MedCalc Bench
1.0.0
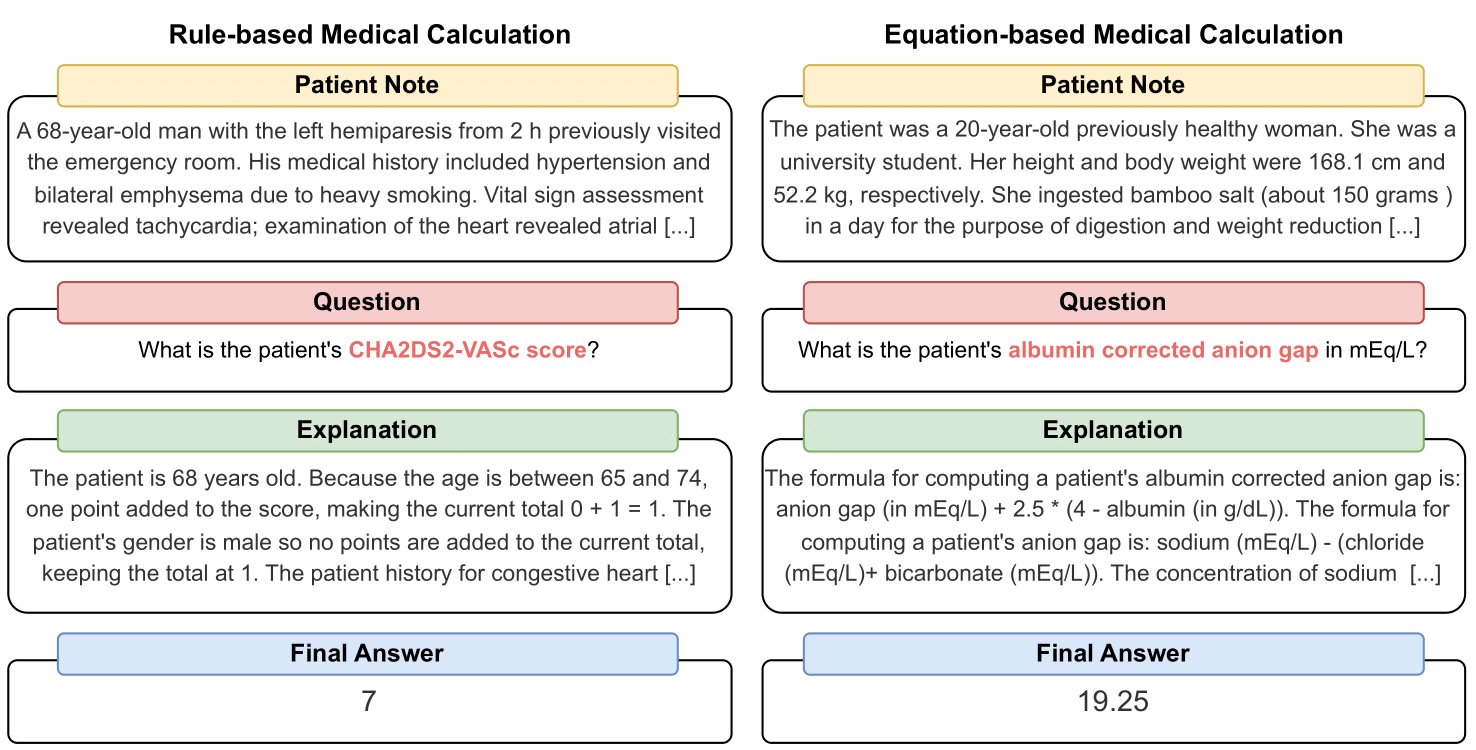
MedCalc-Bench 是第一個醫學計算數據集,用於衡量法學碩士作為臨床計算器的能力。資料集中的每個實例都包含患者註釋、要求計算特定臨床值的問題、最終答案值以及解釋如何獲得最終答案的逐步解決方案。我們的資料集涵蓋 55 種不同的計算任務,這些任務要麼是基於規則的計算,要麼是基於方程式的計算。此資料集包含 10,053 個實例的訓練資料集和 1,047 個實例的測試資料集。
總而言之,我們希望我們的資料集和基準能提高醫療環境中法學碩士的計算推理技能。
我們的預印本可在以下網址取得:https://arxiv.org/abs/2406.12036。
若要下載 MedCalc-Bench 評估資料集的 CSV,請下載此儲存庫的dataset資料夾內的檔案test_data.csv 。您也可以從 HuggingFace 下載測試集拆分:https://huggingface.co/datasets/ncbi/MedCalc-Bench。
除了 1,047 個評估實例之外,我們還提供了包含 10,053 個實例的訓練資料集,可用於微調開源 LLM(請參閱附錄 C 部分)。訓練資料可以在dataset/train_data.csv.zip檔中找到,可以解壓縮得到train_data.csv 。此訓練資料集也可以在 HuggingFace 連結的訓練分割中找到。
資料集中的每個實例包含以下資訊:
若要安裝專案所需的所有軟體包,請執行以下命令: conda env create -f environment.yml 。此指令將建立medcalc-bench conda 環境。為了運行 OpenAI 模型,您需要在此 conda 環境中提供 OpenAI 金鑰。您可以透過在medcalc-bench環境中執行以下命令來完成此操作: export OPENAI_API_KEY = YOUR_API_KEY ,其中 YOUR_API_KEY 是您的 OpenAI API 金鑰。您還需要透過執行以下命令在此環境中提供 HuggingFace 令牌: export HUGGINGFACE_TOKEN=your_hugging_face_token ,其中your_hugging_face_token是您的 HuggingFace 令牌。
為了從論文中複製表 2,首先將cd放入evaluation資料夾中。然後,請執行下列指令: python run.py --model <model_name> and --prompt <prompt_style> 。
--model的選項如下:
--prompt的選項如下:
由此,您將獲得一個輸出每個問題狀態的 jsonl 檔案:執行run.py時,結果將保存在名為<model>_<prompt>.jsonl的檔案中。該文件可以在outputs資料夾中找到。
jsonl 中的每個實例都將具有以下與其關聯的元資料:
{
"Row Number": Row index of the item,
"Calculator Name": Name of calculation task,
"Calculator ID": ID of the calculator,
"Category": type of calculation (risk, severity, diagnosis for rule-based calculators and lab, risk, physical, date, dosage for equation-based calculators),
"Note ID": ID of the note taken directly from MedCalc-Bench,
"Patient Note": Paragraph which is the patient note taken directly from MedCalc-Bench,
"Question": Question asking for a specific medical value to be computed,
"LLM Answer": Final Answer Value from LLM,
"LLM Explanation": Step-by-Step explanation by LLM,
"Ground Truth Answer": Ground truth answer value,
"Ground Truth Explanation": Step-by-step ground truth explanation,
"Result": "Correct" or "Incorrect"
}
此外,我們在標題為results_<model>_<prompt_style>.json json 中提供每個子類別的平均準確度和標準差百分比。所有 1,047 個實例的累積精度和標準差可以在 JSON 的“overall”鍵下找到。該文件可以在results資料夾中找到。
除了主論文中表 2 的結果之外,我們還提示法學碩士編寫程式碼來執行算術運算,而不是讓法學碩士自己執行此操作。結果可以在附錄 D 中找到。若要檢查提示並在此設定下執行,請檢查evaluation資料夾中的generate_code_prompt.py檔案。
要運行此程式碼,只需cd進入evaluations資料夾並執行以下命令: python generate_code_prompt.py --gpt <gpt_model> 。 <gpt_model>的選項是4 (運行 GPT-4)或35 (運行 GPT-3.5-turbo-16k)。然後,結果將保存在outputs資料夾中名稱為: code_exec_{model_name}.jsonl的 jsonl 檔案中。請注意,在這種情況下,如果您選擇使用 GPT-4 運行,則model_name將為gpt_4 。否則,如果您選擇使用 GPT-3.5-turbo 運行,則model_name將為gpt_35_16k 。
程式碼解釋器結果的 jsonl 檔案中每個實例的元資料與上一節提供的實例資訊相同。唯一的區別是我們儲存了用戶和助理之間的LLM聊天歷史記錄,並且有一個「LLM聊天歷史記錄」鍵而不是「LLM解釋」鍵。此外,子類別和整體準確性儲存在名為results_<model_name>_code_augmented.json的 JSON 檔案中。此 JSON 位於results資料夾中。
這項研究得到了 NIH 校內研究計畫、國家醫學圖書館的支持。此外,Soren Dunn 的貢獻是使用 Delta 先進計算和數據資源完成的,該資源得到國家科學基金會(授予 OAC 電話:2005572)和伊利諾伊州的支持。 Delta 是伊利諾大學厄巴納-香檳分校 (UIUC) 及其國家超級電腦應用中心 (NCSA) 的共同努力。
為了在 MedCalc-Bench 中整理患者筆記,我們僅使用 PubMed Central 中已發表的病例報告文章中公開的患者筆記以及臨床醫生生成的匿名患者插圖。因此,本研究中並未透露可識別的個人健康資訊。雖然 MedCalc-Bench 旨在評估法學碩士的醫學計算能力,但應注意的是,該數據集不適用於未經臨床專業人員審查和監督的直接診斷用途或醫療決策。個人不應僅根據我們的研究來改變他們的健康行為。
如第 1 節所述,醫療計算器常用於臨床環境。隨著人們對將 LLM 用於特定領域應用程式的興趣迅速增長,醫療保健從業者可能會直接提示 ChatGPT 等聊天機器人執行醫療運算任務。然而,法學碩士在這些任務中的能力目前尚不清楚。由於醫療保健是一個高風險領域,錯誤的醫學計算可能會導致嚴重後果,包括誤診、不適當的治療計劃以及對患者的潛在傷害,因此徹底評估法學碩士在醫學計算中的表現至關重要。令人驚訝的是,我們的 MedCalc-Bench 數據集的評估結果表明,所有研究的法學碩士都在醫學計算任務中陷入困境。最強大的模型 GPT-4 透過一次性學習和思維鏈提示僅達到 50% 的準確率。因此,我們的研究表明,目前的法學碩士尚未準備好用於醫學計算。應該指出的是,雖然 MedCalc-Bench 上的高分並不能保證在醫學計算任務中表現出色,但在此資料集中的失敗表明根本不能考慮將模型用於此類目的。換句話說,我們認為透過 MedCalc-Bench 應該是模型用於醫學計算的必要(但不是充分)條件
對於此資料集的任何變更(即新增註解或計算器),我們將更新 README 說明、test_set.csv 和 train_set.csv。我們仍將這些資料集的舊版本保留在archive/資料夾中。我們也將更新 HuggingFace 的訓練集和測試集。
該工具顯示了 NCBI/NLM 計算生物學分支進行的研究結果。本網站產生的資訊不用於未經臨床專業人員審查和監督的直接診斷用途或醫療決策。個人不應僅根據本網站提供的資訊來改變其健康行為。 NIH 不會獨立驗證該工具產生的資訊的有效性或實用性。如果您對本網站上提供的資訊有疑問,請諮詢醫療保健專業人員。我們提供了有關 NCBI 免責聲明政策的更多資訊。
根據計算器的不同,我們的資料集包含的註解要么是根據 Python 中實現的基於模板的函數設計的,由臨床醫生手寫,要么取自我們的資料集 Open-Patients。
Open-Patients 是來自三個不同來源的 18 萬患者筆記的聚合資料集。我們有權使用所有三個來源的資料集。第一個來源是來自 MedQA 的 USMLE 問題,該問題是根據 MIT 許可證發布的。我們資料集的第二個來源是 Trec Clinical Decision Support 和 Trec Clinical Trial,它們可以重新分發,因為它們都是向公眾發布的政府擁有的資料集。最後,PMC-Patients 是在 CC-BY-SA 4.0 授權下發布的,因此我們有權將 PMC-Patients 合併到 Open-Patients 和 MedCalc-Bench 中,但資料集必須在相同的授權下發布。因此,我們的筆記來源 Open-Patients 以及從中整理的資料集 MedCalc-Bench 均在 CC-BY-SA 4.0 許可下發布。
基於授權規則的合理性,Open-Patents和MedCalc-Bench均遵守CC-BY-SA 4.0許可,但本文作者將承擔侵權的所有責任。
@misc { khandekar2024medcalcbench ,
title = { MedCalc-Bench: Evaluating Large Language Models for Medical Calculations } ,
author = { Nikhil Khandekar and Qiao Jin and Guangzhi Xiong and Soren Dunn and Serina S Applebaum and Zain Anwar and Maame Sarfo-Gyamfi and Conrad W Safranek and Abid A Anwar and Andrew Zhang and Aidan Gilson and Maxwell B Singer and Amisha Dave and Andrew Taylor and Aidong Zhang and Qingyu Chen and Zhiyong Lu } ,
year = { 2024 } ,
eprint = { 2406.12036 } ,
archivePrefix = { arXiv } ,
primaryClass = { id='cs.CL' full_name='Computation and Language' is_active=True alt_name='cmp-lg' in_archive='cs' is_general=False description='Covers natural language processing. Roughly includes material in ACM Subject Class I.2.7. Note that work on artificial languages (programming languages, logics, formal systems) that does not explicitly address natural-language issues broadly construed (natural-language processing, computational linguistics, speech, text retrieval, etc.) is not appropriate for this area.' }
}

