SOLIDER
1.0.0

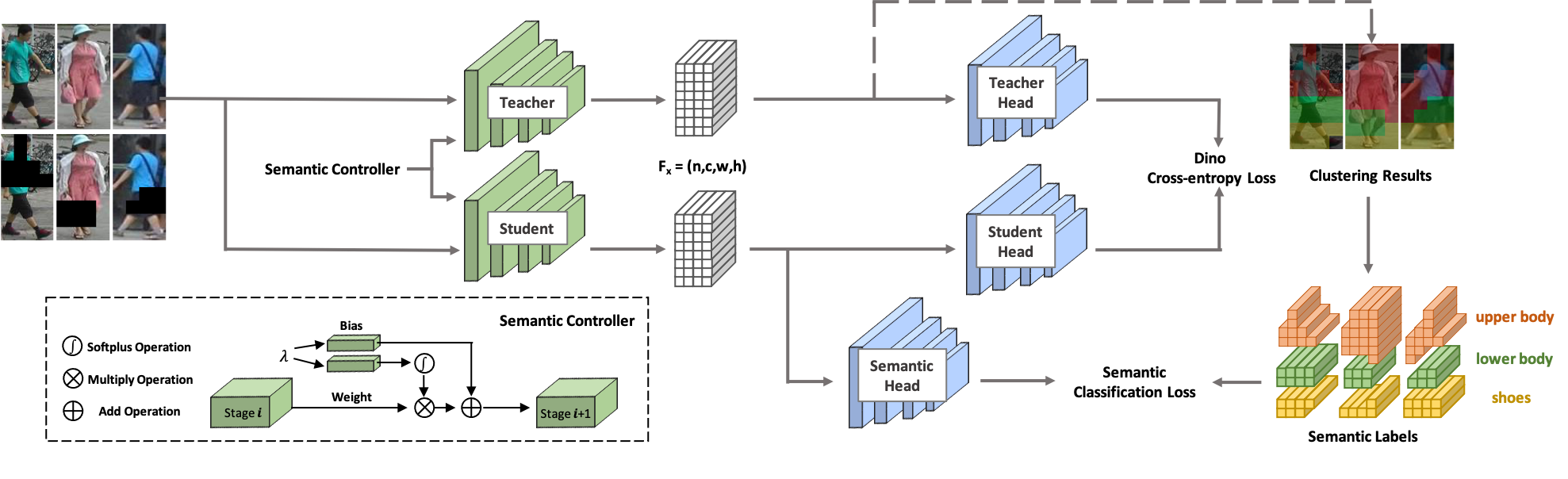
歡迎來到士兵! SOLIDER 是一個語義可控的自我監督學習框架,用於從大量未標記的人類圖像中學習一般人類表示,這可以最大程度地有利於下游以人類為中心的任務。與現有的自我監督學習方法不同,SOLIDER 利用人類圖像的先驗知識來建立偽語義標籤,並將更多語義資訊導入到學習的表示中。同時,不同的下游任務總是需要不同比例的語義資訊和外觀訊息,並且單一的學習表示無法滿足所有要求。為了解決這個問題,SOLIDER引入了具有語義控制器的條件網絡,可以適應下游任務的不同需求。欲了解更多詳細信息,請參閱我們的論文《Beyond Appearance: a Semantic Controllable Self-Supervised Learning Framework for Human-Centric Visual Tasks》。
程式碼庫是使用 python 版本 3.7、PyTorch 版本 1.7.1、CUDA 10.1 和 torchvision 0.8.2 開發的。
我們使用LUPerson作為訓練數據,其中包含未標記的人類圖像。從官方連結下載LUPerson並解壓縮。
sh run_solider.shsh run_dino.sh
sh resume_solider.sh有一個演示可以運行經過訓練的 SOLIDER 模型,可以將其嵌入到推理或下游任務微調中。
python demo.py我們使用 Swin-Transformer 作為主幹,它在許多 CV 任務上顯示出巨大的優勢。
| 任務 | 數據集 | 斯文小 (關聯) | 斯溫小號 (關聯) | 斯溫基地 (關聯) |
|---|---|---|---|---|
| 人員重新識別 (mAP/R1) 無需重新排名 | 市場1501 | 91.6/96.1 | 93.3/96.6 | 93.9/96.9 |
| MSMT17 | 67.4/85.9 | 76.9/90.8 | 77.1/90.7 | |
| 人員重新識別 (mAP/R1) 重新排名 | 市場1501 | 95.3/96.6 | 95.4/96.4 | 95.6/96.7 |
| MSMT17 | 81.5/89.2 | 86.5/91.7 | 86.5/91.7 | |
| 屬性識別(mA) | PETA_ZS | 74.37 | 76.21 | 76.43 |
| RAP_ZS | 74.23 | 75.95 | 76.42 | |
| PA100K | 84.14 | 86.25 | 86.37 | |
| 人員搜尋 (mAP/R1) | 香港中文大學-中山大學 | 94.9/95.7 | 95.5/95.8 | 94.9/95.5 |
| PRW | 56.8/86.8 | 59.8/86.7 | 59.7/86.8 | |
| 行人偵測 (MR-2) | 城市人 | 10.3/40.8 | 10.0/39.2 | 9.7/39.4 |
| 人體解析 (mIOU) | 唇 | 57.52 | 60.21 | 60.50 |
| 姿態估計(AP/AR) | 可可 | 74.4/79.6 | 76.3/81.3 | 76.6/81.5 |
我們的實作主要基於以下程式碼庫。我們衷心感謝作者的精彩作品。
如果您在研究中使用 SOLIDER,請使用以下 BibTeX 條目引用我們的工作:
@inproceedings{chen2023beyond,
title={Beyond Appearance: a Semantic Controllable Self-Supervised Learning Framework for Human-Centric Visual Tasks},
author={Weihua Chen and Xianzhe Xu and Jian Jia and Hao Luo and Yaohua Wang and Fan Wang and Rong Jin and Xiuyu Sun},
booktitle={The IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2023},
}


