bulk
1.0.0
Bulk 是一個快速的開發工具,用於應用一些批量標籤。給定一個帶有二維嵌入的準備好的資料集,它可以產生一個介面,允許您快速添加一些批量(儘管不太精確)註釋。
python -m pip install --upgrade pip
python -m pip install bulk
大量的未來是提供可以在筆記本中為您提供幫助的小部件。目前, BaseTextExplorer是支援的主要小部件。給定一些預處理數據,您可以使用資源管理器來瀏覽文字嵌入的 2D UMAP。
import pandas as pd
from umap import UMAP
from sklearn . pipeline import make_pipeline
# pip install "embetter[text]"
from embetter . text import SentenceEncoder
# Build a sentence encoder pipeline with UMAP at the end.
enc = SentenceEncoder ( 'all-MiniLM-L6-v2' )
umap = UMAP ()
text_emb_pipeline = make_pipeline (
enc , umap
)
# Load sentences
sentences = list ( pd . read_csv ( "tests/data/text.csv" )[ 'text' ])
# Calculate embeddings
X_tfm = text_emb_pipeline . fit_transform ( sentences )
# Write to disk. Note! Text column must be named "text"
df = pd . DataFrame ({ "text" : sentences })
df [ 'x' ] = X_tfm [:, 0 ]
df [ 'y' ] = X_tfm [:, 1 ]要使用該小部件,您只需執行以下命令:
from bulk . widgets import BaseTextExplorer
widget = BaseTextExplorer ( df )
widget . show ()這將使我們能夠快速探索資料中出現的群集。您可以按住滑鼠遊標進入選擇模式,當您選擇項目時,您將看到右側出現隨機子集。您可以透過點擊重新取樣按鈕從您的選擇中重新取樣。
當您做出選擇時,您可以看到右側更新的小部件,但您也可以從 Python 屬性中取得資料。
widget . selected_idx
widget . selected_texts
widget . selected_dataframe能夠探索這些集群是很巧妙的,但感覺如果我們有更多可用的工具,我們可能會更容易探索一切。特別是,我們希望有一個編碼器,以便我們可以在嵌入空間中使用查詢。下面的 UI 將允許我們透過使用文字提示更新顏色來進行更多互動探索。
from embetter . text import SentenceEncoder
enc = SentenceEncoder ( 'all-MiniLM-L6-v2' )
# Pay attention here! The rows in df needs to align with the rows in X!
widget = BaseTextExplorer ( df , X = X , encoder = enc )
widget . show ()借助 ipywidget 和 anywidget 等工具,我們可以真正開始建立一些工具,使筆記本成為滿足您的資料需求的首選位置。如果有一些合適的小部件,您將永遠無法超越 Jupyter 筆記本!
該專案的主要興趣是開發數據品質工具。能夠大量選擇資料點感覺是一個很好的起點。也許您可以先找到一個有趣的子集來註釋,也許當您看到兩個不同的集群應該是一個時,您可能會感到驚訝。所有美好的事情都可以發生在筆記本中!
Bulk 還附帶了一個小型 Web 應用程序,該應用程式使用 Bokeh 為您提供基於 UMAP 嵌入表示的註釋介面。它提供了一個文字介面。該介面是該項目的原始介面/功能。
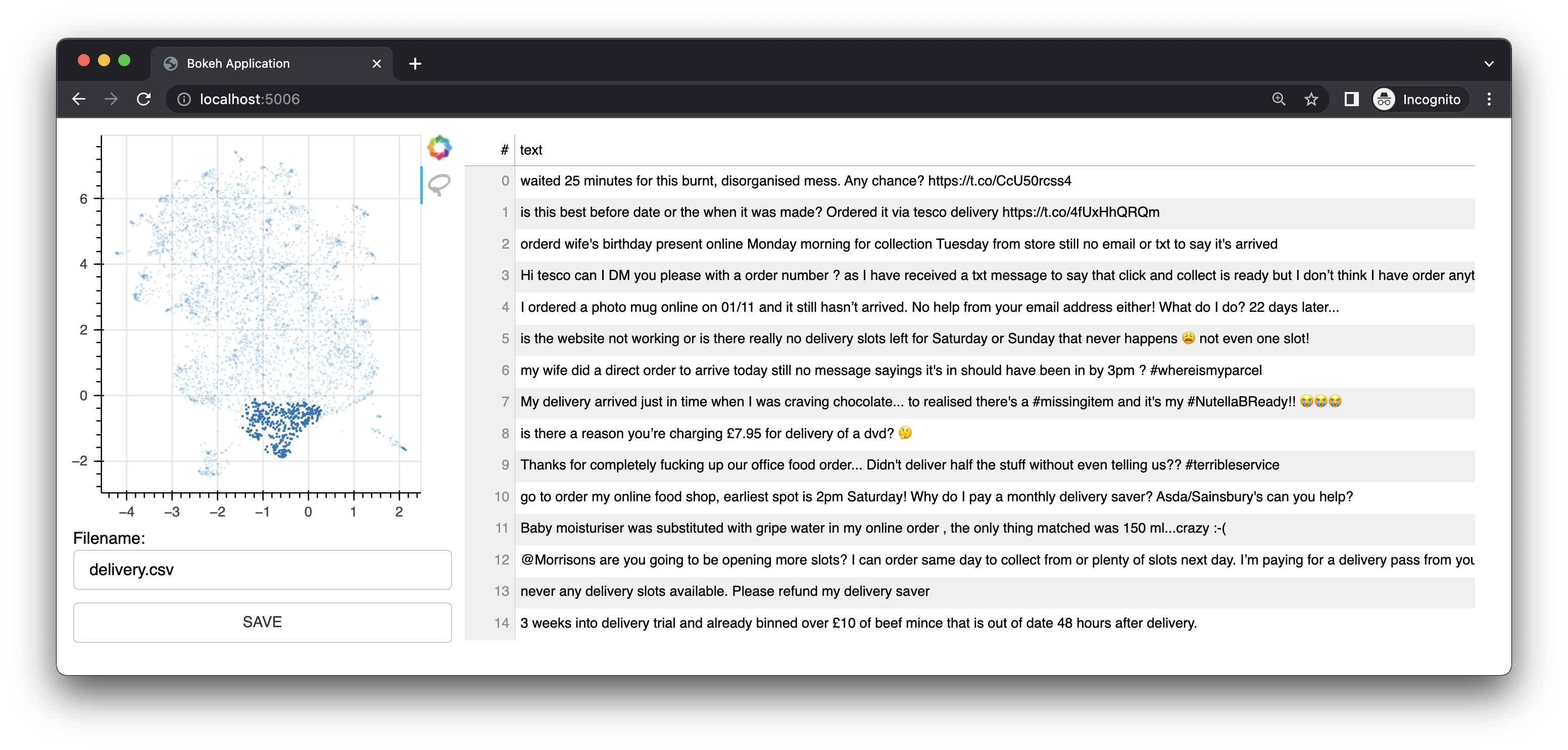
它還具有圖像介面。
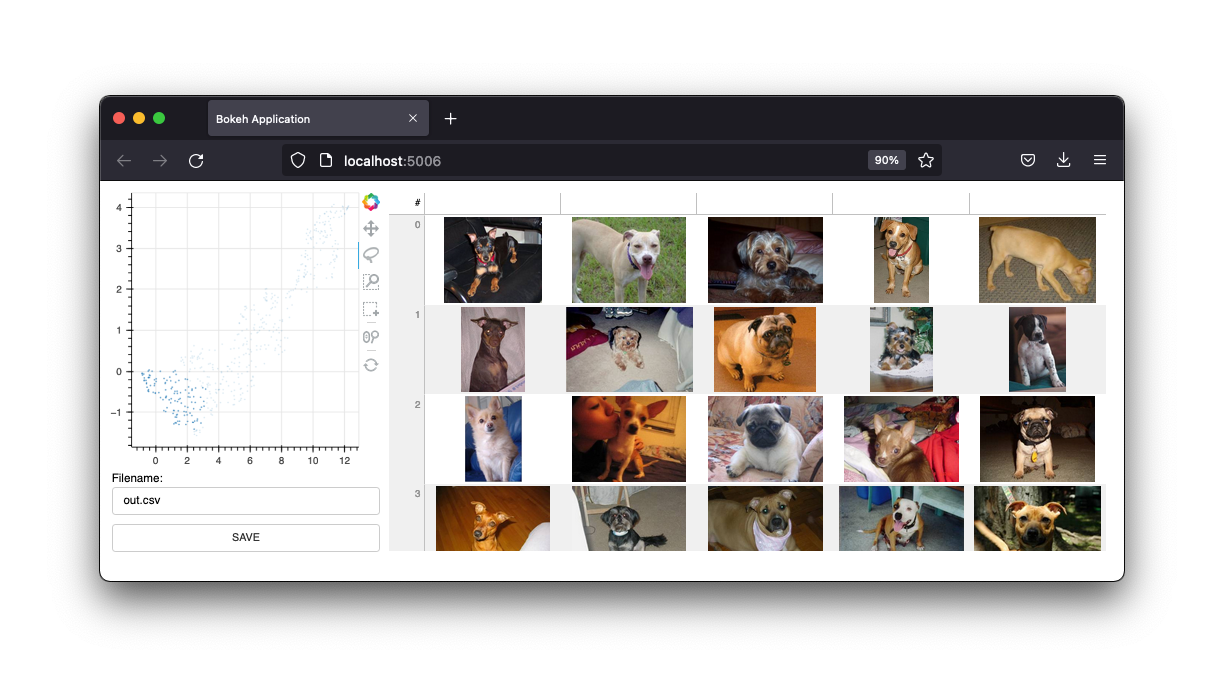
我們將保留這些介面,但該專案的未來將是來自 Jupyter 筆記本的小部件。然而,網頁應用程式當然仍然有用。
如果您想了解更多信息,您可能會喜歡 YouTube 上的這個文字影片和 YouTube 上的電腦視覺影片。
要使用批次文本,您首先需要準備一個 csv 檔案。
筆記
下面的範例使用 embetter 產生嵌入並使用 umap 來減少維度。但您可以完全自由地使用您喜歡的任何文字嵌入工具。您需要單獨安裝這些工具。請注意,embetter 在底層使用了句子轉換器。
import pandas as pd
from umap import UMAP
from sklearn . pipeline import make_pipeline
# pip install "embetter[text]"
from embetter . text import SentenceEncoder
# Build a sentence encoder pipeline with UMAP at the end.
text_emb_pipeline = make_pipeline (
SentenceEncoder ( 'all-MiniLM-L6-v2' ),
UMAP ()
)
# Load sentences
sentences = list ( pd . read_csv ( "original.csv" )[ 'sentences' ])
# Calculate embeddings
X_tfm = text_emb_pipeline . fit_transform ( sentences )
# Write to disk. Note! Text column must be named "text"
df = pd . DataFrame ({ "text" : sentences })
df [ 'x' ] = X_tfm [:, 0 ]
df [ 'y' ] = X_tfm [:, 1 ]
df . to_csv ( "ready.csv" , index = False )現在您可以使用此ready.csv檔案來套用一些批次標籤。
python -m bulk text ready.csv
如果您正在尋找範例檔案來使用,可以下載此儲存庫中的示範 .csv 檔案。該資料集包含 Kaggle 上找到的資料集的子集。您可以在這裡找到原件。
您也可以將一個名為「顏色」的額外欄位傳遞到 csv 檔案。然後,該列將用於為介面中的點著色。
您也可以將--keywords傳遞給命令列應用程式以反白包含特定關鍵字的元素。
python -m bulk text ready.csv --keywords "deliver,card,website,compliment"
下面的範例使用embetter庫建立批次標記影像的資料集。
筆記
下面的範例使用 embetter 產生嵌入並使用 umap 來減少維度。但您可以完全自由地使用您喜歡的任何文字嵌入工具。您需要單獨安裝這些工具。請注意,embetter 在底層使用 TIMM。
import pathlib
import pandas as pd
from sklearn . pipeline import make_pipeline
from umap import UMAP
from sklearn . preprocessing import MinMaxScaler
# pip install "embetter[vision]"
from embetter . grab import ColumnGrabber
from embetter . vision import ImageLoader , TimmEncoder
# Build image encoding pipeline
image_emb_pipeline = make_pipeline (
ColumnGrabber ( "path" ),
ImageLoader ( convert = "RGB" ),
TimmEncoder ( 'xception' ),
UMAP (),
MinMaxScaler ()
)
# Make dataframe with image paths
img_paths = list ( pathlib . Path ( "downloads" , "pets" ). glob ( "*" ))
dataf = pd . DataFrame ({
"path" : [ str ( p ) for p in img_paths ]
})
# Make csv file with Umap'ed model layer
# Note! Bulk assumes the image path column to be called "path"!
X = image_emb_pipeline . fit_transform ( dataf )
dataf [ 'x' ] = X [:, 0 ]
dataf [ 'y' ] = X [:, 1 ]
dataf . to_csv ( "ready.csv" , index = False )這會產生一個 csv 文件,可以透過以下方式批次載入:
python -m bulk image ready.csv
您也可以為影像產生一組縮圖。如果您正在處理大型資料集,這可能很有用。
python -m bulk util resize ready.csv ready2.csv temp
這將建立一個名為temp的資料夾,其中包含所有調整大小的圖片。然後,您可以使用該資料夾作為--thumbnail-path參數。
python -m bulk image ready2.csv --thumbnail-path temp
您也可以使用批量下載一些資料集來使用。欲了解更多資訊:
python -m bulk download --help
這個介面可以幫助您非常快速地添加標籤,但標籤本身可能相當嘈雜。該工具的預期用例是準備稍後在 prodi.gy 中使用的有趣子集。


