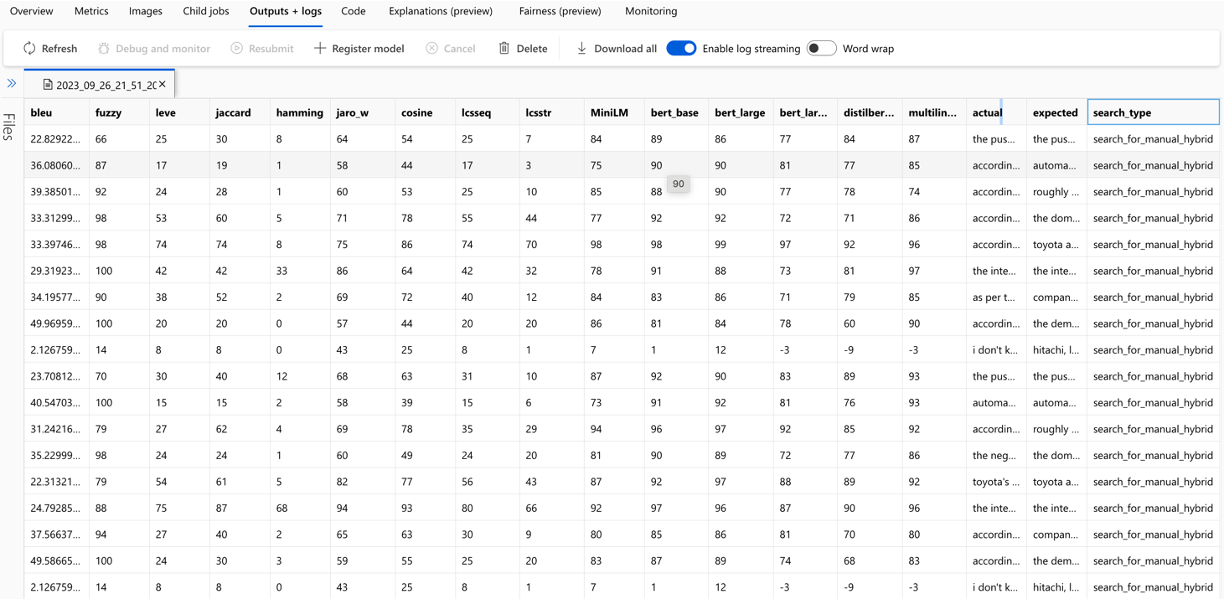
每个问题都跟踪用于评估的每个度量和字段的计算,并在输出CSV文件中进行搜索类型:
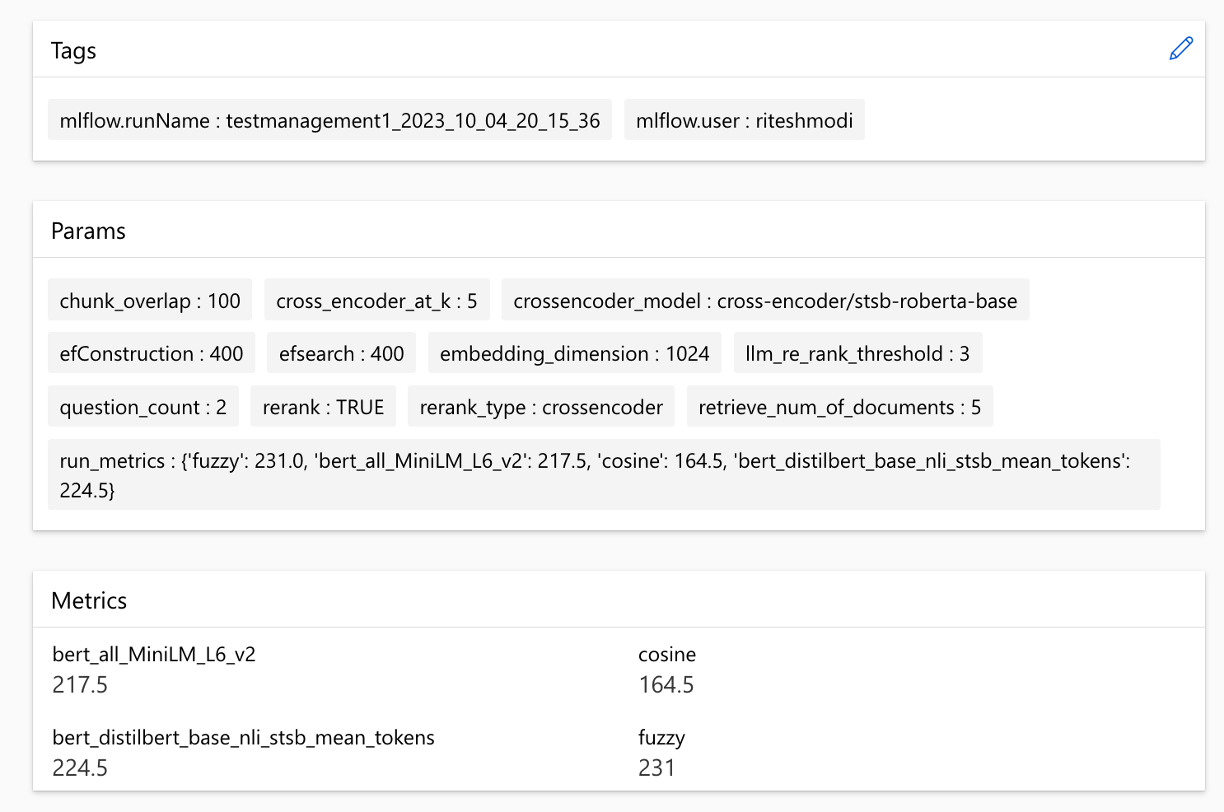
可以在跨行程中比较指标:
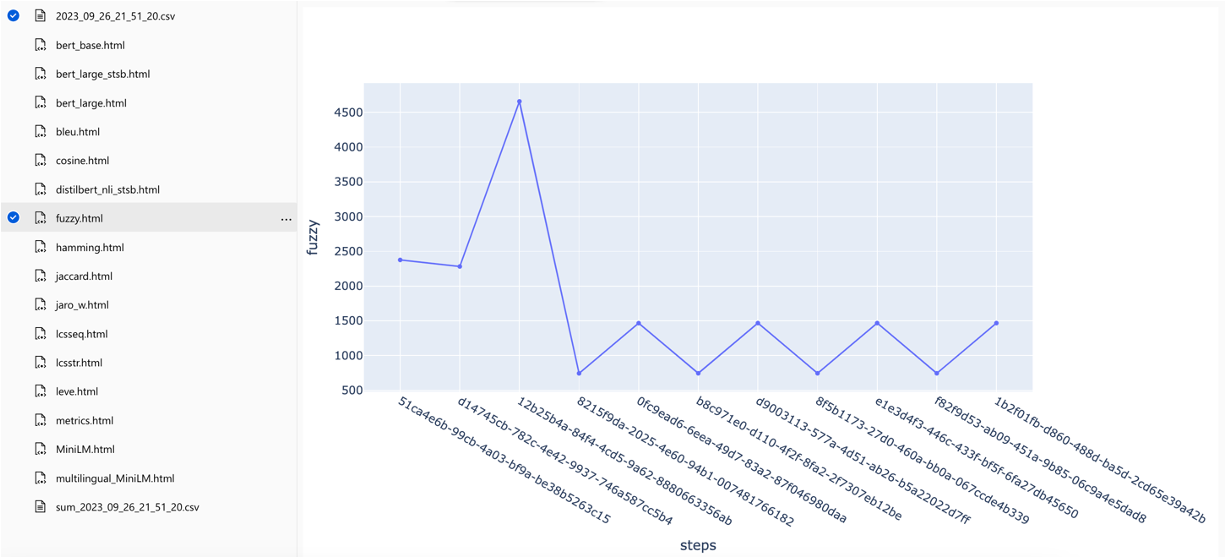
可以在不同的搜索策略中比较指标:
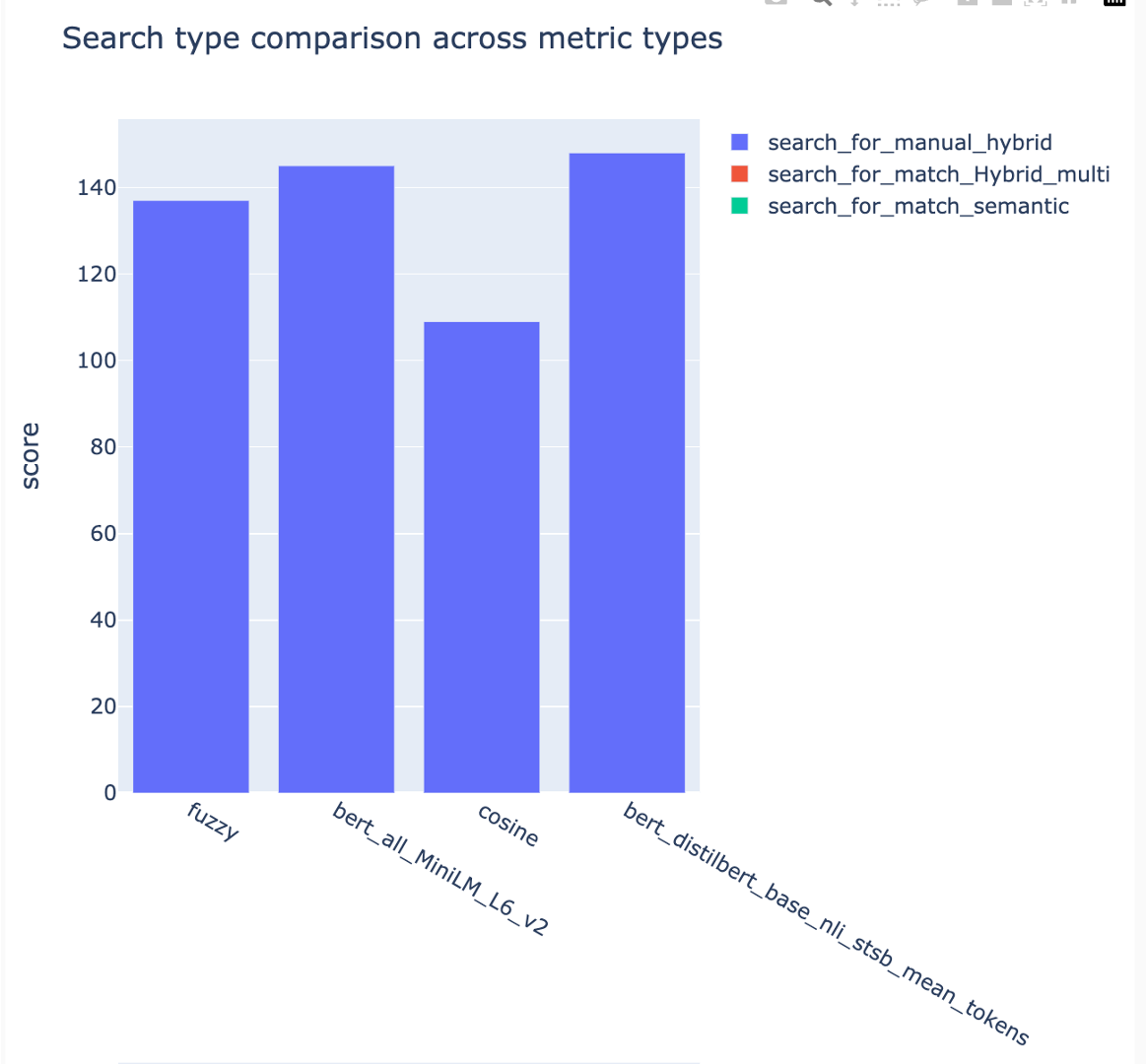
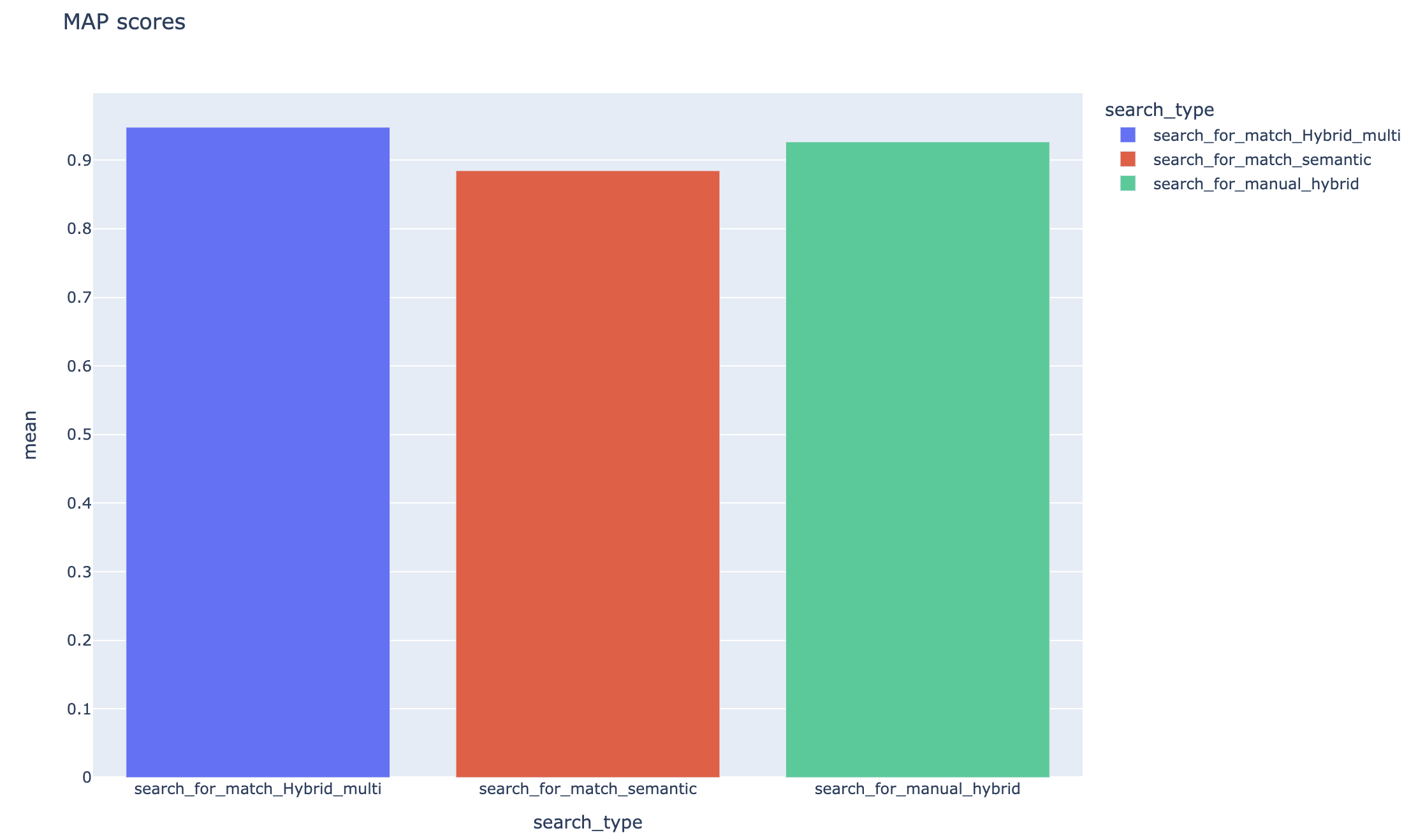
跟踪平均平均精度分数,可以在搜索类型中比较平均地图得分:
本节概述了工程师/开发人员/数据科学家在使用RAG实验加速器时可能会遇到的常见陷阱或陷阱。
要成功利用此解决方案,您必须首先通过登录Azure帐户来验证自己。此基本步骤可确保您拥有访问和管理其使用的Azure资源所需的权限。您可能会出现与将QNA数据存储到Azure Machine学习数据资产中,由于不适当的授权和对Azure的身份验证而执行查询和评估步骤的错误。有关身份验证和授权,请参阅本文档中的第4点。
在某些情况下,尽管有效的身份验证和授权,解决方案仍然会产生错误。在这种情况下,使用步骤4中提到的步骤开始使用全新的终端实例开始新的会话,并检查用户是否有助于访问与解决方案相关的Azure资源。
该解决方案利用config.json中的几个配置参数,它们直接影响其功能和性能。请密切注意这些设置:
retireve_num_of_documents:此配置控制以进行分析的初始文档数量。由于搜索AI结果的等级处理,过高或低值可能导致“索引超出范围”错误。
Cross_encoder_at_k:此配置会影响排名过程。高价值可能导致最终结果中包含无关的文档。
llm_rerank_threshold:此配置确定哪些文档传递给语言模型(LLM)以进行进一步处理。设置此值太高可能会为LLM创造一个过于较大的上下文,可能导致处理错误或降级结果。这也可能导致Azure OpenAI端点的例外。
在运行此解决方案之前,请确保您在config.json文件中正确设置了Azure OpenAI部署名称,并将相关秘密添加到环境变量(.ENV文件)中。此信息对于应用于设计的适当Azure OpenAI资源和功能的应用程序至关重要。如果您不确定配置数据,请参阅.env.template和config.json文件。该解决方案已通过GPT 3.5涡轮模型进行了测试,需要对任何其他模型进行进一步测试。
在QNA生成步骤中,您有时可能会遇到与Azure Openai收到的JSON输出有关的错误。这些错误可以阻止成功产生一些问题和答案。这是您需要知道的:
格式不正确: Azure OpenAI的JSON输出可能不遵守预期格式,从而导致QNA生成过程问题。内容过滤: Azure OpenAi已有内容过滤器。如果认为输入文本或生成的响应是不合适的,则可能导致错误。 API限制: Azure OpenAI服务具有影响输出的代币和速率限制。
端到端评估指标:并非所有比较生成的和地面答案的指标都能够捕获语义上的差异。例如,诸如levenshtein或jaro_winkler之类的指标仅测量编辑距离。 cosine指标也不允许使用语义的比较:它使用基于术语频率向量的基于文本令牌的实现。为了计算生成的答案与预期响应之间的语义相似性,请考虑使用基于嵌入的指标(例如BERT分数( bert_ ))。
组件评估指标:使用LLM-AS判断的评估指标不是确定性的。加速器中包含的llm_指标使用azure_oai_eval_deployment_name配置字段中指示的模型。 llm_context_recall_instruction llm_answer_relevance_instruction用于评估指令的提示, llm_context_precision_instruction包含在prompts.py文件中。
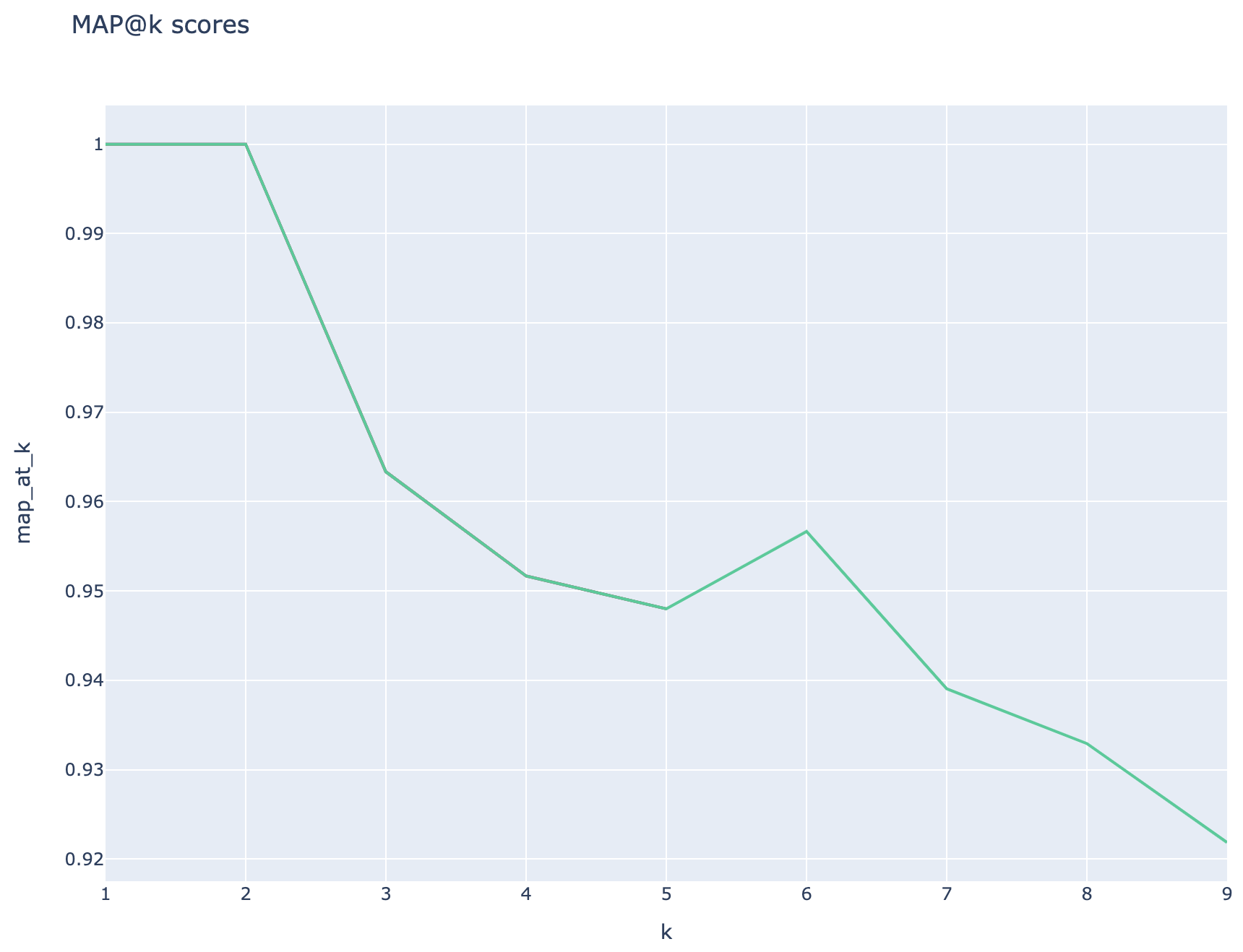
基于检索的指标:地图得分是通过将每个检索的块与用于生成QNA对的块的块进行比较来计算的。为了评估检索到的块是否相关,使用spacyevaluator计算了检索到的块与最终用户问题的串联( 02_qa_generation.py )中使用的块之间的相似性。 Spacy相似性默认为令牌向量的平均值,这意味着该计算对单词的顺序不敏感。默认情况下,相似性阈值设置为80%( spacy_evaluator.py )。
我们欢迎您的贡献和建议。要做出贡献,您需要同意确认您有权并实际上授予我们使用您的贡献的权利的贡献者许可协议(CLA)。有关详细信息,请访问[https://cla.opensource.microsoft.com]。
提交拉动请求时,CLA机器人将自动检查您是否需要提供CLA并给您说明(例如,状态检查,评论)。按照机器人的说明进行操作。您只需要对使用我们CLA的所有存储库进行一次。
在您做出贡献之前,请确保运行
pip install -e .
pre-commit install
该项目遵循Microsoft开源的行为代码。有关更多信息,请参阅《行为守则常见问题准则》,或提供任何疑问或评论,请联系[email protected]。
bug/11-short-descriptionfeature/22-short-descriptionexample_snake_case 。git config --global user.name "First Last"和姓该项目可能包含用于项目,产品或服务的商标或徽标。您必须遵循Microsoft的商标和品牌准则,以正确使用Microsoft商标或徽标。不要在该项目的修改版本中使用Microsoft商标或徽标,以引起混乱或暗示Microsoft赞助。遵循该项目包含的任何第三方商标或徽标的政策。


