
鞠軒1* 、高一鳴1* 、張朝陽1*# 、袁紫陽1 、王新濤1 、曾愛玲、熊宇、徐強、山英1
1騰訊 PCG ARC 實驗室2香港中文大學*同等貢獻#計畫負責人
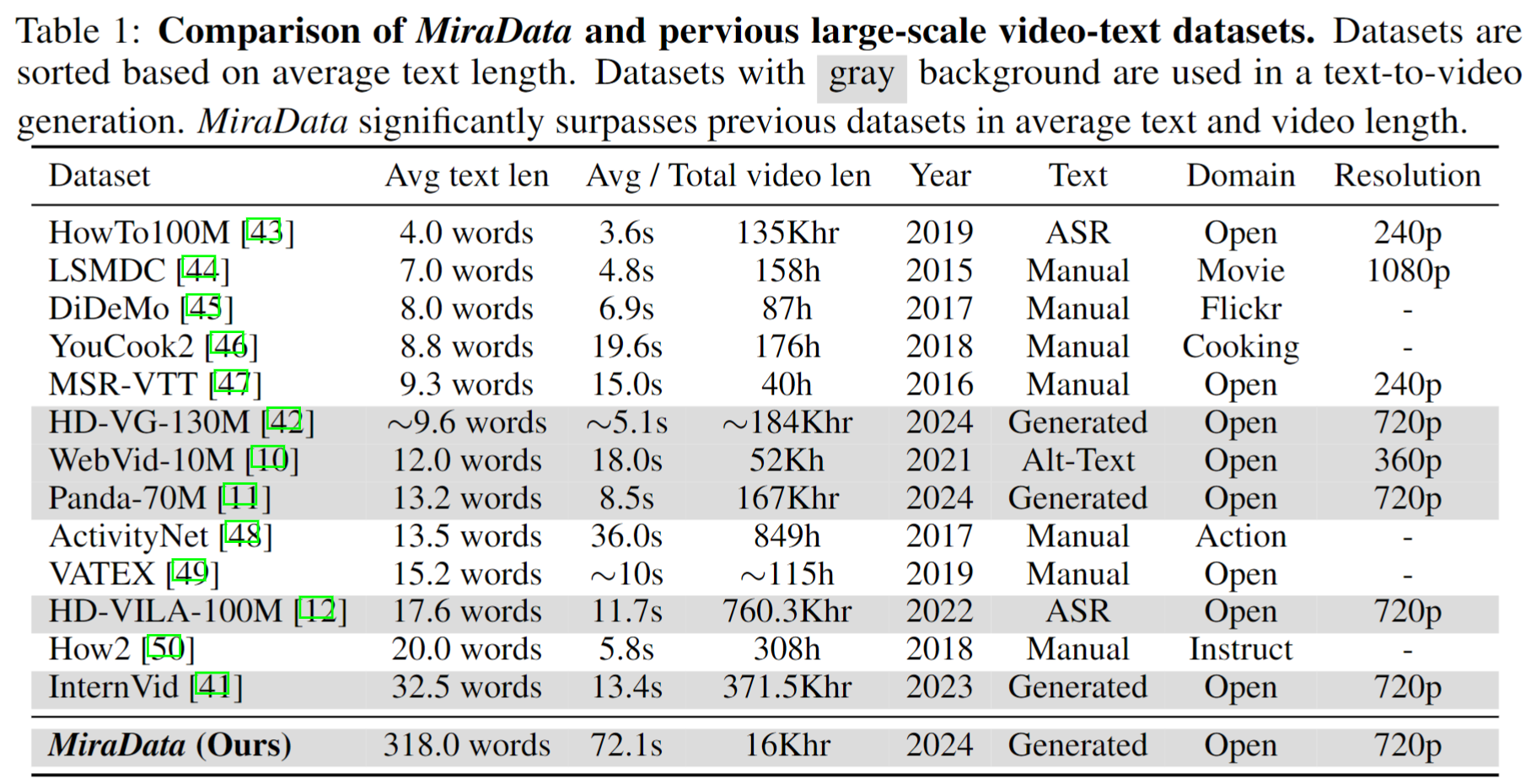
視訊資料集在 Sora 等影片生成中發揮著至關重要的作用。然而,現有的文字視訊資料集在處理長視訊序列和捕獲鏡頭過渡方面往往存在不足。為了解決這些限制,我們引入了MiraData ,這是一個專門為長視訊生成任務設計的視訊資料集。此外,為了更好地評估影片產生中的時間一致性和運動強度,我們引入了MiraBench ,它透過添加 3D 一致性和基於追蹤的運動強度指標來增強現有基準。您可以在我們的研究論文中找到更多詳細資訊。
我們發布了四個版本的 MiraData,包含 330K、93K、42K、9K 資料。
此版本的 MiraData 的元檔案在 Google Drive 和 HuggingFace 資料集中提供。此外,為了更好、更快地了解我們的元文件組成,我們隨機採樣了一組 100 個影片剪輯,可以在此處存取。元文件包含以下索引資訊:
{download_id}.{clip_id}組成若要下載影片並將其分割成剪輯,請先從 Google Drive 或 HuggingFace 資料集下載元檔案。獲得元文件後,您可以使用以下腳本下載影片範例:
python download_data.py --meta_csv {meta file} --download_start_id {the start of download id} --download_end_id {the end of download id} --raw_video_save_dir {the path of saving raw videos} --clip_video_save_dir {the path of saving cutted video}
只要您需要,我們就會從我們的資料集/Github/專案網頁中刪除影片樣本。請聯絡我們提出請求。
為了收集 MiraData,我們首先手動選擇不同場景下的 YouTube 頻道,包括來自 HD-VILA-100M、Videovo、Pixabay 和 Pexels 的影片。然後,使用 PySceneDetect 下載並分割對應頻道中的所有影片。然後我們使用多個模型將短片拼接在一起並過濾掉低品質的影片。接下來,我們選擇了持續時間較長的影片片段。最後,我們使用 GPT-4V 為所有影片剪輯添加了字幕。

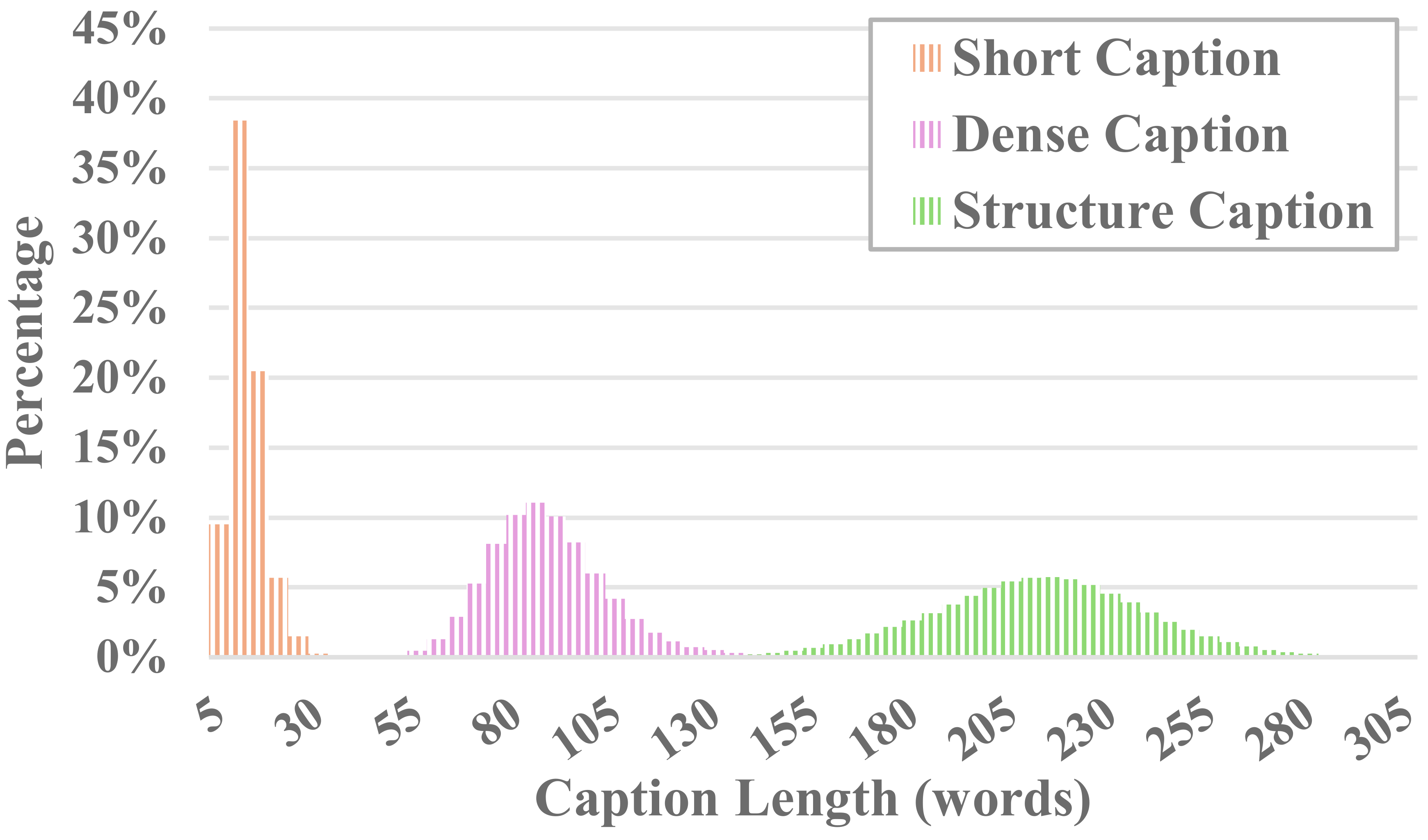
MiraData 中的每個影片都附有結構化字幕。這些標題從不同角度提供了詳細描述,增強了資料集的豐富性。
六種類型的字幕
我們測試了現有的開源視覺LLM方法和GPT-4V,發現GPT-4V的字幕在時間序列方面的語義理解上表現出更好的準確性和連貫性。
為了平衡註釋成本和字幕準確性,我們為每個影片統一採樣 8 幀,並將它們排列成一張大圖像的 2x4 網格。然後,我們使用Panda-70M的字幕模型為每個影片添加一句話字幕,作為主要內容的提示,並將其輸入到我們微調的提示中。透過將微調的提示和 2x4 大圖像輸入 GPT-4V,我們可以在一輪對話中有效地輸出多個維度的字幕。具體提示內容可以在caption_gpt4v.py中找到,歡迎大家貢獻更多優質的文字影片資料。 ?

為了評估長影片生成,我們在MiraBench中從6個角度設計了17個評估指標,包括時間一致性、時間運動強度、3D一致性、視覺品質、文字視訊對齊和分佈一致性。這些指標涵蓋了先前視訊生成模型和文字到視訊基準中使用的大多數常見評估標準。
要評估生成的視頻,請首先透過以下方式設定 python 環境:
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu116
pip install -r requirements.txt
然後,透過以下方式執行評估:
python calculate_score.py --meta_file data/evaluation_example/meta_generated.csv --frame_dir data/evaluation_example/frames_generated --gt_meta_file data/evaluation_example/meta_gt.csv --gt_frame_dir data/evaluation_example/frames_gt --output_folder data/evaluation_example/results --ckpt_path data/ckpt --device cuda
您可以按照data/evaluation_example中的範例來評估您自己產生的影片。
請參閱許可證。
如果您發現該專案對您的研究有用,請引用我們的論文。 ?
@misc{ju2024miradatalargescalevideodataset,
title={MiraData: A Large-Scale Video Dataset with Long Durations and Structured Captions},
author={Xuan Ju and Yiming Gao and Zhaoyang Zhang and Ziyang Yuan and Xintao Wang and Ailing Zeng and Yu Xiong and Qiang Xu and Ying Shan},
year={2024},
eprint={2407.06358},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2407.06358},
}
如有任何疑問,請發送電子郵件[email protected] 。
MiraData 遵循 GPL-v3 許可證,支援商業用途。如果您需要 MiraData 的商業許可,請隨時與我們聯絡。


