CQN
1.0.0
重新實現從粗到細的 Q 網路 (CQN) ,這是一種用於連續控制的基於樣本高效值的 RL 演算法,引入於:
透過從粗到細的強化學習進行連續控制
Younggyo Seo、賈法爾·烏魯克、史蒂芬·詹姆斯
我們的關鍵思想是學習以從粗到細的方式放大連續動作空間的強化學習智能體,使我們能夠訓練基於價值的強化學習智能體進行連續控制,並且在每個級別上只需要很少的離散動作。
請參閱我們的專案網頁 https://younggyo.me/cqn/ 以了解更多資訊。
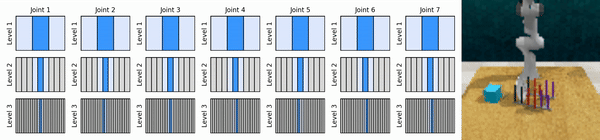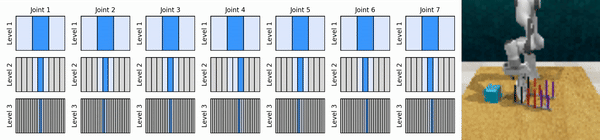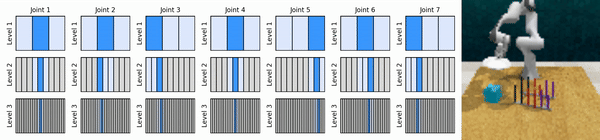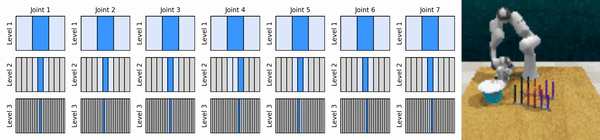
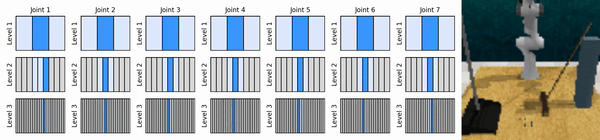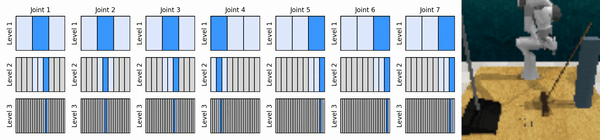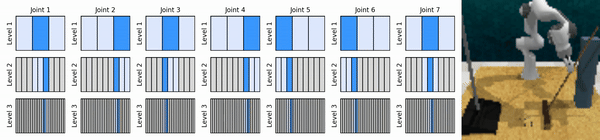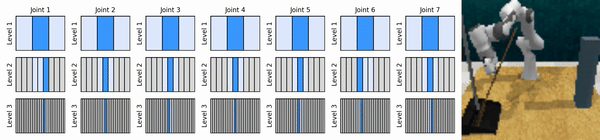
安裝conda環境:
conda env create -f conda_env.yml
conda activate cqn
安裝 RLBench 和 PyRep(應使用 2024 年 7 月 10 日的最新版本)。請依照原始儲存庫中的指南進行 (1) 安裝 RLBench 和 PyRep 以及 (2) 啟用無頭模式。 (有關安裝 RLBench 的信息,請參閱 RLBench 和 Robobase 中的自述文件。)
git clone https://github.com/stepjam/RLBench
git clone https://github.com/stepjam/PyRep
# Install PyRep
cd PyRep
git checkout 8f420be8064b1970aae18a9cfbc978dfb15747ef
pip install .
# Install RLBench
cd RLBench
git checkout b80e51feb3694d9959cb8c0408cd385001b01382
pip install .
預收集演示
cd RLBench/rlbench
CUDA_VISIBLE_DEVICES=0 DISPLAY=:0.0 python dataset_generator.py --save_path=/your/own/directory --image_size 84 84 --renderer opengl3 --episodes_per_task 100 --variations 1 --processes 1 --tasks take_lid_off_saucepan --arm_max_velocity 2.0 --arm_max_acceleration 8.0
運行實驗 (CQN):
CUDA_VISIBLE_DEVICES=0 DISPLAY=:0.0 python train_rlbench.py rlbench_task=take_lid_off_saucepan num_demos=100 dataset_root=/your/own/directory
執行基線實驗 (DrQv2+):
CUDA_VISIBLE_DEVICES=0 DISPLAY=:0.0 python train_rlbench_drqv2plus.py rlbench_task=take_lid_off_saucepan num_demos=100 dataset_root=/your/own/directory
運行實驗:
CUDA_VISIBLE_DEVICES=0 python train_dmc.py dmc_task=cartpole_swingup
警告:CQN 未在 DMC 中進行廣泛測試
此儲存庫基於 DrQ-v2 的公共實現
@article{seo2024continuous,
title={Continuous Control with Coarse-to-fine Reinforcement Learning},
author={Seo, Younggyo and Uru{c{c}}, Jafar and James, Stephen},
journal={arXiv preprint arXiv:2407.07787},
year={2024}
}


