lorax
v0.12.0: Multi-LoRA prefix caching, fp8 kv cache, Mllama, function calling

LoRAX:多 LoRA 推理伺服器,可擴充至 1000 個經過微調的 LLM
LoRAX (LoRA eXchange) 是一個框架,允許使用者在單一 GPU 上為數千個微調模型提供服務,從而在不影響吞吐量或延遲的情況下大幅降低服務成本。
目錄
特徵
型號
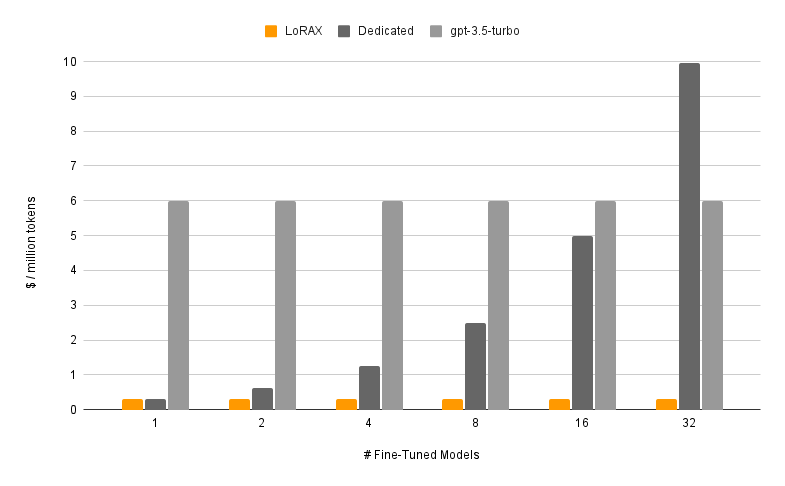
?
要求
啟動 LoRAX 伺服器
透過 REST API 提示
透過Python客戶端提示
透過 OpenAI API 聊天
後續步驟
致謝
路線圖
動態適配器載入:在您的請求中包含來自 HuggingFace、Predibase 或任何檔案系統的任何微調 LoRA 適配器,它將及時加載,而不會阻塞並發請求。根據請求合併適配器以立即建立強大的整體。
異質連續批次:將對不同適配器的請求打包到同一個批次中,使延遲和吞吐量與並發適配器的數量幾乎保持恆定。
適配器交換調度:在 GPU 和 CPU 記憶體之間非同步預取和卸載適配器,調度請求批次以優化系統的總吞吐量。
最佳化推理:高吞吐量和低延遲最佳化,包括張量並行性、預編譯 CUDA 核心(快閃注意力、分頁注意力、SGMV)、量化、代幣流。
為生產做好準備的預先建置 Docker 映像、Kubernetes 的 Helm 圖表、Prometheus 指標以及使用 Open Telemetry 的分散式追蹤。 OpenAI相容API支援多輪聊天對話。透過每個請求租戶隔離的私有適配器。結構化輸出(JSON 模式)。
?免費用於商業用途: Apache 2.0 許可證。說夠了?
使用 LoRAX 提供微調模型由兩個部分組成:
基本模型:所有適配器共享的預訓練大型模型。
適配器:根據請求動態載入特定於任務的適配器權重。
LoRAX 支援多種大型語言模型作為基礎模型,包括 Llama(包括 CodeLlama)、Mistral(包括 Zephyr)和 Qwen。有關支援的基本模型的完整列表,請參閱支援的架構。
基本模型可以以 fp16 加載,也可以使用bitsandbytes 、GPT-Q 或 AWQ 進行量化。
支援的適配器包括使用 PEFT 和 Ludwig 庫訓練的 LoRA 適配器。模型中的任何線性層都可以透過 LoRA 進行調整並載入到 LoRAX 中。
我們建議從預先建置的 Docker 映像開始,以避免編譯自訂 CUDA 核心和其他相依性。
運行 LoRAX 所需的最低系統需求包括:
Nvidia GPU(安培世代或以上)
CUDA 11.8 相容裝置驅動程式以上版本
Linux作業系統
Docker(對於本指南)
安裝 nvidia-container-toolkit 然後
sudo systemctl daemon-reload
sudo systemctl restart docker
型號=mistralai/Mistral-7B-Instruct-v0.1
卷=$PWD/數據
docker run --gpus all --shm-size 1g -p 8080:80 -v $volume:/data
ghcr.io/predibase/lorax:main --model-id $model有關包括令牌流和 Python 客戶端的完整教程,請參閱入門 - Docker。
提示基礎法學碩士:
捲曲 127.0.0.1:8080/生成
-X 後
-d '{ "inputs": "[INST] Natalia 在4 月向她的48 個朋友出售了剪輯,然後她在5 月份出售了一半的剪輯。Natalia 在4 月和5 月總共出售了多少個剪輯?
-H '內容類型:application/json'提示LoRA適配器:
捲曲 127.0.0.1:8080/生成
-X 後
-d '{ "inputs": "[INST] Natalia 在4 月向她的48 個朋友出售了剪輯,然後她在5 月份出售了一半的剪輯。Natalia 在4 月和5 月總共出售了多少個剪輯?
-H '內容類型:application/json'有關完整詳細信息,請參閱參考 - REST API。
安裝:
pip 安裝 lorax 用戶端
跑步:
from lorax import Clientclient = Client("http://127.0.0.1:8080")# 提示基本LLMprompt = "[INST] Natalia 在4 月份向她的48 個朋友出售了剪輯,然後她在5 月份出售了一半的剪輯.Natalia 在4 月和5 月總共銷售了多少個剪輯? Mistral-7B- Instruct-v0.1-gsm8k"print(client.generate(提示,max_new_tokens=64,adapter_id=adapter_id). generated_text)有關完整詳細信息,請參閱參考 - Python 客戶端。
有關運行 LoRAX 的其他方式,請參閱入門 - Kubernetes、入門 - SkyPilot 和入門 - 本地。
LoRAX 支援多輪聊天對話,並透過 OpenAI 相容 API 結合動態適配器載入。只需指定任何適配器作為model參數即可。
從 openai 導入 OpenAIclient = OpenAI(api_key="EMPTY",base_url="http://127.0.0.1:8080/v1",
)resp = client.chat.completions.create(model="alignment-handbook/zephyr-7b-dpo-lora",messages=[
{"role": "system","content": "你是個友善的聊天機器人,總是以海盜的風格回應",
},
{"role": "user", "content": "一個人一次可以吃多少架直升機?"},
],max_tokens=100,
)print("回應:", resp.choices[0].message.content)詳情請參閱 OpenAI 相容 API。
以下是一些其他有趣的 Mistral-7B 微調模型可供嘗試:
alignment-handbook/zephyr-7b-dpo-lora:Mistral-7b 使用 DPO 在 Zephyr-7B 資料集上進行了微調。
IlyaGusev/saiga_mistral_7b_lora:基於Open-Orca/Mistral-7B-OpenOrca的俄羅斯聊天機器人。
Undi95/Mistral-7B-roleplay_alpaca-lora:使用角色扮演提示進行微調。
您可以在此處找到更多 LoRA 轉接器,或嘗試使用 PEFT 或 Ludwig 微調您自己的轉接器。
LoRAX 建構於 HuggingFace 的文本生成推理之上,該推理源自於 v0.9.4 (Apache 2.0)。
我們也要感謝 Punica 在 SGMV 核心方面所做的工作,該核心用於加速重負載下的多適配器推理。
我們的路線圖在這裡追蹤。


