Apache Kylin分析型資料倉儲v4.0.3 正式版
4.0.3
Apache Kylin:超大規模資料的亞秒查詢利器
Downcodes小編
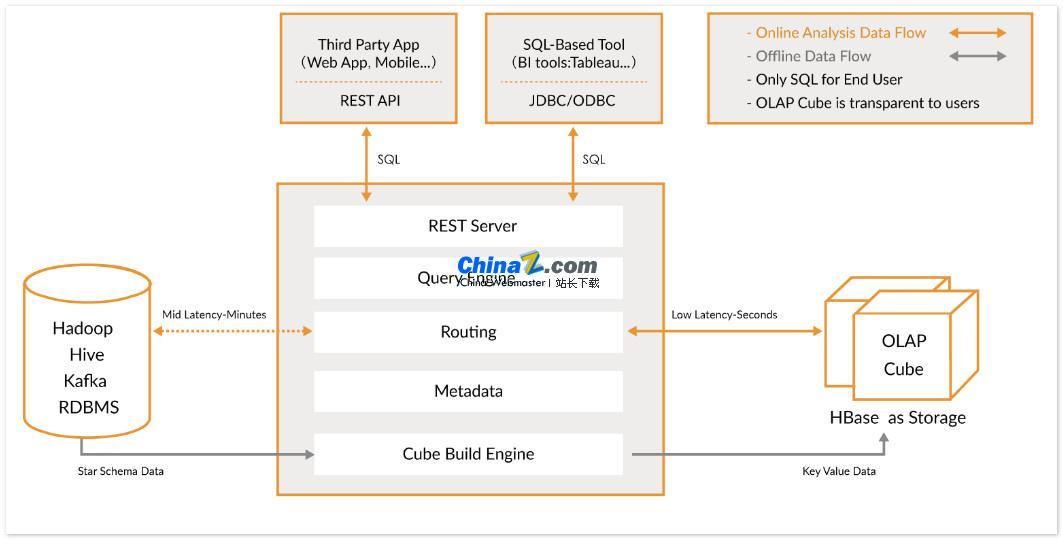
Apache Kylin 是一個開源的、分散式的分析型資料倉庫,它提供Hadoop/Spark 之上的SQL 查詢介面和多維分析(OLAP) 能力,可以有效率地處理超大規模資料。最初由eBay 開發並貢獻給開源社區,它在亞秒級內完成對大量資料的查詢。
Kylin 的三大步驟
Kylin 讓使用者僅需三步,即可實現超大資料集的亞秒級查詢:
1. 定義資料集上的星形或雪花形模型: 首先,你需要定義一個星形或雪花形模型來描述你的資料集。這將有助於Kylin 理解資料之間的關係,從而優化查詢效能。
2. 建構Cube: 在定義的資料表上建構Cube,Cube 是Kylin 進行資料預計算和儲存的單位,可以大幅提升查詢速度。
3. 使用標準SQL 查詢: 透過ODBC、JDBC 或RESTFUL API 使用標準SQL 語法查詢Cube,Kylin 能夠在亞秒級內傳回查詢結果。
Kylin 的整合能力
Kylin 與多種資料視覺化工具集成,例如Tableau、Power BI 等。使用者可以使用這些BI 工具對Hadoop 資料進行分析,直觀地展示資料洞察。
總結
Apache Kylin 是一個強大的工具,它能夠幫助使用者在亞秒級內完成對超大規模資料的查詢。其易用性、可擴展性和高效性使其成為處理大規模數據分析的理想選擇。