super json mode
1.0.0
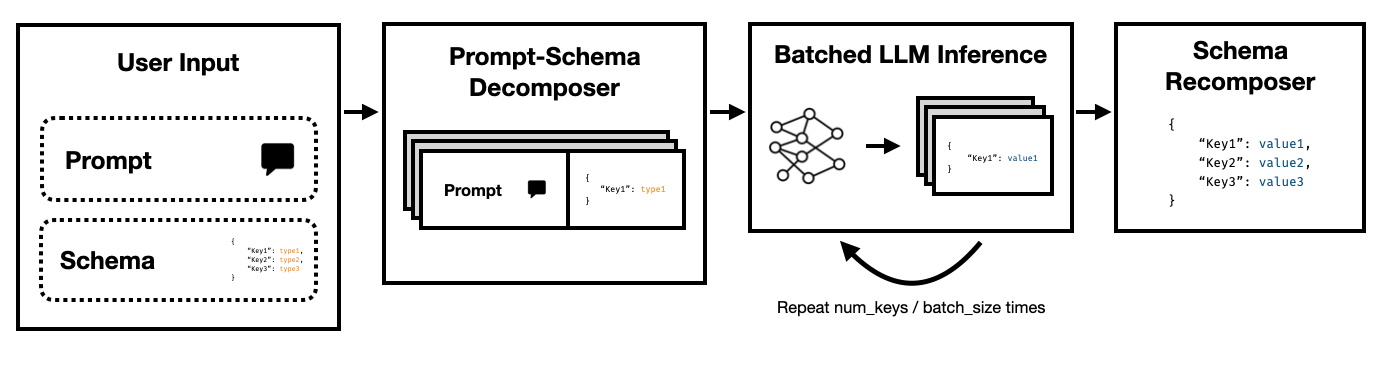
Super JSON模式是一个Python框架,可以通过将目标架构分解为原子组件,然后并行执行世代,从而使LLM有效地创建结构化输出。
它通过OpenAI的遗产完成API和开源LLMS(例如通过拥抱Face Transformers和vllm)来支持最新的LLM。很快就会支持更多的LLM!
与依靠提示和HF变压器的天真JSON生成管道相比,我们发现超级JSON模式可以快速生成10倍的输出。与幼稚的产生相比,它也更确定性,并且不太可能遇到解析问题。
安装很简单: pip install super-json-mode
结构化输出格式(例如JSON或YAML)具有固有的平行或分层结构。
考虑以下非结构化段落(由GPT-4生成):
欢迎来到123 Azure Lane,这是一个令人惊叹的旧金山居所,拥有出色的当代设计,现在以2,500,000美元的价格在市场上。该物业散布在豪华的3,000平方英尺上,结合了精致和舒适,创造了真正独特的生活体验。
我们的独家住宅是一个家庭或专业人士的田园诗般的房屋,配备了五间宽敞的卧室,每个卧室都散发着温暖和现代优雅。精心计划卧室,以允许自然光线和宽敞的存储空间。该住宅拥有三个设计优雅的完整浴室,可为其居民提供便利和隐私。
大入口将您带到一个宽敞的起居区,为聚会或大火安静的夜晚提供了极好的氛围。厨师的厨房包括最先进的电器,定制橱柜和美丽的花岗岩台面,使其成为任何喜欢做饭的人的梦想。
如果我们想使用LLM提取address , square footage , number of bedrooms , number of bathrooms和price ,我们可以根据描述要求模型填充模式。
潜在的模式(例如由pydantic对象产生的模式)看起来像这样:
{
"address": {
"type": "string"
},
"price": {
"type": "number"
},
"square_feet": {
"type": "integer"
},
"num_beds": {
"type": "integer"
},
"num_baths": {
"type": "integer"
}
}
有效的输出看起来像这样:
{
"address": "123 Azure Lane",
"price": 2500000,
"square_feet": 3000,
"num_beds": 5,
"num_baths": 3
}
显而易见的方法是将模式嵌套在提示中,并要求模型填写。这是当前大多数团队当前使用LLMS从非结构化文本中提取结构化输出的方式。
但是,这是出于三个原因而效率低下的。
请注意,这些键中的每个键彼此独立。超级JSON模式通过将模式中的每个键值对作为单独的查询来利用迅速的并行性。例如,我们可以在没有生成address的情况下提取num_baths !
要求模型从头开始生成JSON,不必要地消耗了可预测语法(如括号和键名)上的代币(以及时间),这些语法名称已经预期了。这是我们应该能够用来改善潜伏期的一代人的重要事务。
LLM尴尬地并行,批次运行的查询速度比串行顺序快得多。因此,我们可以在多个查询上将架构拆分。然后,LLM并行填充每个独立键的架构,并在单个通过中发射较少的令牌,从而使推理时间更快。
运行以下命令:
pip install super-json-mode
conda create --name superjsonmode python=3.10 -y
conda activate superjsonmode
git clone https://github.com/varunshenoy/super-json-mode
cd superjsonmode
pip install -r requirements.txt
我们试图使超级JSON模式超级易于使用。有关更多示例和vLLM使用情况,请参见examples文件夹。
使用OpenAI和gpt-3-instruct-turbo :
from superjsonmode . integrations . openai import StructuredOpenAIModel
from pydantic import BaseModel
import time
model = StructuredOpenAIModel ()
class Character ( BaseModel ):
name : str
genre : str
age : int
race : str
occupation : str
best_friend : str
home_planet : str
prompt_template = """{prompt}
Please fill in the following information about this character for this key. Keep it succinct. It should be a {type}.
{key}: """
prompt = """Luke Skywalker is a famous character."""
start = time . time ()
output = model . generate (
prompt ,
extraction_prompt_template = prompt_template ,
schema = Character ,
batch_size = 7 ,
stop = [ " n n " ],
temperature = 0 ,
)
print ( f"Total time: { time . time () - start } " )
# Total Time: 0.409s
print ( output )
# {
# "name": "Luke Skywalker",
# "genre": "Science fiction",
# "age": "23",
# "race": "Human",
# "occupation": "Jedi Knight",
# "best_friend": "Han Solo",
# "home_planet": "Tatooine",
# }将Mistral 7B与HuggingFace Transformers使用:
from transformers import AutoTokenizer , AutoModelForCausalLM
from superjsonmode . integrations . transformers import StructuredOutputForModel
from pydantic import BaseModel
device = "cuda"
model = AutoModelForCausalLM . from_pretrained ( "mistralai/Mistral-7B-Instruct-v0.2" ). to ( device )
tokenizer = AutoTokenizer . from_pretrained ( "mistralai/Mistral-7B-Instruct-v0.2" )
# Create a structured output object
structured_model = StructuredOutputForModel ( model , tokenizer )
passage = """..."""
class QuarterlyReport ( BaseModel ):
company : str
stock_ticker : str
date : str
reported_revenue : str
dividend : str
prompt_template = """[INST]{prompt}
Based on this excerpt, extract the correct value for "{key}". Keep it succinct. It should have a type of `{type}`.[/INST]
{key}: """
output = structured_model . generate ( passage ,
extraction_prompt_template = prompt_template ,
schema = QuarterlyReport ,
batch_size = 6 )
print ( json . dumps ( output , indent = 2 ))
# {
# "company": "NVIDIA",
# "stock_ticker": "NVDA",
# "date": "2023-10",
# "reported_revenue": "18.12 billion dollars",
# "dividend": "0.04"
# } 有很多功能可以使超级JSON模式变得更好。这是一些想法。
定性产出分析:我们运行了性能基准,但是我们应该提出更严格的方法来判断超级JSON模式的定性产出。
结构化采样:理想情况下,我们应该掩盖LLM的逻辑以执行类型的约束,类似于JSONFORMER。那里已经有几个软件包已经这样做了,要么它们应该集成我们并行的JSON生成管道,要么我们应该将其构建为超级JSON模式。
依赖图图支持:超级JSON模式具有非常明显的故障情况:当键对另一键依赖时。考虑一个带有两个钥匙的json斑点, thought和response 。这种所需的输出对于使用大型语言模型进行思考很常见,很明显, response取决于thought 。我们应该能够以依赖关系和批处理提示的形式传递,以完成父量输出并将其传递到子模架项目中。
本地模型支持:超级JSON模式在批处理大小通常为1的本地情况下最有效。您可以利用批处理以减少潜伏期,类似于投机解码。 Llama.CPP是本地型号 + CPU推理的主要框架。如果可能的话,我很想使用Ollama实施此功能。
TRT-LLM支持:VLLM非常易于使用,但理想情况下,我们将其与TRT-LLM(例如TRT-LLM)更具性能的框架集成。
如果您发现图书馆对您的工作有用,请列举此回购,我们将不胜感激:
@misc{ShenoyDerhacobian2024,
author = {Shenoy, Varun and Derhacobian, Alex},
title = {Super JSON Mode: A Framework for Accelerated Structured Output Generation},
year = {2024},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/varunshenoy/super-json-mode}}
}
该项目是为CS 229:机器学习的系统构建的。非常感谢教学团队和TAS在整个项目中的指导。


